







linux混混之牢骚:
可怜的安阳的,你承担和温州一样的故事,却引不起老温的注意……悲哀啊,故乡。。。
2.1 linux内存管理基本框架
linux中的分段分页机制分三层,页目录(PGD),中间目录(PMD),页表(PT)。PT中的表项称为页表项(PTE)。注意英文缩写,在linux程序中函数变量的名字等都会和英文缩写相关。
LINUX中的三级映射流程如图:
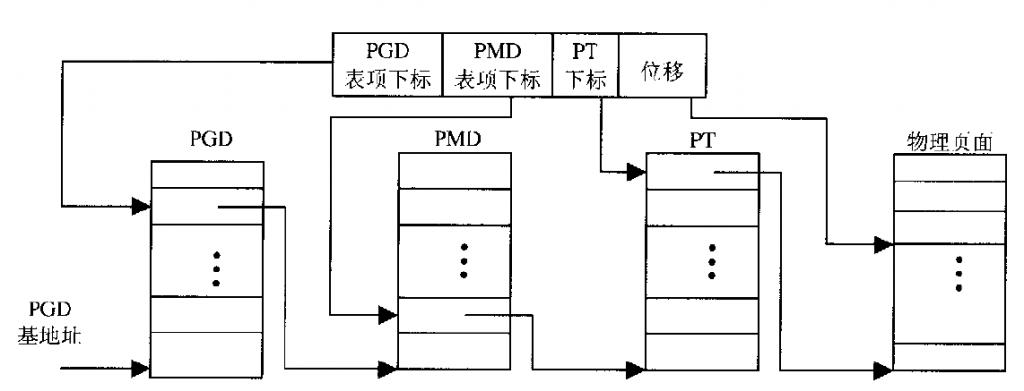
但是arm结构的MMU在硬件只有2级映射,所以在软件上会跳过PMD表。即:在PGD中直接放的是PT的base address。在linux软件上就是:
- #define PMD_SHIFT 21
- #define PGDIR_SHIFT 21 //让PMD_SHIFT 和 PGDIR_SHIFT 相等就可以了。
新的2.6内核和内核源码情景分析上的差别挺大的,在2.6.11版本以后,linux将软件上的3级映射变成了4级映射,在PMD后面增加了一个PUD(page upper directory). 在arm的两级映射中,跳过PMD和PUD
在2.6.39内核arch/arm/include/asm/pgtable.h中有下代码:
- /*
- * Hardware-wise, we have a two level page table structure, where the first
- * level has 4096 entries, and the second level has 256 entries. Each entry
- * is one 32-bit word. Most of the bits in the second level entry are used
- * by hardware, and there aren't any "accessed" and "dirty" bits.
- *
- * Linux on the other hand has a three level page table structure, which can
- * be wrapped to fit a two level page table structure easily - using the PGD
- * and PTE only. However, Linux also expects one "PTE" table per page, and
- * at least a "dirty" bit.
- *
- * Therefore, we tweak the implementation slightly - we tell Linux that we
- * have 2048 entries in the first level, each of which is 8 bytes (iow, two
- * hardware pointers to the second level.) The second level contains two
- * hardware PTE tables arranged contiguously, preceded by Linux versions
- * which contain the state information Linux needs. We, therefore, end up
- * with 512 entries in the "PTE" level.
- *
- * This leads to the page tables having the following layout:
- *
- * pgd pte
- * | |
- * +--------+
- * | | +------------+ +0
- * +- - - - + | Linux pt 0 |
- * | | +------------+ +1024
- * +--------+ +0 | Linux pt 1 |
- * | |-----> +------------+ +2048
- * +- - - - + +4 | h/w pt 0 |
- * | |-----> +------------+ +3072
- * +--------+ +8 | h/w pt 1 |
- * | | +------------+ +4096
- *
- * See L_PTE_xxx below for definitions of bits in the "Linux pt", and
- * PTE_xxx for definitions of bits appearing in the "h/w pt".
