







转自:
http://lli_njupt.0fees.net/ar01s12.html
| 12. 页表机制 | ||
|---|---|---|
| 上一页 | 下一页 | |
在Linux系统中,存在以下三种地址:
- 逻辑地址:它被包含在机器指令中用来指定一个操作数或一条指令的地址。每一个逻辑地址都由一个段(Segment)和偏移量(Offset)组成,偏移量指明了从段开始的地方到实际地址之间的距离。
- 线性地址(虚拟地址):一个32位无符号整数,可以用来表示高达4GB的地址。线性地址通常用十六进制数字表示,值的范围为[0x00000000, 0xffffffff)。
- 物理地址:用于内存芯片级内存单元寻址。它们与从CPU的地址引脚发送到内存总线上的电信号相对应。物理地址由32位或36位无符号整数表示。
内存控制单元(MMU)通过一种称为分段单元的硬件电路把一个逻辑地址转换成线性地址;称为分页单元的硬件电路把线性地址转换成一个物理地址。有些MMU没有分页单元,或者禁止使能分页单元,比如x86的实模式,那么就只有分段单元,那么经过分段单元转换后的地址就是物理地址。有些MMU没有分段单元,大多数RISC架构的CPU就是如此,此时段基址相当于0,而代码中的偏移地址就是线性地址,所有Linux下逻辑地址和线性地址是一致的。如下图所示:

Linux中以非常有限的方式使用分段。运行在用户态的所有Linux进程都使用一对相同的段来对指令和数据寻址,它们的段基址分别是__USER_CS和__USER_DS。与此同时,运行在内核态的所有Linux进程(内核线程)都使用一对相同的段对指令和数据寻址,它们的段基址分别__KERNEL_CS和__KERNEL_DS。
分段可以给每个进程分配不同的线性地址空间,分页可以把同一线性地址空间映射到不同的物理空间。与分段相比,Linux更喜欢分页方式,因为:
- 当所有进程使用相同的段寄存器值时,内存管理变得更简单,也就是说它们能共享同样的一簇线性地址。
- 为了兼容绝大多数的CPU,RISC体系架构对分段的支持很有限,比如ARM架构的CPU中的MMU单元通常只支持分页,而不支持分段。
分页使得不同的虚拟内存页可以转入同一物理页框。于此同时分页机制可以实现对每个页面的访问控制,这是在平衡内存使用效率和地址转换效率之间做出的选择。如果4G的虚拟空间,每一个字节都要使用一个数据结构来记录它的访问控制信息,那么显然是不可能的。如果把4G的虚拟空间以4K(为什么是4K大小?这是由于Linux中的可执行文件中的代码段和数据段等都是相对于4K对齐的)大小分割成若干个不同的页面,那么每个页面需要一个数据结构进行控制,只需要1M的内存来存储。但是由于每一个用户进程都有自己的独立空间,所以每一个进程都需要一个1M的内存来存储页表信息,这依然是对系统内存的浪费,采用两级甚至多级分页是一种不错的解决方案。另外有些处理器采用64位体系架构,此时两级也不合适了,所以Linux使用三级页表。
- 页全局目录(Page Global Directory),即 pgd,是多级页表的抽象最高层。每一级的页表都处理不同大小的内存。每项都指向一个更小目录的低级表,因此pgd就是一个页表目录。当代码遍历这个结构时(有些驱动程序就要这样做),就称为是在遍历页表。
- 页中间目录 (Page Middle Directory),即pmd,是页表的中间层。在 x86 架构上,pmd 在硬件中并不存在,但是在内核代码中它是与pgd合并在一起的。
- 页表条目 (Page Table Entry),即pte,是页表的最低层,它直接处理页,该值包含某页的物理地址,还包含了说明该条目是否有效及相关页是否在物理内存中的位。
三级页表由不同的的数据结构表示,它们分别是pgd_t,pmd_t和pte_t。注意到它们均被定义为unsigned long类型,也即大小为4bytes,32bits。
arch/arm/include/asm/page.h typedef unsigned long pte_t; typedef unsigned long pmd_t; typedef unsigned long pgd_t[2]; typedef unsigned long pgprot_t;
以下是页表操作相关的宏定义。
#define pte_val(x) (x) #define pmd_val(x) (x) #define pgd_val(x) ((x)[0]) #define pgprot_val(x) (x) #define __pte(x) (x) #define __pmd(x) (x) #define __pgprot(x) (x)
任何一个用户进程都有自己的页表,与此同时,内核本身就是一个名为init_task的0号进程,每一个进程都有一个mm_struct结构管理进程的内存空间,init_mm是内核的mm_struct。在系统引导阶段,首先通过__create_page_tables在内核代码的起始处_stext向低地址方向预留16K,用于一级页表(主内存页表)的存放,每个进程的页表都通过mm_struct中的pgd描述符进行引用。内核页表被定义在swapper_pg_dir。
arch/arm/kernel/init_task.c
#define INIT_MM(name) \
{ \
.mm_rb = RB_ROOT, \
.pgd = swapper_pg_dir, \
.mm_users = ATOMIC_INIT(2), \
.mm_count = ATOMIC_INIT(1), \
.mmap_sem = __RWSEM_INITIALIZER(name.mmap_sem), \
.page_table_lock = __SPIN_LOCK_UNLOCKED(name.page_table_lock), \
.mmlist = LIST_HEAD_INIT(name.mmlist), \
.cpu_vm_mask = CPU_MASK_ALL, \
}
struct mm_struct init_mm = INIT_MM(init_mm);
