







gbdt(又称Gradient Boosted Decision Tree/Grdient Boosted Regression Tree),是一种迭代的决策树算法,该算法由多个决策树组成。它最早见于yahoo,后被广泛应用在搜索排序、点击率预估上。
xgboost是陈天奇大牛新开发的Boosting库。它是一个大规模、分布式的通用Gradient Boosting(GBDT)库,它在Gradient Boosting框架下实现了GBDT和一些广义的线性机器学习算法。
本文首先讲解了gbdt的原理,分析了代码实现;随后分析了xgboost的原理和实现逻辑。本文的目录如下:
一、GBDT
1. GBDT简介
2. GBDT公式推导
3. 优缺点
4. 实现分析
5. 常用参数和调优
二、Xgboost
1. Xgboost简介
2. Xgboost公式推导
3. 优缺点
4. 实现分析
5. 常用参数和调优
一、GBDT/GBRT
1. GBDT简介
GBDT是一个基于迭代累加的决策树算法,它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。
树模型也分为决策树和回归树,决策树常用来分类问题,回归树常用来预测问题。决策树常用于分类标签值,比如用户性别、网页是否是垃圾页面、用户是不是作弊;而回归树常用于预测真实数值,比如用户的年龄、用户点击的概率、网页相关程度等等。由于GBDT的核心在与累加所有树的结果作为最终结果,而分类结果对于预测分类并不是这么的容易叠加(稍等后面会看到,其实并不是简单的叠加,而是每一步每一棵树拟合的残差和选择分裂点评价方式都是经过公式推导得到的),所以GBDT中的树都是回归树(其实回归树也能用来做分类的哈)。同样的我们经常会把RandomForest的思想引入到GBDT里面来,即每棵树建树的时候我们会对特征和样本同时进行采样,然后对采样的样本和特征进行建树。
好啦,既然每棵树拟合的值、预测值、分裂点选取都不是随便选取的,那么到底是如何选择的呢?我们先进入GBDT的公式推导吧
2. GBDT公式推导
我们都知道LR的映射函数是,损失函数是