- *
- * PMD_xxx definitions refer to bits in the first level page table.
- *
- * The "dirty" bit is emulated by only granting hardware write permission
- * iff the page is marked "writable" and "dirty" in the Linux PTE. This
- * means that a write to a clean page will cause a permission fault, and
- * the Linux MM layer will mark the page dirty via handle_pte_fault().
- * For the hardware to notice the permission change, the TLB entry must
- * be flushed, and ptep_set_access_flags() does that for us.
- *
- * The "accessed" or "young" bit is emulated by a similar method; we only
- * allow accesses to the page if the "young" bit is set. Accesses to the
- * page will cause a fault, and handle_pte_fault() will set the young bit
- * for us as long as the page is marked present in the corresponding Linux
- * PTE entry. Again, ptep_set_access_flags() will ensure that the TLB is
- * up to date.
- *
- * However, when the "young" bit is cleared, we deny access to the page
- * by clearing the hardware PTE. Currently Linux does not flush the TLB
- * for us in this case, which means the TLB will retain the transation
- * until either the TLB entry is evicted under pressure, or a context
- * switch which changes the user space mapping occurs.
- */
- <p>#define PTRS_PER_PTE 512 //PTE的个数
- #define PTRS_PER_PMD 1
- #define PTRS_PER_PGD 2048</p><p>#define PTE_HWTABLE_PTRS (PTRS_PER_PTE)
- #define PTE_HWTABLE_OFF (PTE_HWTABLE_PTRS * sizeof(pte_t))
- #define PTE_HWTABLE_SIZE (PTRS_PER_PTE * sizeof(u32))</p><p>/*
- * PMD_SHIFT determines the size of the area a second-level page table can map
- * PGDIR_SHIFT determines what a third-level page table entry can map
- */
- #define PMD_SHIFT 21
- #define PGDIR_SHIFT 21 //另PMD和PDGIR相等,来跳过PMD。</p>
/*linux将PGD为2k,每项为8个byte。(MMU中取值为前高12bit,为4k,每项4个byte,但linux为什么要这样做呢?) ,另外linux在定义pte时,定义了两个pte,一个供MMU使用,一个供linux使用,来用描述这个页。
*根据注释中的表图,我看到有 #define PTRS_PER_PTE 512 #define PTRS_PER_PGD 2048 , linux将PDG定义为2K,8byte,每个pte项为512,4byte。 他将 两个pte项进行了一下合并。为什么?为什么?
**/
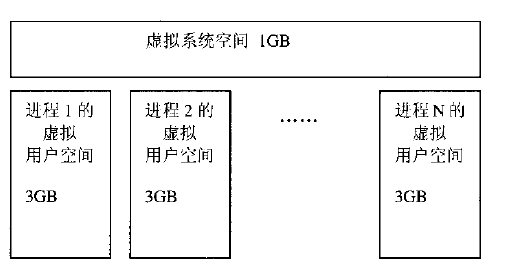
在进程中,传说是可以看到4G的空间,按照linux的用户空间和内核空间划分。 其实进程可以看到3G的自己进程的空间,3G-4G的空间是内核空间,进程仅能通过系统调用进入。
2.2地址映射全过程
将x86的段地址,略。。。
2.3几个重要的数据结构和函数
PGD,PTE的值定义:
- /*
- * These are used to make use of C type-checking..