swapper_pg_dir在head.S中被定义为PAGE_OFFSET向上偏移TEXT_OFFSET。TEXT_OFFSET代表内核代码段的相对于PAGE_OFFSET的偏移。KERNEL_RAM_VADDR的值与_stext的值相同,代表了内核代码的起始地址。swapper_pg_dir为KERNEL_RAM_VADDR - 0x4000,也即向低地址方向偏移了16K。
arch/arm/Makefile textofs-y := 0x00008000 ...... TEXT_OFFSET := $(textofs-y)
特定系统架构的Makefile中通过textofs-y定义了内核起始代码相对于PAGE_OFFSET的偏移。
arch/arm/kernel/head.S #define KERNEL_RAM_VADDR (PAGE_OFFSET + TEXT_OFFSET) ...... .globl swapper_pg_dir .equ swapper_pg_dir, KERNEL_RAM_VADDR - 0x4000
ARM Linux中的主内存页表,使用段表。每个页表映射1M的内存大小,由于16K / 4 * 1M = 4G,这16K的主页表空间正好映射4G的虚拟空间。内核页表机制在系统启动过程中的paging_init函数中使能,其中对内核主页表的初始化等操作均是通过init_mm.pgd的引用来进行的。在系统执行paging_init之前,系统的地址空间如下图所示:

图中的黄色部分就是内核0号进程的主页表。
arch/arm/mm/mmu.c
void __init paging_init(struct meminfo *mi, struct machine_desc *mdesc)
{
void *zero_page;
build_mem_type_table();
sanity_check_meminfo(mi);
prepare_page_table(mi);
bootmem_init(mi);
devicemaps_init(mdesc);
top_pmd = pmd_off_k(0xffff0000);
zero_page = alloc_bootmem_low_pages(PAGE_SIZE);
memzero(zero_page, PAGE_SIZE);
empty_zero_page = virt_to_page(zero_page);
flush_dcache_page(empty_zero_page);
}

paging_init依次完成了以下工作:
- 调用prepare_page_table初始化虚拟地址[0, PAGE_OFFSET]和[mi->bank[0].start + mi->bank[0].size, VMALLOC_END]所对应的主页表项,所有表项均初始化为0。这里保留了内核代码区,主页表区以及Bootmem机制中的位图映射区对应的主页表。这是为了保证内核代码的执行以及对主页表区和位图区的访问。如果只有一个内存bank,那么mi->bank[0].start + mi->bank[0].size的值和high_memory保持一致,它是当前bank进行物理内存一一映射后的虚拟地址。对于一个内存为256M的系统来说,它只有一个bank,经过prepare_page_table处理后的内存如上图所示。
- 接着在bootmem_init函数将通过bootmem_init_node对每一个内存bank的页表进行值的填充。bootmem_init_node将通过map_memory_bank间接调用create_mapping,最终由该函数创建页表。
- 通过devicemaps_init初始化设备I/O对应的相关页表。
- 最后创建0页表,并在Dcache中清空0页表的缓存信息。

当ARM要访问内存RAM时,MMU首先查找TLB中的虚拟地址表,如果ARM的结构支持分开的地址TLB和指令TLB,那么它用:
- 取指令使用指令TLB
- 其它的所有访问类别用数据TLB
指令TLB和数据TLB在ARMv6架构的MMU中被分别称为指令MicroTLB和数据MicroTLB。如果没有命中MicroTLB,那么将查询主TLB,此时不区分指令和数据TLB。
如果TLB中没有虚拟地址的入口,则转换表遍历硬件从存在主存储器中的转换表中获取转换页表项,它包含了物理地址或者二级页表地址和访问权限,一旦取到,这些信息将被放在TLB中,它会放在一个没有使用的入口处或覆盖一个已有的入口。一旦为存储器访问的TLB 的入口被拿到,这些信息将被用于:
- C(高速缓存)和B(缓冲)位被用来控制高速缓存和写缓冲,并决定是否高速缓存。
- 首先检查域位,然后检查访问权限位用来控制访问是否被允许。如果不允许,则MMU 将向ARM处理器发送一个存储器异常;否则访问将被允许进行。
- 对没有或者禁止高速缓存的系统(包括在没有高速缓存系统中的所有存储器访问),物理地址将被用作主存储器访问的地址。

- 兼容ARMv4和ARMv5 MMU机制的页表描述符。这种描述符可以对64K大页面和4K小页面再进一步细分为子页面。
- ARMv6特有的MMU页表描述符,这种页表描述符内增加了额外的特定比特位:Not-Global(nG),Shared (S),Execute-Never (XN)和扩展的访问控制位APX。


Linux使用ARMv6特有的MMU页表描述符格式,它们的标志位描述如下:

表 20. ARMv6一级页表描述符比特位含义
| 位 | 标志 | 含义 |
|---|---|---|
| b[1:0] | 类型 | 指示页表类型:b00 错误项;b11 保留;b01粗页表,它指向二级页表基址。 b10:1MB大小段页表(b[18]置0)或16M大小超级段页表(b[18]置1) |
| b[2] | B[a] | 写缓冲使能[b] |
| b[4] | Execute-Never(XN) | 禁止执行标志:1,禁止执行;0:可执行 |
| b[5:8] | 域(domain) | 指明所属16个域的哪个域,访问权限由CP15的c3寄存器据定 |
| b[9] | P(ECC Enable) | ECC使能标志,1:该页表映射区使能ECC校验[c] |
| b[10:11] | AP(Access Permissions) | 访问权限位,具体见访问权限列表 |
| b[12:14] | TEX(Type Extension Field) | 扩展类型,与B,C标志协同控制内存访问类型 |