。对于分类问题来说,我们一般选取映射函数,构造损失函数,然后逐步求解使得损失函数最小化就行了,可是对于回归问题,求解的方式就有些不同了。那么GBDT的目标函数和损失函数分别又是什么的呢?每个树拟合的残差是什么呢?首先GBDT和LR是不一样的,因为GBDT是希望组合一组弱的学习器的线性组合,于是我们有:
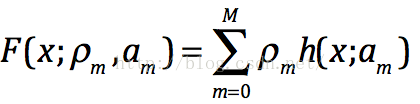
那么它的目标函数就如下,其中如上公式中是p步长,而h(x;am)是第m颗树的预测值---梯度方向。我们可以在函数空间上形式使用梯度下降法求解,首先固定x,对F(x)求其最优解。下面给出框架流程和Logloss下的推导,框架流程如下:
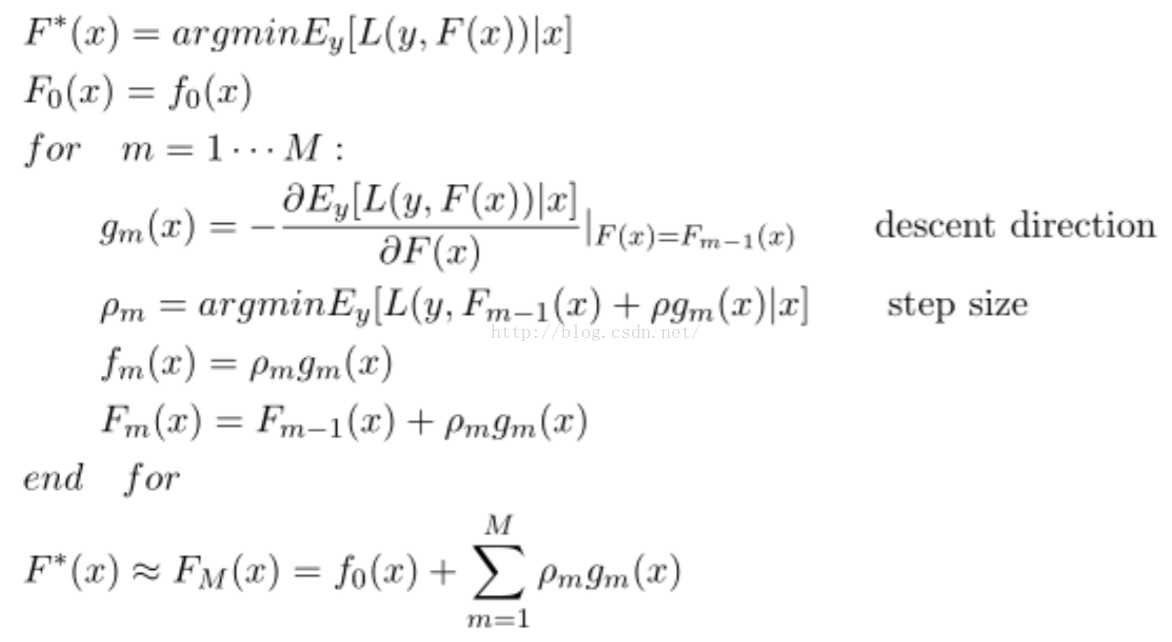
我们需要估计g_m(x),这里使用决策树实现去逼近g_m(x),使得两者之间的距离尽可能的近。而距离的衡量方式有很多种,比如均方误差和Logloss误差。我在这里给出Logloss损失函数下的具体推导:
(GBDT预测值到输出概率[0,1]的sigmoid转换)
下面,我们需要首先求解F0,然后再求解每个梯度。
Step 1. 首先求解初始值F0,令其偏导为0。(实现时是第1颗树需要拟合的残差)
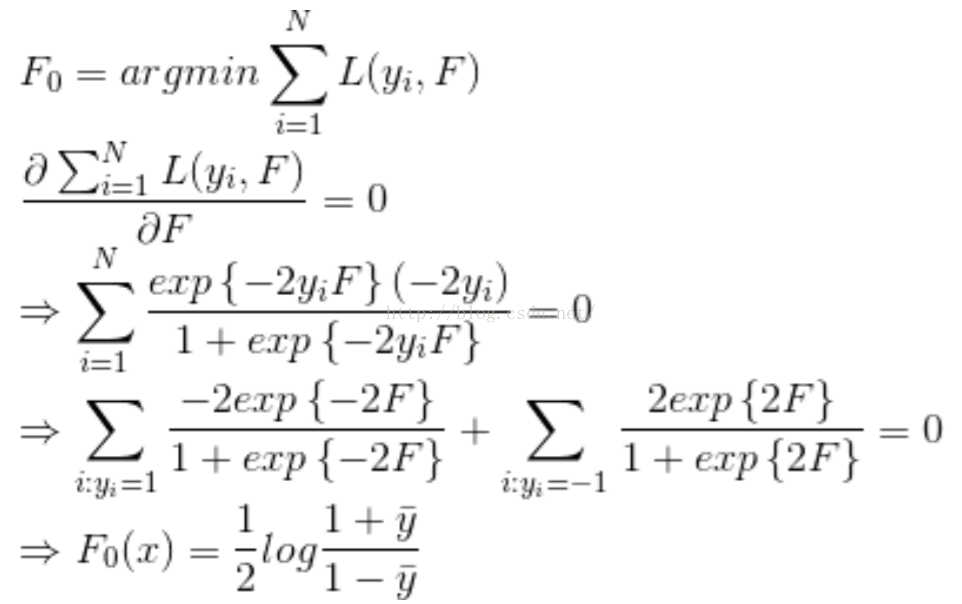
Step2. 估计g_m(x),并用决策树对其进行拟合。g_m(x)是梯度,实现时是第m颗树需要拟合的残差:
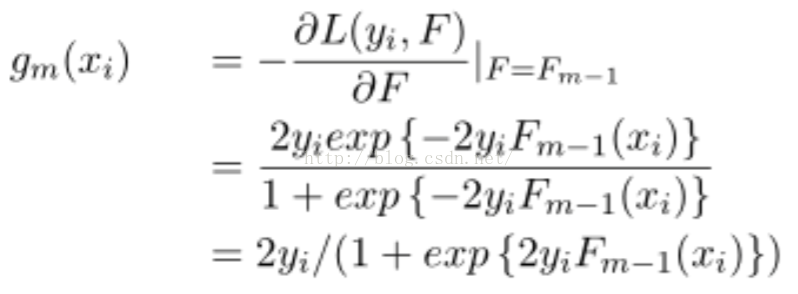
Step3. 使用牛顿法求解下降方向步长。r_jm是拟合的步长,实现时是每棵树的预测值:
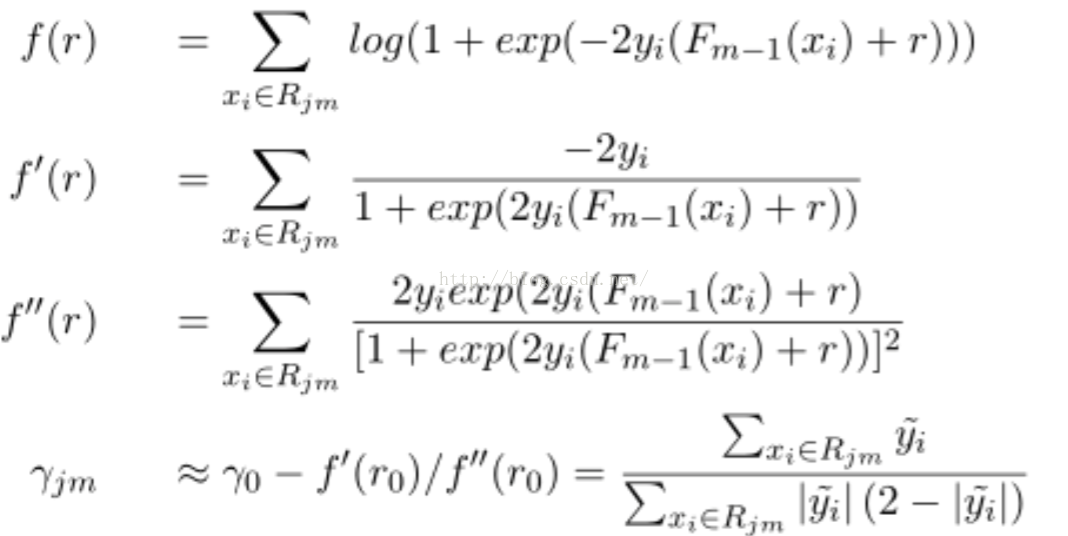
Step4. 预测时就很简单啦,把每棵树的预测值乘以缩放因子加到一起就得到预测值啦:
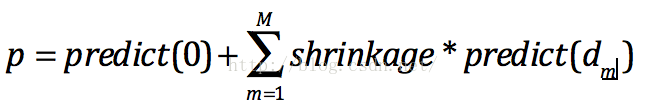
注意如果需要输出的区间在(0,1)之间,我们还需要做如下转换:
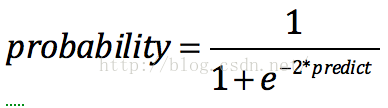
3. 优缺点
GBDT的优点当然很明显啦,它的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。