- */
- typedef struct { pteval_t pte; } pte_t;
- typedef struct { unsigned long pmd; } pmd_t;
- typedef struct { unsigned long pgd[2]; } pgd_t; //定义一个[2]数组,这样就和上面的介绍对应起来了,每个PGD是一个8个byte的值(即两个long型数)。
- typedef struct { unsigned long pgprot; } pgprot_t;
这几个结构体定义PTE等他们的结构, pgprot_t 是page protect的意思,最上面的图可知,在具体映射时候,需要将PTE表中的高20bit的值 + 线性地址的低 12bit的值 才是具体的物理地址。所以PTE只有高20bit是在地址映射映射时有效的,那么他的低12bit用来放一些protect的数据,如writeable,rdonly......下面是pgprot_t的一些值:
- #define __PAGE_NONE __pgprot(_L_PTE_DEFAULT | L_PTE_RDONLY | L_PTE_XN)
- #define __PAGE_SHARED __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_XN)
- #define __PAGE_SHARED_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER)
- #define __PAGE_COPY __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY | L_PTE_XN)
- #define __PAGE_COPY_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY)
- #define __PAGE_READONLY __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY | L_PTE_XN)
- #define __PAGE_READONLY_EXEC __pgprot(_L_PTE_DEFAULT | L_PTE_USER | L_PTE_RDONLY)
所以当我们想做一个PTE时(即生成一个page的pte),调用下列函数:
- #define mk_pte(page,prot) pfn_pte(page_to_pfn(page), prot)
这个函数即是 page_to_pfn(page)得到高20bit的值 + prot的值。 prot即为pgprot_t的结构型值,低12bit。表示页的属性。
生成这一个pte后,我们要让这个pte生效,就要在将这个值 赋值到对应的地方去。
set_pte(pteptr,pteval): 但是在2.6.39没有找到这个代码,过程应该差不多了,算了·····
另外,我们可以通过对PTE的低12bit设置,来让mmu判断,是否建立了映射?还是建立了映射但已经被swap出去了?
还有其他很多的函数,和宏定义,具体可以看《深入linux内核》的内存寻址这章。
这里都是说的PTE中的低12bit的, 但是在2.6.39中明显多了一个linux pt, 具体做什么用还不太清楚。但是linux在arch/arm/include/asm/pgtable.h 中由个注释
- /*
- * "Linux" PTE definitions.
- *
- * We keep two sets of PTEs - the hardware and the linux version.
- * This allows greater flexibility in the way we map the Linux bits
- * onto the hardware tables, and allows us to have YOUNG and DIRTY
- * bits.
- *
- * The PTE table pointer refers to the hardware entries; the "Linux"
- * entries are stored 1024 bytes below.
- */
应该可以看出,linux pt和PTE的低12bit是相呼应的,用来记录page的一些信息。
linux中,每个物理页都有一个对应的page结构体,组成一个数组,放在mem_map中。
- /*
- * Each physical page in the system has a struct page associated with
- * it to keep track of whatever it is we are using the page for at the
- * moment. Note that we have no way to track which tasks are using
- * a page, though if it is a pagecache page, rmap structures can tell us
- * who is mapping it.
- */
- struct page {
- unsigned long flags; /* Atomic flags, some possibly
- * updated asynchronously */
- atomic_t _count; /* Usage count, see below. */
- union {
- atomic_t _mapcount; /* Count of ptes mapped in mms,
- * to show when page is mapped
- * & limit reverse map searches.
- */
- struct { /* SLUB */
- u16 inuse;
- u16 objects;
- };
- };
- union {
- struct {
- unsigned long private; /* Mapping-private opaque data:
- * usually used for buffer_heads
- * if PagePrivate set; used for
- * swp_entry_t if PageSwapCache;
- * indicates order in the buddy
- * system if PG_buddy is set.
- */
- struct address_space *mapping; /* If low bit clear, points to
- * inode address_space, or NULL.
- * If page mapped as anonymous
- * memory, low bit is set, and
- * it points to anon_vma object:
- * see PAGE_MAPPING_ANON below.
- */
- };
- #if USE_SPLIT_PTLOCKS
- spinlock_t ptl;
- #endif
- struct kmem_cache *slab; /* SLUB: Pointer to slab */
- struct page *first_page; /* Compound tail pages */
- };
- union {
- pgoff_t index; /* Our offset within mapping. */
- void *freelist; /* SLUB: freelist req. slab lock */
- };
- struct list_head lru; /* Pageout list, eg. active_list
- * protected by zone->lru_lock !