| bit[15] | APX(Access Permissions Extension Bit) | 扩展访问权限位 |
| bit[16] | S(Shared) | 共享访问 |
| bit[17] | nG(Not-Global) | 全局访问 |
| bit[18] | 0/1 | 段页表和超级段页表开关 |
| bit[19] | NS | |
|
[a]高速缓存和写缓存的引入是基于如下事实,即处理器速度远远高于存储器访问速度;如果存储器访问成为系统性能的瓶颈,则处理器再快也是浪费,因为处理器需要耗费大量的时间在等待存储器上面。高速缓存正是用来解决这个问题,它可以存储最近常用的代码和数据,以最快的速度提供给CPU处理(CPU访问Cache不需要等待)。 [b]SBZ意味置0,该位在粗页表中置0。 [c]ARM1176JZF-S处理器不支持该标志位。 | ||
Linux 在ARM体系架构的Hardware page table头文件中通过宏定义了这些位。
arch/arm/include/asm/pgtable-hwdef.h /* * Hardware page table definitions. * * + Level 1 descriptor (PMD) * - common */ #define PMD_TYPE_MASK (3 << 0) // 获取一级页表类型的掩码,它取bit[0:1] #define PMD_TYPE_FAULT (0 << 0) // 置bit[0:1]为b00,错误项 #define PMD_TYPE_TABLE (1 << 0) // 置bit[0:1]为b01,粗页表 #define PMD_TYPE_SECT (2 << 0) // 置bit[0:1]为b10,段页表 #define PMD_BIT4 (1 << 4) // 定义bit[4],禁止执行标志位 #define PMD_DOMAIN(x) ((x) << 5) // 获取域标志位b[5:8] #define PMD_PROTECTION (1 << 9) // b[9]ECC使能标志以上定义了一级页表的相关标志位。Linux使用段页表作为一级页表,粗页表作为二级页表的基址页表。段页表的标志位定义如下:
#define PMD_SECT_BUFFERABLE (1 << 2) #define PMD_SECT_CACHEABLE (1 << 3) #define PMD_SECT_XN (1 << 4) /* v6 */ #define PMD_SECT_AP_WRITE (1 << 10) #define PMD_SECT_AP_READ (1 << 11) #define PMD_SECT_TEX(x) ((x) << 12) /* v5 */ #define PMD_SECT_APX (1 << 15) /* v6 */ #define PMD_SECT_S (1 << 16) /* v6 */ #define PMD_SECT_nG (1 << 17) /* v6 */ #define PMD_SECT_SUPER (1 << 18) /* v6 */
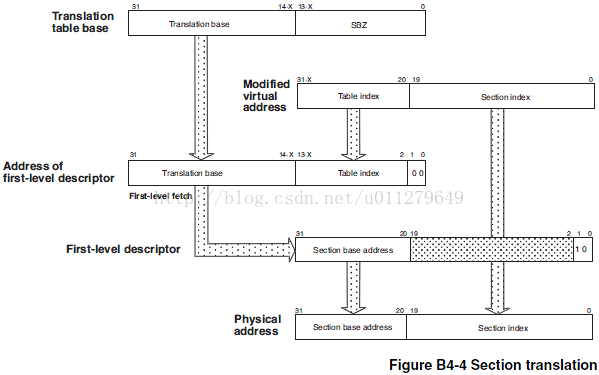

二级页表相同标志位的含义与一级页表相同,这里不再单独列出。注意它的b[1]为1时,b[0]表示禁止执行标志。Linux对二级页表中的标志位定义如下:
/* * + Level 2 descriptor (PTE) * - common */ #define PTE_TYPE_MASK (3 << 0) // 获取二级页表类型的掩码,它取bit[0:1] #define PTE_TYPE_FAULT (0 << 0) // 置bit[0:1]为b00,错误项 #define PTE_TYPE_LARGE (1 << 0) // 置bit[0:1]为b01,大页表(64K) #define PTE_TYPE_SMALL (2 << 0) // 置bit[0:1]为b10,扩展小页表(4K) #define PTE_TYPE_EXT (3 << 0) // 使能禁止执行标志的扩展小页表(4K) #define PTE_BUFFERABLE (1 << 2) // B标志 #define PTE_CACHEABLE (1 << 3) // C标志Linux二级页表使用扩展小页表,这样每个二级页表可以表示通常的1个页面大小(4K)。Linux对二级页表标志位的定义如下:
/* * - extended small page/tiny page */ #define PTE_EXT_XN (1 << 0) /* v6 */ #define PTE_EXT_AP_MASK (3 << 4) #define PTE_EXT_AP0 (1 << 4) #define PTE_EXT_AP1 (2 << 4) #define PTE_EXT_AP_UNO_SRO (0 << 4) #define PTE_EXT_AP_UNO_SRW (PTE_EXT_AP0) #define PTE_EXT_AP_URO_SRW (PTE_EXT_AP1) #define PTE_EXT_AP_URW_SRW (PTE_EXT_AP1|PTE_EXT_AP0) #define PTE_EXT_TEX(x) ((x) << 6) /* v5 */ #define PTE_EXT_APX (1 << 9) /* v6 */ #define PTE_EXT_COHERENT (1 << 9) /* XScale3 */ #define PTE_EXT_SHARED (1 << 10) /* v6 */ #define PTE_EXT_NG (1 << 11) /* v6 */以上两种页表转换机制由CP15协处理器的控制寄存器c1中的bit23来选择。bit23为0时为第一种机制,否则为第二种。在CPU初始化后该位的默认值为0。Linux在系统引导时会设置MMU的控制寄存器的相关位,其中把bit23设置为1,所以Linux在ARMv6体系架构上采用的是ARMv6 MMU页表转换机制。
arch/arm/mm/proc-v6.S
__v6_setup:
......