GBDT的缺点也很明显,Boost是一个串行过程,不好并行化,而且计算复杂度高,同时不太适合高维洗漱特征。
4. 实现分析
5. 参数和模型调优
GBDT常用的参数有如下几个:
1. 树个数
2. 树深度
3. 缩放因子
4. 损失函数
5. 数据采样比
6. 特征采样比
二、Xgboost
xgboost是boosting Tree的一个很牛的实现,它在最近Kaggle比赛中大放异彩。它 有以下几个优良的特性:
1. 显示的把树模型复杂度作为正则项加到优化目标中。
2. 公式推导中用到了二阶导数,用了二阶泰勒展开。(GBDT用牛顿法貌似也是二阶信息)
3. 实现了分裂点寻找近似算法。
4. 利用了特征的稀疏性。
5. 数据事先排序并且以block形式存储,有利于并行计算。
6. 基于分布式通信框架rabit,可以运行在MPI和yarn上。(最新已经不基于rabit了)
7. 实现做了面向体系结构的优化,针对cache和内存做了性能优化。
在项目实测中使用发现,Xgboost的训练速度要远远快于传统的GBDT实现,10倍量级。
1. 原理
在有监督学习中,我们通常会构造一个目标函数和一个预测函数,使用训练样本对目标函数最小化学习到相关的参数,然后用预测函数和训练样本得到的参数来对未知的样本进行分类的标注或者数值的预测。一般目标函数是如下形式的,我们通过对目标函数最小化,求解模型参数。预测函数、损失函数、正则化因子在不同模型下是各不相同的。

其中预测函数有如下几种形式:
1. 普通预测函数
a. 线性下我们的预测函数为:
b. 逻辑回归下我们的预测函数为:
2. 损失函数:
a. 平方损失函数:
b. Logistic损失函数:
3. 正则化:
a. L1 参数求和
b. L2 参数平方求和
其实我个人感觉Boosting Tree的求解方式和以上略有不同,Boosting Tree由于是回归树,一般是构造树来拟合残差,而不是最小化损失函数。且看GBDT情况下我们的预测函数为:
而Xgboost引入了二阶导来进行求解,并且引入了节点的数目、参数的L2正则来评估模型的复杂度。那么Xgboost是如何构造和预测的呢?