- */
- /*
- * On machines where all RAM is mapped into kernel address space,
- * we can simply calculate the virtual address. On machines with
- * highmem some memory is mapped into kernel virtual memory
- * dynamically, so we need a place to store that address.
- * Note that this field could be 16 bits on x86 ... ;)
- *
- * Architectures with slow multiplication can define
- * WANT_PAGE_VIRTUAL in asm/page.h
- */
- #if defined(WANT_PAGE_VIRTUAL)
- void *virtual; /* Kernel virtual address (NULL if
- not kmapped, ie. highmem) */
- #endif /* WANT_PAGE_VIRTUAL */
- #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
- unsigned long debug_flags; /* Use atomic bitops on this */
- #endif
- #ifdef CONFIG_KMEMCHECK
- /*
- * kmemcheck wants to track the status of each byte in a page; this
- * is a pointer to such a status block. NULL if not tracked.
- */
- void *shadow;
- #endif
- };
页的page结构放在mem_map中。 要想找到一个物理地址对应的page结构很简单, 就是 mem_map[pfn]即可。
由于硬件的关系,会将整个内存分成不同的zone,:ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM. 这样分的原因是 :有些芯片的DMA设置只能设置到固定区域的地址,所以将这些区域作为ZONE_DMA以免其他操作占用。NORMAL就是正常的内存。高位内存内核空间因为只有1G不能全部映射,所以也要做特殊的处理,进行映射,才能使用。
这三个ZONE使用的描述符是:
- struct zone {
- /* Fields commonly accessed by the page allocator */
- /* zone watermarks, access with *_wmark_pages(zone) macros */
- unsigned long watermark[NR_WMARK];
- /*
- * When free pages are below this point, additional steps are taken
- * when reading the number of free pages to avoid per-cpu counter
- * drift allowing watermarks to be breached
- */
- unsigned long percpu_drift_mark;
- /*
- * We don't know if the memory that we're going to allocate will be freeable
- * or/and it will be released eventually, so to avoid totally wasting several
- * GB of ram we must reserve some of the lower zone memory (otherwise we risk
- * to run OOM on the lower zones despite there's tons of freeable ram
- * on the higher zones). This array is recalculated at runtime if the
- * sysctl_lowmem_reserve_ratio sysctl changes.
- */
- unsigned long lowmem_reserve[MAX_NR_ZONES];
- #ifdef CONFIG_NUMA
- int node;
- /*
- * zone reclaim becomes active if more unmapped pages exist.
- */
- unsigned long min_unmapped_pages;
- unsigned long min_slab_pages;
- #endif
- struct per_cpu_pageset __percpu *pageset;
- /*
- * free areas of different sizes
- */
- spinlock_t lock;
- int all_unreclaimable; /* All pages pinned */
- #ifdef CONFIG_MEMORY_HOTPLUG
- /* see spanned/present_pages for more description */
- seqlock_t span_seqlock;
- #endif
- struct free_area free_area[MAX_ORDER];
- #ifndef CONFIG_SPARSEMEM
- /*
- * Flags for a pageblock_nr_pages block. See pageblock-flags.h.
- * In SPARSEMEM, this map is stored in struct mem_section
- */
- unsigned long *pageblock_flags;
- #endif /* CONFIG_SPARSEMEM */
- #ifdef CONFIG_COMPACTION
- /*
- * On compaction failure, 1<<compact_defer_shift compactions
- * are skipped before trying again. The number attempted since
- * last failure is tracked with compact_considered.
- */
- unsigned int compact_considered;
- unsigned int compact_defer_shift;
- #endif
- ZONE_PADDING(_pad1_)
- /* Fields commonly accessed by the page reclaim scanner */
- spinlock_t lru_lock;
- struct zone_lru {
- struct list_head list;
- } lru[NR_LRU_LISTS];
- struct zone_reclaim_stat reclaim_stat;
- unsigned long pages_scanned; /* since last reclaim */
- unsigned long flags; /* zone flags, see below */
- /* Zone statistics */
- atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
- /*
- * The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
- * this zone's LRU. Maintained by the pageout code.