adr r5, v6_crval
ldmia r5, {r5, r6}
mrc p15, 0, r0, c1, c0, 0 @ read control register
bic r0, r0, r5 @ clear bits them
orr r0, r0, r6 @ set them
mov pc, lr @ return to head.S:__ret
/*
* V X F I D LR
* .... ...E PUI. .T.T 4RVI ZFRS BLDP WCAM
* rrrr rrrx xxx0 0101 xxxx xxxx x111 xxxx < forced
* 0 110 0011 1.00 .111 1101 < we want
*/
.type v6_crval, #object
v6_crval:
crval clear=0x01e0fb7f, mmuset=0x00c0387d, ucset=0x00c0187c
注意到v6_crval定义了三个常量,首先mrc指令读取c1到r0,然后清除clear常量指定的比特位,然后设置mmuset指定的比特位,其中bit23为1。在mov pc, lr跳转后将执行定义在head.S中的__enable_mmu函数,在进一步调节其它的比特位后最终将把r0中的值写回c1寄存器。
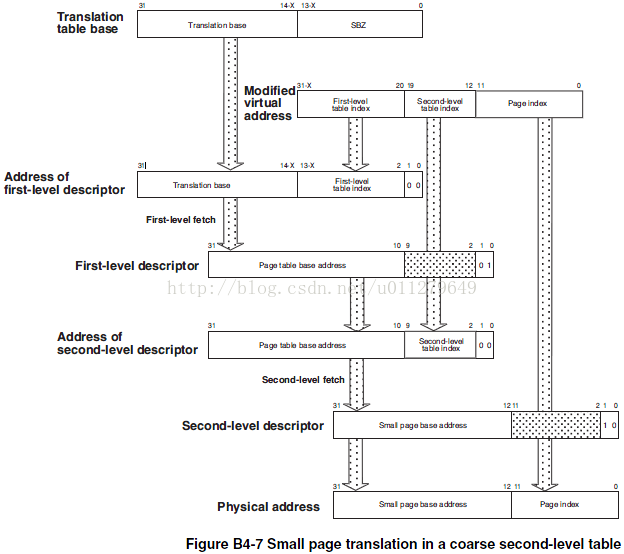
arch/arm/include/asm/io.h /* * Architecture ioremap implementation. */ #define MT_DEVICE 0 #define MT_DEVICE_NONSHARED 1 #define MT_DEVICE_CACHED 2 #define MT_DEVICE_WC 3 arch/arm/include/asm/mach/map.h /* types 0-3 are defined in asm/io.h */ #define MT_UNCACHED 4 #define MT_CACHECLEAN 5 #define MT_MINICLEAN 6 #define MT_LOW_VECTORS 7 #define MT_HIGH_VECTORS 8 #define MT_MEMORY 9 #define MT_ROM 10系统中定义了多个映射类型,最常用的是MT_MEMORY,它对应RAM;MT_DEVICE则对应了其他I/O设备,应用于ioremap;MT_ROM对应于ROM;MT_LOW_VECTORS对应0地址开始的向量;MT_HIGH_VECTORS对应高地址开始的向量,它有vector_base宏决定。
arch/arm/mm/mm.h
struct mem_type {
unsigned int prot_pte;
unsigned int prot_l1;
unsigned int prot_sect;
unsigned int domain;
};
尽管Linux在多数系统上实现或者模拟了3级页表,但是在ARM Linux上它只实现了主页表和两级页表。主页表通过ARM CPU的段表实现,段表中的每个页表项管理1M的内存,虚拟地址只需要一次转换既可以得到物理地址,它通常存放在swapper_pg_dir开始的16K区域内。两级页表只有在被映射的物理内存块不满足1M的情况下才被使用,此时它由L1和L2组成。
- prot_pte和prot_l1分别对应两级页表中的L2和L1,分别代表了页表项的访问控制位,其中prot_l1中还包含内存域
- prot_sect代表主页表的访问控制位和内存域。
- domain代表了内存域。在ARM处理器中,MMU将整个存储空间分成最多16个域,记作D0~D15,每个域对应一定的存储区域,该区域具有相同的访问控制属性。
arch/arm/include/asm/domain.h #define DOMAIN_KERNEL 0 #define DOMAIN_TABLE 0 #define DOMAIN_USER 1 #define DOMAIN_IO 2ARM Linux 中只是用了16个域中的三个域D0-D2。它们由上面的宏来定义,在系统引导时初始化MMU的过程中将对这三个域设置域访问权限。以下是内存空间和域的对应表:
表 21. 内存空间和域的对应表
| 内存空间 | 域 |
|---|---|
| 设备空间 | DOMAIN_IO |
| 内部高速SRAM空间/内部MINI Cache空间 | DOMAIN_KERNEL |
| RAM内存空间/ROM内存空间 | DOMAIN_KERNEL |
| 高低端中断向量空间 | DOMAIN_USER |
在ARM处理器中,MMU中的每个域的访问权限分别由CP15的C3寄存器中的两位来设定,c3寄存器的小为32bits,刚好可以设置16个域的访问权限。下表列出了域的访问控制字段不同取值及含义:
表 22. ARM内存访问控制字
| 值 | 访问类型 | 含义 |
|---|---|---|
| 0b00 | 无访问权限 | 此时访问该域将产生访问失效 |
| 0b01 | 用户(client) | 根据CP15的C1控制寄存器中的R和S位以及页表中地址变换条目中的访问权限控制位AP来确定是否允许各种系统工作模式的存储访问 |
| 0b10 | 保留 | 使用该值会产生不可预知的结果 |
| 0b11 | 管理者(Manager) | 不考虑CP15的C1控制寄存器中的R和S位以及页表中地址变换条目中的访问权限控制位AP,在这种情况下不管系统工作在特权模式还是用户模式都不会产生访问失效 |
Linux定义了其中可以使用的三种域控制:
arch/arm/include/asm/domain.h #define DOMAIN_NOACCESS 0 #define DOMAIN_CLIENT 1 #define DOMAIN_MANAGER 3Linux在系统引导设置MMU时初始化c3寄存器来实现对内存域的访问控制。其中对DOMAIN_USER,DOMAIN_KERNEL和DOMAIN_TABLE均设置DOMAIN_MANAGER权限;对DOMAIN_IO设置DOMAIN_CLIENT权限。如果此时读取c3寄存器,它的值应该是0x1f。
arch/arm/include/asm/domain.h
#define domain_val(dom,type) ((type) << (2*(dom)))
arch/arm/kernel/head.S
......