首先我们给出结果,Xgboost的预测函数为:
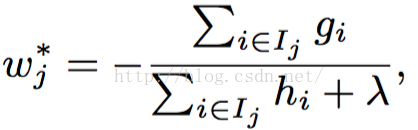
而目标函数为:
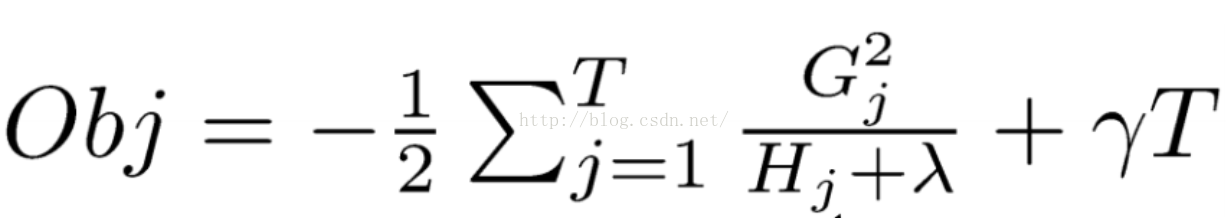
那么作者是如何构思得到这些预测函数和优化目标的呢?它们又如何求解得到的呢? 答案是作者巧妙的利用了泰勒二阶展开和巧妙的定义了正则项,用求解到的数值作为树的预测值。

我们定义正则化项:
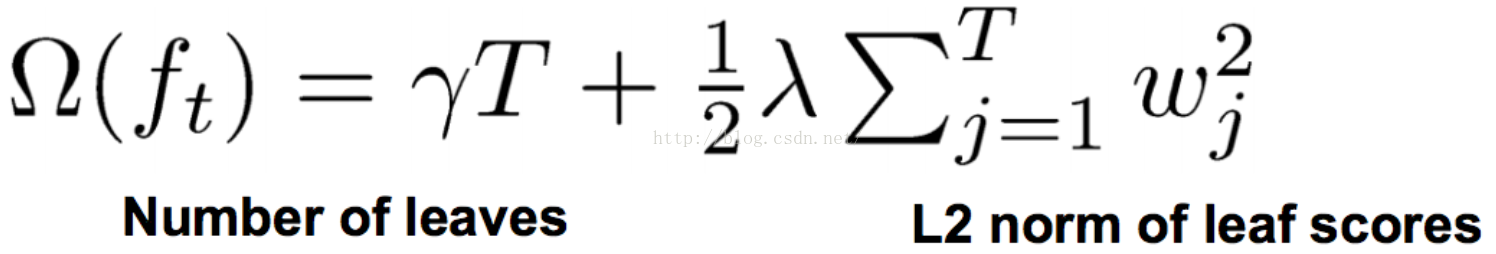
可以得到目标函数转化为:
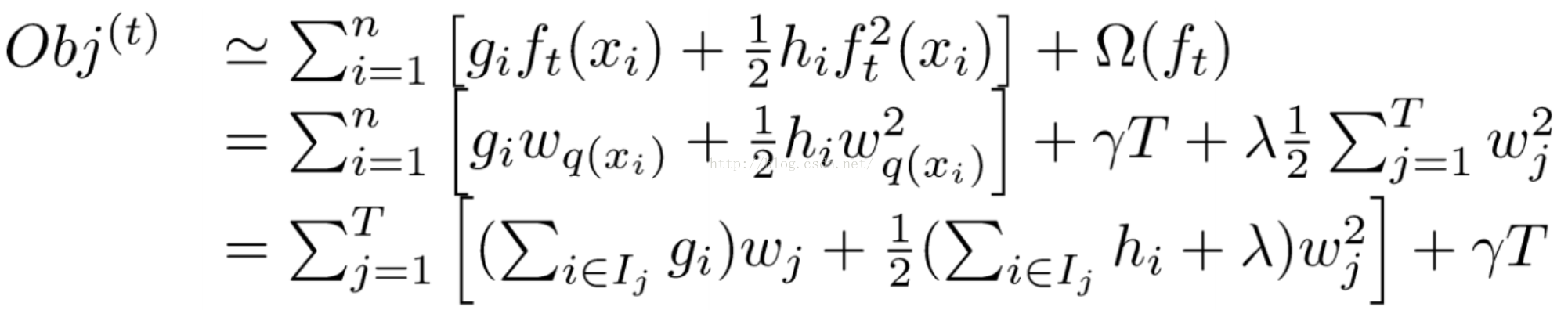
然后就可以求解得到:

同样在分裂点选择的时候也,以目标函数最小化为目标。
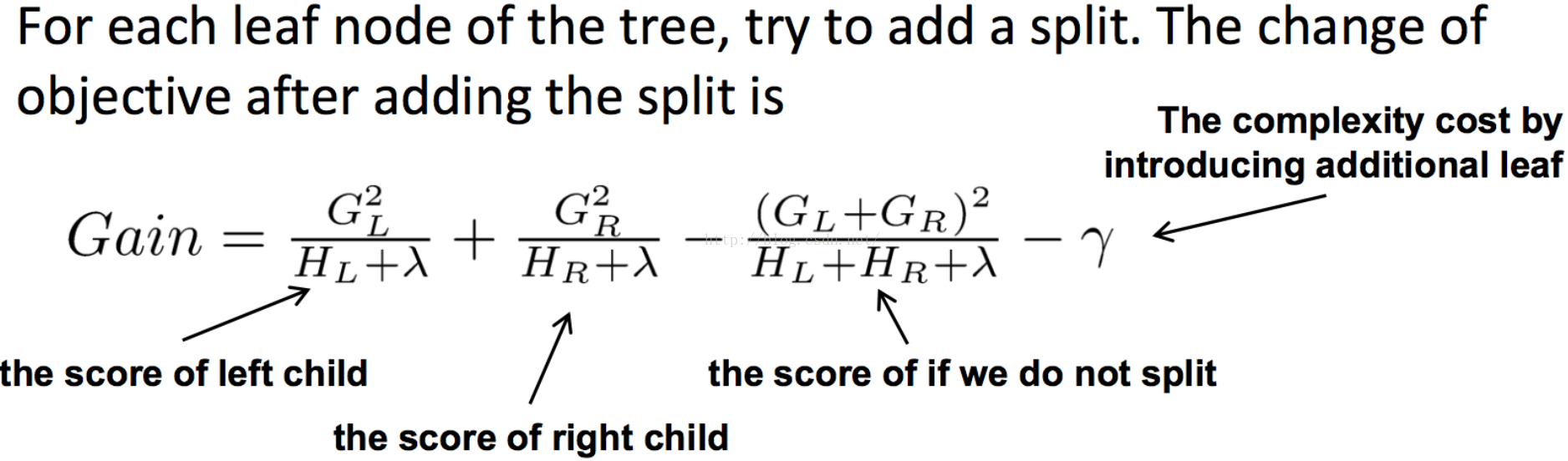
2. 实现分析:
3. 参数调优:
a. 初阶参数调优:
1). booster
2). objective
3). eta
4). gamma
5). min_child_weight
6). max_depth
7). colsample_bytree
8). subsample
9). num_round
10). save_period
参考文献:
1. xgboost导读和实践:http://vdisk.weibo.com/s/vlQWp3erG2yo/1431658679
2. GBDT(MART) 迭代决策树入门教程: http://blog.csdn.net/w28971023/article/details/8240756
3. Introduction to Boosted Trees : https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
4. xgboost: https://github.com/dmlc/xgboost














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