- */
- unsigned int inactive_ratio;
- ZONE_PADDING(_pad2_)
- /* Rarely used or read-mostly fields */
- /*
- * wait_table -- the array holding the hash table
- * wait_table_hash_nr_entries -- the size of the hash table array
- * wait_table_bits -- wait_table_size == (1 << wait_table_bits)
- *
- * The purpose of all these is to keep track of the people
- * waiting for a page to become available and make them
- * runnable again when possible. The trouble is that this
- * consumes a lot of space, especially when so few things
- * wait on pages at a given time. So instead of using
- * per-page waitqueues, we use a waitqueue hash table.
- *
- * The bucket discipline is to sleep on the same queue when
- * colliding and wake all in that wait queue when removing.
- * When something wakes, it must check to be sure its page is
- * truly available, a la thundering herd. The cost of a
- * collision is great, but given the expected load of the
- * table, they should be so rare as to be outweighed by the
- * benefits from the saved space.
- *
- * __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
- * primary users of these fields, and in mm/page_alloc.c
- * free_area_init_core() performs the initialization of them.
- */
- wait_queue_head_t * wait_table;
- unsigned long wait_table_hash_nr_entries;
- unsigned long wait_table_bits;
- /*
- * Discontig memory support fields.
- */
- struct pglist_data *zone_pgdat;
- /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
- unsigned long zone_start_pfn;
- /*
- * zone_start_pfn, spanned_pages and present_pages are all
- * protected by span_seqlock. It is a seqlock because it has
- * to be read outside of zone->lock, and it is done in the main
- * allocator path. But, it is written quite infrequently.
- *
- * The lock is declared along with zone->lock because it is
- * frequently read in proximity to zone->lock. It's good to
- * give them a chance of being in the same cacheline.
- */
- unsigned long spanned_pages; /* total size, including holes */
- unsigned long present_pages; /* amount of memory (excluding holes) */
- /*
- * rarely used fields:
- */
- const char *name;
- } ____cacheline_internodealigned_in_smp;
在这个描述符中,有一个struct free_area free_area[MAX_ORDER]; 这样的成员变量,这个数组的每个元素都包含一个page的list,那么,一共有MAX_ORDER个list。他是将 所有的free page按照连续是否进行分组。 有2个连续的page的,有4个连续的page的,有8个连续的page的,....2^MAX_ORDER。 这样将page进行分类。当需要alloc一些page时,可以方便的从这些list中找连续的page。(slub中也会像这样来分类,但是slub中分类是按byte为单位,如2byte,4byte....)
另外还有一个
- struct zone_lru {
- struct list_head list;
- } lru[NR_LRU_LISTS];
- <p>/*
- * We do arithmetic on the LRU lists in various places in the code,
- * so it is important to keep the active lists LRU_ACTIVE higher in
- * the array than the corresponding inactive lists, and to keep
- * the *_FILE lists LRU_FILE higher than the corresponding _ANON lists.