mov r5, #(domain_val(DOMAIN_USER, DOMAIN_MANAGER) | \
domain_val(DOMAIN_KERNEL, DOMAIN_MANAGER) | \
domain_val(DOMAIN_TABLE, DOMAIN_MANAGER) | \
domain_val(DOMAIN_IO, DOMAIN_CLIENT))
mcr p15, 0, r5, c3, c0, 0 @ load domain access register
mcr p15, 0, r4, c2, c0, 0 @ load page table pointer
b __turn_mmu_on
ENDPROC(__enable_mmu)
在系统的引导过程中对这3个域的访问控制位并不是一成不变的,它提供了一个名为modify_domain的宏来修改域访问控制位。系统在setup_arch中调用early_trap_init后,DOMAIN_USER的权限位将被设置成DOMAIN_CLIENT,此时它的值应该是0x17。
arch/arm/include/asm/domain.h
#define set_domain(x) \
do { \
__asm__ __volatile__( \
"mcr p15, 0, %0, c3, c0 @ set domain" \
: : "r" (x)); \
isb(); \
} while (0)
#define modify_domain(dom,type) \
do { \
struct thread_info *thread = current_thread_info(); \
unsigned int domain = thread->cpu_domain; \
domain &= ~domain_val(dom, DOMAIN_MANAGER); \
thread->cpu_domain = domain | domain_val(dom, type); \
set_domain(thread->cpu_domain); \
} while (0)
访问权限由CP15的c1控制寄存器中的R和S位以及页表项中的访问权限控制位AP[0:1]以及访问权限扩展位APX来确定,通过R和S的组合控制方式在第一项中说明,并且已不被推荐使用。具体说明如下表所示。
表 23. MMU中存储访问权限控制[8]
| APX | AP[1:0] | 特权模式访问权限 | 用户模式访问权限 |
|---|---|---|---|
| 0 | b00 | 禁止访问;S=1,R=0或S=0,R=1时只读 | 禁止访问;S=1,R=0时只读 |
| 0 | b01 | 读写 | 禁止访问 |
| 0 | b10 | 读写 | 只读 |
| 0 | b11 | 读写 | 读写 |
| 1 | b00 | 保留 | 保留 |
| 1 | b01 | 只读 | 禁止访问 |
| 1 | b10 | 只读 | 只读 |
| 1 | b11 | 只读 | 只读 |
|
[8]参考ARM1176JZF-S Revision: r0p7->6.5.2 Access permissions | |||
static struct mem_type mem_types[] = {
......
[MT_MEMORY] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
......
};
对于MT_MEMORY的内存映射类型,依据段页表的各位功能,定义了如下的宏,显然PMD_TYPE_SECT定义了段页表类型0b10,PMD_SECT_AP_WRITE和PMD_SECT_AP_READ则对应AP[0]和AP[1]访问权限控制位。根据
表 23 “MMU中存储访问权限控制”,在使用AP[0:1]进行权限控制时,CP15中的C1寄存器中的S和R标志位不影响权限,根据AP权限位的意义,并不能直接根据宏的后缀名得出是对读还是写的控制。
arch/arm/include/asm/pgtable-hwdef.h #define PMD_TYPE_TABLE (1 << 0) #define PMD_TYPE_SECT (2 << 0) #define PMD_BIT4 (1 << 4) #define PMD_DOMAIN(x) ((x) << 5) ...... #define PMD_SECT_AP_WRITE (1 << 10) #define PMD_SECT_AP_READ (1 << 11)一个描述了当前系统mem_types描述的所有内存映射类型权限控制的列表如下所示:
表 24. ARM Linux内存映射权限控制[9]
| 内存映射类型 | 域定义 | 段页表项权限定义 | L1页表项权限定义 | PTE项权限定义 |
|---|---|---|---|---|
| MT_DEVICE | DOMAIN_IO | PROT_SECT_DEVICE[a] PMD_SECT_S | PMD_TYPE_TABLE | PROT_PTE_DEVICE[b] L_PTE_MT_DEV_SHARED L_PTE_SHARED |
| MT_DEVICE_NONSHARED | DOMAIN_IO | PROT_SECT_DEVICE | PMD_TYPE_TABLE | PROT_PTE_DEVICE L_PTE_MT_DEV_NONSHARED |
| MT_DEVICE_CACHED | DOMAIN_IO | PROT_SECT_DEVICE PMD_SECT_WB | PMD_TYPE_TABLE | PROT_PTE_DEVICE L_PTE_MT_DEV_CACHED |
| MT_DEVICE_WC | DOMAIN_IO | PROT_SECT_DEVICE | PMD_TYPE_TABLE | ROT_PTE_DEVICE L_PTE_MT_DEV_WC |
| MT_UNCACHED | DOMAIN_IO | PMD_TYPE_SECT PMD_SECT_XN | PMD_TYPE_TABLE | PROT_PTE_DEVICE |
| MT_CACHECLEAN | DOMAIN_KERNEL | PMD_TYPE_SECT PMD_SECT_XN | ||
| MT_MINICLEAN | DOMAIN_KERNEL | PMD_TYPE_SECT PMD_SECT_XN PMD_SECT_MINICACHE, | ||
| MT_LOW_VECTORS | DOMAIN_USER | PMD_TYPE_TABLE | L_PTE_PRESENT L_PTE_YOUNG L_PTE_DIRTY L_PTE_EXEC | |
| MT_HIGH_VECTORS | DOMAIN_USER | PMD_TYPE_TABLE | L_PTE_PRESENT L_PTE_YOUNG L_PTE_DIRTY L_PTE_USER L_PTE_EXEC | |
| MT_MEMORY | DOMAIN_KERNEL | PMD_TYPE_SECT PMD_SECT_AP_WRITE | ||
| MT_ROM | DOMAIN_KERNEL | PMD_TYPE_SECT | ||
|
[9]该表描述了Linux2.6.28 ARM体系架构的mem_types内存映射权限控制 [a]在mmu.c中它被定义为 PMD_TYPE_SECT|PMD_SECT_AP_WRITE [b]在mmu.c中它被定义为 L_PTE_PRESENT|L_PTE_YOUNG|L_PTE_DIRTY|L_PTE_WRITE | ||||
build_mem_type_table函数在paging_init执行的开始被调用,它将根据当前CPU的特性进一步调整这些访问权限位。
- MT_MEMORY被用来映射主存RAM。它只有段页表,对应访问权限中的第二条:特权模式可以读写,用户模式禁止访问。
arch/arm/mm/mmu.c void __init create_mapping(struct map_desc *md);
create_mapping只有一个类型为struct map_desc的参数。这是一个非常简单的参数,但是包含了创建页表相关的所有信息。
- virtual记录了映射到的虚拟地址的开始。
- pfn指明了被映射的物理内存的起始页框。
- length指明了被映射的物理内存的大小,注意这里不是页框大小。对于256M的物理内存,这里的值为0x10000000。
- type指明映射类型,MT_xxx,决定了相应映射页面的访问权限。
arch/arm/include/asm/mach/map.h
struct map_desc {
unsigned long virtual;
unsigned long pfn;
unsigned long length;
unsigned int type;
};
在Bootmem机制应用中有提到,系统中所有的内存块都在启动时被注册到meminfo中以struct membank类型的数组形式存在。map_memory_bank的作用就是将以struct membank类型的内存节点转换为struct map_desc类型然后传递给create_mapping。
struct meminfo {
.nr_banks = 1;
bank[8] =
{
{
.start = 0x50000000;
.size = 0x10000000;
.node = 0;
};
...
