







MEMORY MANAGEMENT
The part of the operating system that manages (part of) the memory hierarchy is called thememory manager
这章感觉有点多。。。80 多页。。看完都看了两天多,做笔记就更有点不想。。。有点懒了。。但是要坚持下去,可以自己较劲
对于内存的抽象,最简单的抽象就是。。。没有抽象
和第一次看不一样,把summary放在最前面,对整个mamory management的行文有个很好的了解
//-------------------------------------------------------------------------------------------------------------------
SUMMARY
In this chapter we have examined memory management. We saw that the simplest systems do not swap or page at all. Once a program is loaded into mem-ory, it remains there in place until it finishes. Some operating systems allow only one process at a time in memory, while others support multiprogramming. The next step up is swapping. When swapping is used, the system can handle more processes than it has room for in memory. Processes for which there is no room are swapped out to the disk. Free space in memory and on disk can be kept
track of with a bitmap or a hole list.
Modern computers often have some form of virtual memory. In the simplest form, each process' address space is divided up into uniform-sized blocks called pages, which can be placed into any available page frame in memory. There are many page replacement algorithms; two of the better algorithms are aging and
WSClock.
Paging systems can be modeled by abstracting the page reference string from the program and using the same reference string with different algorithms. These models can be used to make some predictions about paging behavior. To make paging systems work well, choosing an algorithm is not enough; attention to such issues as determining the working set, memory allocation policy, and page size is required.
Segmentation helps in handling data structures that change size during execu-tion and simplifies linking and sharing. It also facilitates providing different pro-tection for different segments. Sometimes segmentation and paging are combined to provide a two-dimensional virtual memory. The MULTICS system and the
Intel Pentium support segmentation and paging.
//-------------------------------------------------------------------------------------------------------------------
3.1 NO MEMORY ABSTRACTION
The simplest memory abstraction is no abstraction at all.
Even with the model of memory being just physical memory, several options are possible
The first model was formerly used on mainframes and minicomputers but is rarely used any more. The second model is used on some handheld computers and embedded systems. The third model was used by early personal computers (e.g., running MS-DOS), where the portion of the system in the ROM is called the BIOS
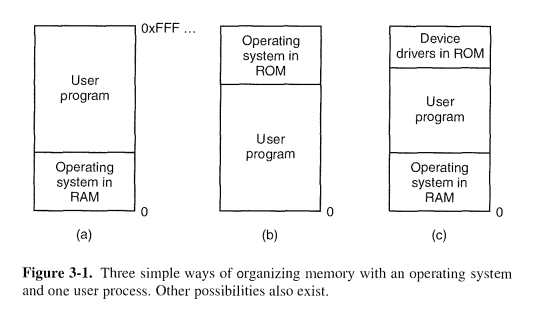
Running Multiple Programs Without a Memory Abstraction
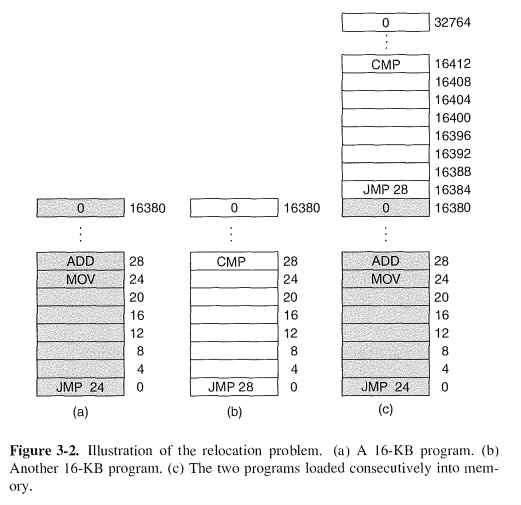
A B两个进程如果同时在内存中跑的话,由于没有抽象地址,用的都是绝对地址,B的JMP 28就会跳转到A的指令内部,从而相互干扰,这是我们不希望看到的。绝对地址在程序中的使用可能造成了进程之间的相互干扰。
The core problem here is that the two programs both reference absolute physi-cal memory. That is not what we want at all. We want each program to reference a private set of addresses local to it.