- *
- * This has to be kept in sync with the statistics in zone_stat_item
- * above and the descriptions in vmstat_text in mm/vmstat.c
- */
- #define LRU_BASE 0
- #define LRU_ACTIVE 1
- #define LRU_FILE 2</p><p>enum lru_list {
- LRU_INACTIVE_ANON = LRU_BASE,
- LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
- LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
- LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
- LRU_UNEVICTABLE,
- NR_LRU_LISTS
- };</p>
这样的成员变量,这也是一个list数组, 其中NR_LRU_LISTS表示在enum 中定义的成员的个数(新的linux中好像有不少这样的用法),这个list数组中,每个list也是很多page结构体。LRU是一中算法,会将长时间不同的page给swap out到flash中。这个数组是LRU算法用的。 其中有 inactive的page, active的page, inactive 的file,等 在后面对LRU介绍。
UMA和NUMA
在linux中,如果CPU访问所有的memory所需的时间都是一样的,那么我们人为这个系统是UMA(uniform memory architecture),但是如果访问memory所需的时间是不一样的(在SMP(多核系统)是很常见的),那么我们人为这个系统是NUMA(Non-uniform memory architecture)。在linux中,系统会将内存分成几个node,每个node中的memory,CPU进入的时间的相等的。这个我们分配内存的时候就会从一个node进行分配。
- typedef struct pglist_data {
- struct zone node_zones[MAX_NR_ZONES];
- struct zonelist node_zonelists[MAX_ZONELISTS];
- int nr_zones;
- #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
- struct page *node_mem_map;
- #ifdef CONFIG_CGROUP_MEM_RES_CTLR
- struct page_cgroup *node_page_cgroup;
- #endif
- #endif
- #ifndef CONFIG_NO_BOOTMEM
- struct bootmem_data *bdata;
- #endif
- #ifdef CONFIG_MEMORY_HOTPLUG
- /*
- * Must be held any time you expect node_start_pfn, node_present_pages
- * or node_spanned_pages stay constant. Holding this will also
- * guarantee that any pfn_valid() stays that way.
- *
- * Nests above zone->lock and zone->size_seqlock.
- */
- spinlock_t node_size_lock;
- #endif
- unsigned long node_start_pfn;
- unsigned long node_present_pages; /* total number of physical pages */
- unsigned long node_spanned_pages; /* total size of physical page
- range, including holes */
- int node_id;
- wait_queue_head_t kswapd_wait;
- struct task_struct *kswapd;
- int kswapd_max_order;
- enum zone_type classzone_idx;
- } pg_data_t;
在pglist_data结构中,一个成员变量node_zones[], 他代表了这个node下的所有zone。组成一个数组。
另一个成员变量node_zonelist[]. 这是一个list数组,每一个list中将不同node下的所有的zone都link到一起。数组中不同元素list中,zone的排列顺序不一样。这样当内核需要malloc一些page的时候,可能当前的这个node中并没有足够的page,那么就会按照这个数组list中的顺序依次去申请空间。内核在不同的情况下,需要按照不同的顺序申请空间。所以需要好几个不同的list,这些list就组成了这个数组。
每一个pglist_data结构对应一个node。这样,在每个zone结构上又多了一个node结构。这样内存页管理的结构应该是
node:同过UMA和NUMA将内存分成几个node。(在arm系统中,如果不是smp的一般都是一个node)
zone:在每个node中,再将内存分配成几个zone。
page:在每个zone中,对page进行管理,添加都各种list中。
for example: 可以分析一下 for_each_zone这个宏定义,会发现就是先查找每个node,在每个node下进行zone的扫描。
上面的这些都是描述物理空间的,page,zone,node都是物理空间的管理结构,下面的结构体,描述虚拟空间
从物理空间来看,物理空间主要是“供”,他是实实在在存在的,主要目的就是向OS提供空间。
从虚拟空间来看,虚拟空间是“需”,他是虚拟的,主要是就发送需求。
*****当虚拟空间提出了 “需求”,但物理空间无法满足时候,就会进行swap out操作了。
vm_area_struct结构:这个结构描述 进程的的内存空间的情况。
- /*
- * This struct defines a memory VMM memory area. There is one of these
- * per VM-area/task. A VM area is any part of the process virtual memory
- * space that has a special rule for the page-fault handlers (ie a shared
- * library, the executable area etc).
- */
- struct vm_area_struct {
- struct mm_struct * vm_mm; /* The address space we belong to. */
- unsigned long vm_start; /* Our start address within vm_mm. */
- unsigned long vm_end; /* The first byte after our end address
- within vm_mm. */
- /* linked list of VM areas per task, sorted by address */
- struct vm_area_struct *vm_next, *vm_prev;
- pgprot_t vm_page_prot; /* Access permissions of this VMA. */
- unsigned long vm_flags; /* Flags, see mm.h. */
- struct rb_node vm_rb;
- /*
- * For areas with an address space and backing store,
- * linkage into the address_space->i_mmap prio tree, or
- * linkage to the list of like vmas hanging off its node, or
- * linkage of vma in the address_space->i_mmap_nonlinear list.