}
};
对于只有一个大小为256M物理RAM内存的系统来说,如果它具有以上的struct membank类型的内存信息,那么create_mapping得到的参数md如下所示:
map_desc {
.virtual = 0xc0000000;
.pfn = 0x50000;
.length = 0x10000000;
.type = MT_MEMORY;
};
[MT_MEMORY] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
}
create_mapping依次完成了以下工作:
- 首先根据传入的virtual虚拟地址与中断向量起始地址比较,除特殊的中断向量使用的虚拟地址可能落在0地址外,确保映射到的虚拟地址落在内核空间。通过vectors_base宏,获取中断向量的起始地址,这是由于ARMv4以下的版本,该地址固定为0;ARMv4及以上版本,ARM中断向量表的地址由CP15协处理器c1寄存器中的V位(bit[13])控制,如果V位为1,那么该地址为0xffff0000。考虑到除了ARMv4以下的版本的中断向量所在的虚拟地址为0,其他所有映射到的虚拟地址应该都在地址0xc0000000之上的内核空间,而不可能被映射到用户空间。
- 接着根据type类型判断是否为普通设备或者ROM,这些设备中的内存不能被映射到RAM映射的区域[PAGE_OFFSET,high_memory),也不能被映射到VMALLOC所在的区域[high_memory,VMALLOC_END),由于这两个区域是连续的,中间隔了8M的VMALLOC_OFFSET隔离区,准确来说是不能映射到[VMALLOC_START,VMALLOC_END),但是这一隔离区为了使能隔离之用也是不能被映射的。
- 根据pfn与1G内存对应的最大物理页框0x100000比较,如果物理内存的起始地址位于32bits的物理地址之外,那么通过create_36bit_mapping创建36bits长度的页表,对于嵌入式系统来说很少有这种应用。
- 调整传入的md中的各成员信息:virtual向低地址对齐到页面大小;根据length参数取对齐到页面的大小的长度,并以此计算映射结束的虚拟地址。根据pfn参数计算起始物理地址。
- 根据虚拟地址和公式pgd = pgd_offset_k(addr)计算页表地址。
- 根据虚拟地址的起始地址参数以及起始物理地址调用alloc_init_section来生成页表。
pgd_offset_k宏将一个0-4G范围内的虚拟地址转换为内核进程主页表中的对应页表项所在的地址。它首先根据pgd_index计算该虚拟地址对应的页表项在主页表中的索引值这里需要注意PGDIR_SHIFT的值为21,而非20,所以它的偏移是取2M大小区块的索引,这是由于pgd_t的类型为两个长整形的元素。然后根据索引值和内核进程中的init_mm.pgd取得页表项地址。
arch/arm/include/asm/pgtable.h /* to find an entry in a page-table-directory */ #define pgd_index(addr) ((addr) >> PGDIR_SHIFT) #define pgd_offset(mm, addr) ((mm)->pgd+pgd_index(addr)) /* to find an entry in a kernel page-table-directory */ #define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
create_mapping在本质上是对传入参数的检查,并为调用alloc_init_section准备四要素:页表地址,虚拟地址的起止地址和物理地址的起始地址。Linux对create_mapping的调用除了在arch/arm/mm/init.c中通过map_memory_bank初始化主内存页面映射外,对其的调用均集中在arch/arm/mm/mmu.c中,其中iotable_init封装create_mapping用于特定机器架构的设备I/O映射。
页表创建函数调用图中给出了alloc_init_section在页表创建中所处的实现位置,本质上它是与alloc_init_pte并行的函数,alloc_init_section被用来创建段页表(主页表),alloc_init_pte则用来在被映射区长度小于1M时创建2级页表。
static void __init alloc_init_section(pgd_t *pgd, unsigned long addr, unsigned long end, unsigned long phys, const struct mem_type *type);
- pgd参数指定生成的页表的起始地址,它是一个pgd_t类型,被定义为typedef unsigned long pgd_t[2],所以它是一个2维数组。
- addr和end分别指明被映射到的虚拟地址的起止地址。
- phys指明被映射的物理地址的起始地址。
- type参数指明映射类型,所有映射类型在struct mem_type mem_types[]数组中被统一定义。
alloc_init_section依次完成了以下工作:
- 首先根据公式(addr | end | phys) & ~SECTION_MASK) == 0依据传入的的addr,end和phys参数判断是否满足地址对齐到1M。
- 如果满足则直接生成段页表(主页表),并存入pgd指向的地址。由于pgd是一个2维数组,所以每次需要对2个元素赋值,也即一次可以处理2M的内存映射,生成两个页表项。它在一个循环中以SECTION_SIZE为步进单位,通过phys | type->prot_sect来生成和填充页表。主RAM内存就是通过这种方法生成。一个256M内存RAM的生成页表如下图中的棕色部分所示。
- 调用flush_pmd_entry清空TLB中的页面Cache,以使得新页表起作用。
- 如不满足直接生成主页表,那么调用alloc_init_pte生成二级页表。

static void __init alloc_init_pte(pmd_t *pmd, unsigned long addr, unsigned long end, unsigned long pfn, const struct mem_type *type);
- pmd参数传递L1页表地址。
- addr和end分别指明被映射到的虚拟地址的起止地址。
- pfn是将被映射的物理地址的页框。
- type参数指明映射类型。
alloc_init_pte依次完成以下工作:
- 首先判断pmd指向的L1页表中的页表项是否存在,如果不存在则首先使用Bootmem机制中的alloc_bootmem_low_pages函数申请所需的二级页表空间,大小为4K,1个PAGE。
表 25. 页表计算
| 页表名称 | 计算公式 | 说明 |