3.2 A MEMORY ABSTRACTION: ADDRESS SPACES
Exposing physical memory to processes has several major draw-backs:
First, if user programs can address every byte of memory, they can easily trash the operating system, intentionally or by accident, bringing the system to a grinding halt
Second, with this model, it is difficult to have multiple programs running atonce (taking turns, if there is only one CPU).
没有抽象地址空间,系统可能会因为同时运行多个进程而挂掉(进程之间相互影响)。
为了避免进程之间相互影响,这时候就只好每次在内存里面只载入一个进程,而这又使得硬件的利用效率底下。
于是。。。我们就得想些法子解决这些问题。肿么破?抽象地址空间
3.2.1 The Notion of an Address Space
Two problems have to be solved to allow multiple applications to be in mem-ory at the same time without their interfering with each other: protection and relocation
An address space is the set of addresses that a process can use to address memory.
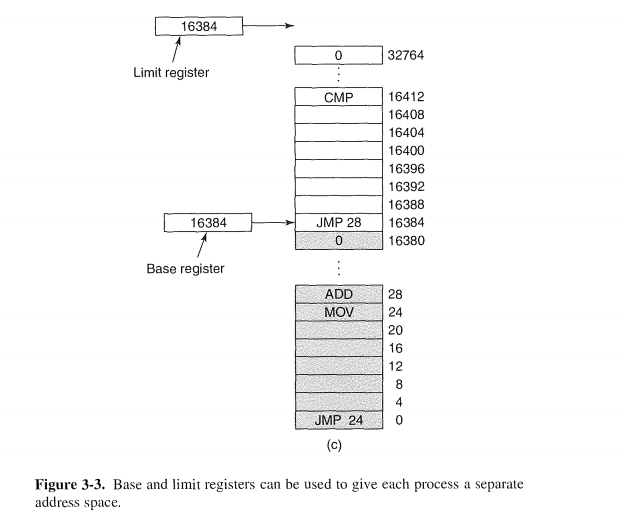
Base and Limit Registers
This simple solution uses a particularly simple version of dynamic relocation.
The classical solution, which was used on ma-chines ranging from the CDC 6600 (the world's first supercomputer) to the Intel 8088 (the heart of the original IBM PC), is to equip each CPU with two special
hardware registers, usually called the base and limit registers.
When a process is run, the base register is loaded with the physical address where its program begins in memory and the limit register is loaded with the length of the program
Every time a process references memory, either to fetch an instruction or read or write a data word, the CPU hardware automatically adds the base value to the address generated by the process before sending the address out on the memory bus.
A disadvantage of relocation using base and limit registers is the need to per-form an addition and a comparison on every memory reference. Comparisons can be done fast, but additions are slow due to carry propagation time unless special addition circuits are used.
3.2.2 Swapping
书后面的练习题第一题就问了
In Fig. 3-3 the base and limit registers contain the same value, 16,384. Is this just an
accident, or are they always the same? If this is just an accident, why are they the
same in this example?
这仅仅是偶然。。。
1. It is an accident. The base register is16,384 becausethe program happened to
be loaded at address 16,384. It could have been loaded anywhere. The limit
register is 16,384 because the program contains 16,384 bytes. It could have
been any length. That the load address happens to exactly match the program
length is pure coincidence.
The simplest strategy, called swapping,consists of bringing in each process in its entirety, running it for a while, then putting it back on the disk.
The operation of a swapping system is illustrated in Fig. 3-4
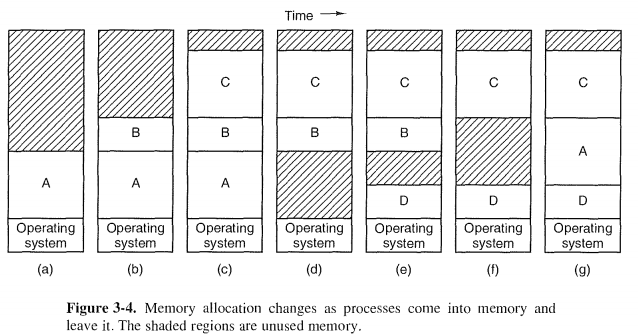
When swapping creates multiple holes in memory, it is possible to combine them all into one big one by moving all the processes downward as far as pos-sible. This technique is known as memory compaction. It is usually not done be-cause it requires a lot of CPU time.