- */
- union {
- struct {
- struct list_head list;
- void *parent; /* aligns with prio_tree_node parent */
- struct vm_area_struct *head;
- } vm_set;
- struct raw_prio_tree_node prio_tree_node;
- } shared;
- /*
- * A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
- * list, after a COW of one of the file pages. A MAP_SHARED vma
- * can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
- * or brk vma (with NULL file) can only be in an anon_vma list.
- */
- struct list_head anon_vma_chain; /* Serialized by mmap_sem &
- * page_table_lock */
- struct anon_vma *anon_vma; /* Serialized by page_table_lock */
- /* Function pointers to deal with this struct. */
- const struct vm_operations_struct *vm_ops;
- /* Information about our backing store: */
- unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
- units, *not* PAGE_CACHE_SIZE */
- struct file * vm_file; /* File we map to (can be NULL). */
- void * vm_private_data; /* was vm_pte (shared mem) */
- unsigned long vm_truncate_count;/* truncate_count or restart_addr */
- #ifndef CONFIG_MMU
- struct vm_region *vm_region; /* NOMMU mapping region */
- #endif
- #ifdef CONFIG_NUMA
- struct mempolicy *vm_policy; /* NUMA policy for the VMA */
- #endif
- };
这个数据结构在程序的变量名字常常是vma。
这个结构是成员变量, vm_start 和vm_end表示一段连续的虚拟区间。 但是并不是一个连续的虚拟区间就可以用一个vm_area_struct结构来表示。而是要 虚拟地址连续,并且这段空间的属性/访问权限等也相同才可以。
所以这段空间的属于和权限用
- pgprot_t vm_page_prot; /* Access permissions of this VMA. */
- unsigned long vm_flags; /* Flags, see mm.h. */
这两个成员变量来表示。看到这两个成员变量可算看到亲人了。 还记得那个大明湖畔的容嬷嬷妈?-------pgprot_t vm_page_prot;
每一个进程的所有vm_erea_struct结构通过
- /* linked list of VM areas per task, sorted by address */
- struct vm_area_struct *vm_next, *vm_prev;
这个指针link起来。
当然,有上面这种链表的链接方式,查找起来是很麻烦的,而且一个进程中可能会有好多个这样的结构,所以 除了上面的链表,还要有一中更有效的查找方式:
- <span style="font-size:13px;"> /*
- * For areas with an address space and backing store,
- * linkage into the address_space->i_mmap prio tree, or
- * linkage to the list of like vmas hanging off its node, or
- * linkage of vma in the address_space->i_mmap_nonlinear list.