|---|---|---|
| 主页表项地址 | pgd_offset_k(vir_addr) | #define PGDIR_SHIFT 21 #define pgd_index(addr) ((addr) >> PGDIR_SHIFT) #define pgd_offset(mm, addr) ((mm)->pgd+pgd_index(addr)) #define pgd_offset_k(addr) pgd_offset(&init_mm, addr) |
| 主页表项 | __pmd(phys | type->prot_sect) | #define __pmd(x) (x) |
| 一级页表项地址 | pmd = (pmd_t *)pgd_offset_k(vir_addr); | 同"主页表项地址" |
| 一级页表项 | pte = alloc_bootmem_low_pages(1024 * sizeof(pte_t)); __pmd_populate(pmd, __pa(pte) | type->prot_l1); | static inline void __pmd_populate(pmd_t *pmdp, unsigned long pmdval){ pmdp[0] = __pmd(pmdval); pmdp[1] = __pmd(pmdval + 256 * sizeof(pte_t)); flush_pmd_entry(pmdp); } |
| 二级页表项地址 | pte = alloc_bootmem_low_pages(1024 * sizeof(pte_t)); | 通过Bootmem机制申请1个页面大小的内存。 |
| 二级页表项 | pte = pte_offset_kernel(pmd, addr); set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)), 0); | #define __pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1)) #define pte_offset_kernel(dir,addr) (pmd_page_vaddr(*(dir)) + __pte_index(addr)) #define __pgprot(x) (x) #define pgprot_val(x) (x) #define __pte(x) (x) #define pfn_pte(pfn,prot) (__pte(((pfn) << PAGE_SHIFT) | pgprot_val(prot))) |
对于pgd_offset_k宏的说明如下:
- init_mm.pgd类型为pgd_t类型,所以主页表总是以2个页表项为一组,它的大小为2 * sizeof(unsigned long) = 8。
- 虚拟地址首先右移21位,是为了取高11位作为2个页表项为一组这里数据类型的索引值,在计算(mm)->pgd+pgd_index(addr)时,是指针的相加,等价于(pgd_t *)((unsigned long)init_mm.pgd + 8 * ((addr) >> 21))。
- 由于每个页表项的大小为4,所以对应于单个页表项的大小,其索引值为8 * ((addr) >> 21) / 4 = 2 * ((addr),地址则为8 * ((addr) >> 21)。右移21然后乘以2,相当于取高12位,并将最后位置0,再乘以4则到达了地址。相当于乘以8。这里取的总是偶数索引,也即create_mapping传递给alloc_init_section的pgd参数永远指向偶数索引。
- 如果需要取奇数索引的页表项怎么办呢?该值将在alloc_init_section中通过(addr & SECTION_SIZE)对它进行修正。
- 主页表项的基地址init_mm.pgd加上索引值就是主页表项的地址。
对__pmd_populate内联函数的说明如下:
- 它同时处理两个一级页表项pmd[0]和pmd[1]。
- pmd[0]的值即为传入的pmdval,也即通过Bootmem机制获取的地址pte转化为物理地址后加上保护标志。
- pmd[1]的值是pmd[0]的值的偏移,它偏移了256个PTE页表项,由于每个PTE页表项也是4字节,所以偏移的的物理地址为256 * sizeof(pte_t)。
- 调用flush_pmd_entry清空TLB中的页面Cache,以使得新页表起作用。
#define PTRS_PER_PTE 512
#define pmd_val(x) (x)
static inline pte_t *pmd_page_vaddr(pmd_t pmd)
{
unsigned long ptr;
ptr = pmd_val(pmd) & ~(PTRS_PER_PTE * sizeof(void *) - 1);
ptr += PTRS_PER_PTE * sizeof(void *);
return __va(ptr);
}
set_pte_ext用来填充硬件PTE页表。在create_mapping中被调用,通过一个循环,被传入的物理页帧和大小以PAGE_SIZE步进,进行二级页表的计算和填充。
do {
set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)), 0);
pfn++;
} while (pte++, addr += PAGE_SIZE, addr != end);
它通过调用特定系统的pte函数完成,对于ARMv6来说,定义如下:
arch/arm/include/asm/pgtable.h #define set_pte_ext(ptep,pte,ext) cpu_set_pte_ext(ptep,pte,ext) #define set_pte_ext(ptep,pte,ext) cpu_set_pte_ext(ptep,pte,ext) arch/arm/include/asm/cpu-single.h #define cpu_set_pte_ext __cpu_fn(CPU_NAME,_set_pte_ext)
arch/arm/mm/proc-v6.S
ENTRY(cpu_v6_set_pte_ext)
#ifdef CONFIG_MMU
armv6_set_pte_ext cpu_v6
#endif
mov pc, lr
cpu_v6_set_pte_ext函数中引用了armv6_set_pte_ext宏,并传入cpu_v6参数。该宏定义如下:
arch/arm/mm/proc-macros.S .macro armv6_set_pte_ext pfx str r1, [r0], #-2048 @ linux version
根据ATPCS规则,C语言函数在调用汇编语言时,分别通过r0-r2来依次传递参数。所以这里的r0代表的是pte参数,也即二级页表的地址;r1为通过pfn_pte计算出的二级页表项;r2为0。这里的str指令首先将人r1存入r0所指向的地址,也即填充二级页表项,然后将r0的值减去2048,相当于下移了2048 / 4 = 512项。这里给出一个一二级页表的全图:

注意图中二级页表是在注册中断向量时的一个实例。注册的虚拟地址为0xffff0000,物理地址为0x50740000,大小为0x1000。传递给r0的值即为0xc0741fc0,r1的值为0x5074034b。在经过str操作之后,r0的值为0xc07417c0,相当于下移了512个页表项。
arch/arm/include/asm/pgtable-hwdef.h #define PTE_TYPE_MASK (3 << 0) #define PTE_EXT_AP0 (1 << 4) bic r3, r1, #0x000003fc bic r3, r3, #PTE_TYPE_MASK orr r3, r3, r2 orr r3, r3, #PTE_EXT_AP0 | 2
bic位清除指令首先将r1中0x3fc对应的位清0,然后对PTE_TYPE_MASK指定的最后两位清0,也即对0x3ff指定的最后11位清零,对于值为0x5074034b的r1来说,存入r3的值为0x50740000。orr按位逻辑或指令通过将r3中的值与r2位或操作放入r3,由于r2的值为0,所以r3的值此时保持不变。最后的orr将r3的值加上PTE_EXT_AP0权限位,或上2是为了指定当前是小页表(4K),此时r3的值为0x50740012。
arch/arm/include/asm/pgtable.h #define L_PTE_MT_MASK (0x0f << 2) adr ip, \pfx\()_mt_table and r2, r1, #L_PTE_MT_MASK ldr r2, [ip, r2]
adr伪指令将cpu_v6_mt_table的地址装入ip寄存器,然后取r1中0x5074034b的L_PTE_MT_MASK位作为索引值,这里为8。由于表中每一项的大小为4字节,所以[ip, 8]对应表中的第3项,也即L_PTE_MT_WRITETHROUGH。
arch/arm/include/asm/pgtable.h #define L_PTE_MT_WRITETHROUGH (0x02 << 2) /* 0010 */ /* * The ARMv6 and ARMv7 set_pte_ext translation function. * * Permission translation: * YUWD APX AP1 AP0 SVC User * 0xxx 0 0 0 no acc no acc * 100x 1 0 1 r/o no acc * 10x0 1 0 1 r/o no acc * 1011 0 0 1 r/w no acc * 110x 0 1 0 r/w r/o * 11x0 0 1 0 r/w r/o * 1111 0 1 1 r/w r/w */ .macro armv6_mt_table pfx \pfx\()_mt_table: .long 0x00 @ L_PTE_MT_UNCACHED .long PTE_EXT_TEX(1) @ L_PTE_MT_BUFFERABLE .long PTE_CACHEABLE @ L_PTE_MT_WRITETHROUGH .long PTE_CACHEABLE | PTE_BUFFERABLE @ L_PTE_MT_WRITEBACK .long PTE_BUFFERABLE @ L_PTE_MT_DEV_SHARED .long 0x00 @ unused .long 0x00 @ L_PTE_MT_MINICACHE (not present) .long PTE_EXT_TEX(1) | PTE_CACHEABLE | PTE_BUFFERABLE @ L_PTE_MT_WRITEALLOC .long 0x00 @ unused .long PTE_EXT_TEX(1) @ L_PTE_MT_DEV_WC .long 0x00 @ unused .long PTE_CACHEABLE | PTE_BUFFERABLE @ L_PTE_MT_DEV_CACHED .long PTE_EXT_TEX(2) @ L_PTE_MT_DEV_NONSHARED .long 0x00 @ unused .long 0x00 @ unused .long 0x00 @ unused .endm
首先测试二级页表项0x5074034b中的L_PTE_WRITE和L_PTE_DIRTY标志位,如果设置了L_PTE_WRITE,但没有L_PTE_DIRTY,那么设置那么设置PTE_EXT_APX到r3代表的硬件二级页表项0x50740021中。显然这里不会设置该位。
arch/arm/include/asm/pgtable.h #define L_PTE_DIRTY (1 << 6) #define L_PTE_WRITE (1 << 7) arch/arm/include/asm/pgtable-hwdef.h #define PTE_EXT_APX (1 << 9) /* v6 */ tst r1, #L_PTE_WRITE tstne r1, #L_PTE_DIRTY orreq r3, r3, #PTE_EXT_APX
如果Linux版本的二级页表项设置了L_PTE_USER标志,r3被置PTE_EXT_AP1。如果r3包含PTE_EXT_APX标志,那么同时清除PTE_EXT_APX和 PTE_EXT_AP0。
#define L_PTE_USER (1 << 8) tst r1, #L_PTE_USER orrne r3, r3, #PTE_EXT_AP1 tstne r3, #PTE_EXT_APX bicne r3, r3, #PTE_EXT_APX | PTE_EXT_AP0
如果r1没有L_PTE_EXEC标志,则设置PTE_EXT_XN。
tst r1, #L_PTE_EXEC orreq r3, r3, #PTE_EXT_XN orr r3, r3, r2
然后再加上L_PTE_MT_WRITETHROUGH标志。然后根据L_PTE_YOUNG标志,确定是否加上L_PTE_PRESENT标志。
tst r1, #L_PTE_YOUNG tstne r1, #L_PTE_PRESENT moveq r3, #0 str r3, [r0] mcr p15, 0, r0, c7, c10, 1 @ flush_pte .endm
str指令将最终的硬件PTE页表值存放到低地址的二级页表中。所以硬件使用的二级页表总是位于低地址处,而高地址处的512项PTE是留给Linux自己使用的。
| 上一页 | 下一页 | |
| 11. 内核初始化2 | 起始页 | 13. 内存管理 |















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