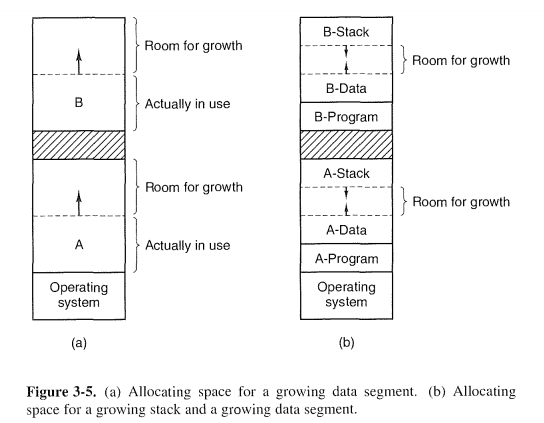
上面是两种进程占用内存空间生长的方案
The memory between them can be used for either segment. If it runs out, the process will either have to be moved to a hole with sufficient space, swapped out of memory until a large enough hole can be created, or killed.
3.2.3 Managing Free Memory
In general terms, there are two ways to keep track of memory usage: bitmaps and free lists.
Memory Management with Bitmaps
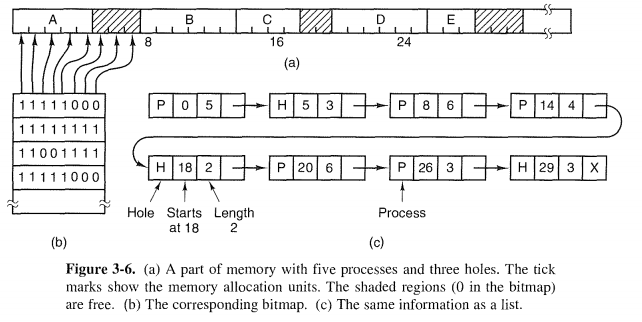
Memory Management with Linked Lists
The simplest algorithm is first fit. The memory manager scans along the list of segments until it finds a hole that is big enough. The hole is then broken up into two pieces, one for the process and one for the unused memory, except in the statistically unlikely case of an exact fit.
First fit is a fast algorithm because it searches as little as possible. A minor variation of first fit isnext fit. It works the same way as first fit, ex-cept that it keeps track of where it is whenever it finds a suitable hole. The next
time it is called to find a hole, it starts searching the list from the place where it left off last time, instead of always at the beginning, as first fit does. Simulations by Bays (1977) show that next fit gives slightly worse performance than first fit.
Another well-known and widely used algorithm is best fit.Best fit searches the entire list, from beginning to end, and takes the smallest hole that is adequate.
Worst fit, that is, always take the largest available hole, so that the new hole will be big enough to be useful.
With a hole list sorted by size, first fit and best fit are equally fast, and next fit is pointless.
Yet another allocation algorithm is quick fit, which maintains separate lists for some of the more common sizes requested. For example, it might have a table with fa entries, in which the first entry is a pointer to the head of a list of 4-KB holes, the second entry is a pointer to a list of 8-KB holes, the third entry a pointer to 12-KB holes, and so on. Holes of, say, 21 KB, could be put on either the 20-KB list or on a special list of odd-sized holes.
书后面有个题目,关于这几种fit方案的
Consider a swapping system in which memory consists of the following hole sizes in memory order: 10 KB, 4 KB, 20 KB, 18 KB, 7 KB, 9 KB, 12 KB, and 15 KB. Which hole is taken for successive segment requests of
(a) 12 KB
(b)10 KB
(c)9 KB
for first fit? Now repeat the question for best fit, worst fit, and next fit.
Answer:
First fit takes 20 KB, 10 KB, 18 KB. Best fit takes 12 KB, 10 KB, and 9 KB.Worst fit takes 20 KB, 18 KB, and 15 KB. Next fit takes 20 KB, 18 KB, and 9KB.