- */
- union {
- struct {
- struct list_head list;
- void *parent; /* aligns with prio_tree_node parent */
- struct vm_area_struct *head;
- } vm_set;
- struct raw_prio_tree_node prio_tree_node;
- } shared;
- </span>
有两种情况虚拟空间会与磁盘flash发生关系。
1. 当内存分配失败,没有足够的内存时候,会发生swap。
2. linux进行mmap系统时候,会将磁盘上的内存map到用户空间,像访问memory一样,直接访问文件内容。
为了迎合1. vm_area_struct 的mapping,vm_next_share,vm_pprev_share,vm_file等。但是在2.6.39中没找到这些变量。仅有:(在page结构体中,也有swap相关的信息)
- /* Information about our backing store: */
- unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
- units, *not* PAGE_CACHE_SIZE */
- struct file * vm_file; /* File we map to (can be NULL). */
- void * vm_private_data; /* was vm_pte (shared mem) */
- unsigned long vm_truncate_count;/* truncate_count or restart_addr */
在后面再分析这些结构。
为了迎合2. vm_area_struct结构提供了
- /* Function pointers to deal with this struct. */
- const struct vm_operations_struct *vm_ops;
这样的变量,进行操作。
在vm_area_struct结构中,有个mm_struct结构,注释说他属于这个结构,由此看来,mm_struct结构应该是vm_area_struct结构的上层。
- struct mm_struct {
- struct vm_area_struct * mmap; /* list of VMAs */
- struct rb_root mm_rb;
- struct vm_area_struct * mmap_cache; /* last find_vma result */
- #ifdef CONFIG_MMU
- unsigned long (*get_unmapped_area) (struct file *filp,
- unsigned long addr, unsigned long len,
- unsigned long pgoff, unsigned long flags);
- void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
- #endif
- unsigned long mmap_base; /* base of mmap area */
- unsigned long task_size; /* size of task vm space */
- unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
- unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
- pgd_t * pgd;
- atomic_t mm_users; /* How many users with user space? */
- atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
- int map_count; /* number of VMAs */
- spinlock_t page_table_lock; /* Protects page tables and some counters */
- struct rw_semaphore mmap_sem;
- struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
- * together off init_mm.mmlist, and are protected
- * by mmlist_lock
- */
- unsigned long hiwater_rss; /* High-watermark of RSS usage */
- unsigned long hiwater_vm; /* High-water virtual memory usage */
- unsigned long total_vm, locked_vm, shared_vm, exec_vm;
- unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
- unsigned long start_code, end_code, start_data, end_data;
- unsigned long start_brk, brk, start_stack;
- unsigned long arg_start, arg_end, env_start, env_end;
- unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
- /*
- * Special counters, in some configurations protected by the
- * page_table_lock, in other configurations by being atomic.
- */
- struct mm_rss_stat rss_stat;
- struct linux_binfmt *binfmt;
- cpumask_t cpu_vm_mask;
- /* Architecture-specific MM context */
- mm_context_t context;
- /* Swap token stuff */
- /*
- * Last value of global fault stamp as seen by this process.
- * In other words, this value gives an indication of how long
- * it has been since this task got the token.
- * Look at mm/thrash.c
- */
- unsigned int faultstamp;
- unsigned int token_priority;
- unsigned int last_interval;
- /* How many tasks sharing this mm are OOM_DISABLE */
- atomic_t oom_disable_count;
- unsigned long flags; /* Must use atomic bitops to access the bits */
- struct core_state *core_state; /* coredumping support */
- #ifdef CONFIG_AIO
- spinlock_t ioctx_lock;
- struct hlist_head ioctx_list;
- #endif
- #ifdef CONFIG_MM_OWNER
- /*
- * "owner" points to a task that is regarded as the canonical
- * user/owner of this mm. All of the following must be true in
- * order for it to be changed:
- *
- * current == mm->owner
- * current->mm != mm
- * new_owner->mm == mm
- * new_owner->alloc_lock is held
- */
- struct task_struct __rcu *owner;
- #endif
- #ifdef CONFIG_PROC_FS
- /* store ref to file /proc/<pid>/exe symlink points to */
- struct file *exe_file;
- unsigned long num_exe_file_vmas;
- #endif
- #ifdef CONFIG_MMU_NOTIFIER
- struct mmu_notifier_mm *mmu_notifier_mm;
- #endif
- #ifdef CONFIG_TRANSPARENT_HUGEPAGE
- pgtable_t pmd_huge_pte; /* protected by page_table_lock */
- #endif
- };
这个结构在代码中,经常是mm的名字。
他比vm_area_struct结构更上层,每个进程只有一个mm_struct结构在task_struct中由指针。因此mm_struct结构会更具总结型。
所以虚拟空间的联系图为:

总结一下:
讲解了,
1.PGD,PTE,
2.node--->zone---->page
3. mm_struct------>vm_area_struct
虚拟地址和物理地址 通过 PGD,PTE联系起来。















 70
70











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