如果没看懂答案就反复看上面的定义就可以了。。。。
3.3 VIRTUAL MEMORY
虚拟内存在我目前的理解来看,它是为了解决内存不够用而出现的。
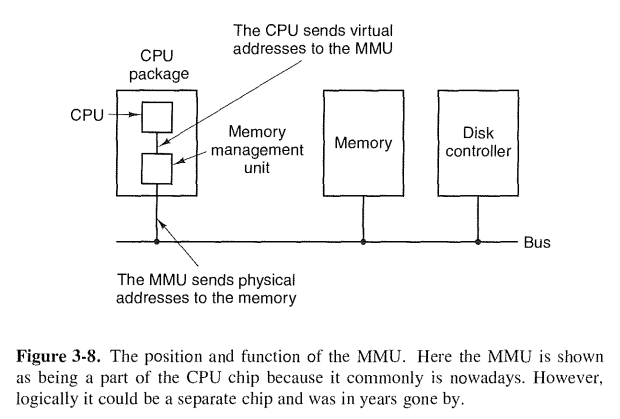
While base and limit registers can be used to create the abstraction of address spaces, there is another problem that has to be solved: managing bloatware.
程序越来越大,对于内存的需求越来越大。然而当内存不够用的时候怎么办呢?
CPU在某一个特定的时刻只会执行一个指令,那么总有一部分当前进程的内存区域是不会用的,那么把它先从RAM移出去,移动到swap里面,接着把准备使用的数据移入到空出来的内存中,有点拆东墙补西墙的意思。
最简单的例子就是一列火车长500米(具体多长我也布吉岛。。呵呵),现在仅仅只有1000米的火车轨道,怎么让这列火车从上海开到北京。就是把刚驶过的车轨移到火车前面!
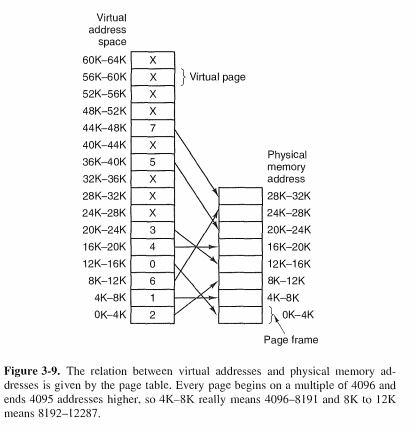
The basic idea behind virtual memory is that each program has its own address space, which is broken up into chunks called pages. Each page is a contiguous range of addresses. These pages are mapped onto physical memory, but not all pages have to be in physical memory to run the program.
3.3.1 Paging
The virtual address space is divided into fixed-size units called pages. The corresponding units in the physical memory are called page frames.
The MMU notices that the page is unmapped (indicated by a cross in the figure) and causes the CPU to trap to the operating system. This trap is called a page fault. The operating sys-tem picks a little-used page frame and writes its contents back to the disk (if it is not already there). It then fetches the page just referenced into the page frame just freed, changes the map, and restarts the trapped instruction.
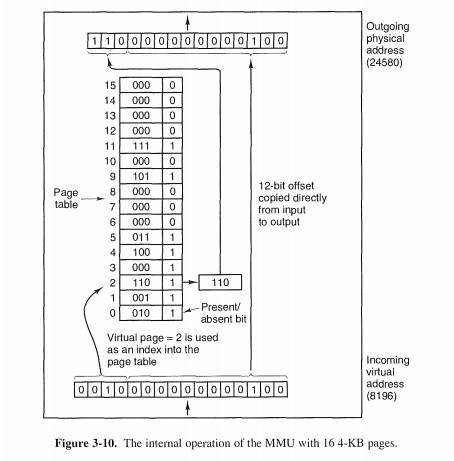
3.3.2 Page Tables
The mapping of virtual addresses onto physical addresses can be summarized as follows: the virtual address is split into a virtual page number (high-order bits) and an offset (low-order bits).
Structure of a Page Table Entry
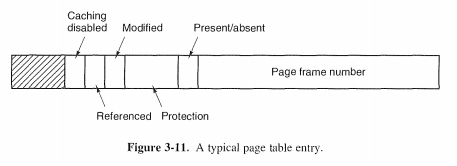
http://blog.csdn.net/cinmyheart/article/details/24354735
可以参考这里面的分页机制
3.3.3 Speeding Up Paging
1. The mapping from virtual address to physical address must be fast.
2. If the virtual address space is large, the page table will be large.
The first point is a consequence of the fact that the virtual-to-physical map-ping must be done on every memory reference
The second point follows from the fact that all modern computers use virtual addresses of at least 32 bits, with 64 bits becoming increasingly common.
And remember that each process needs its own page table (because it has its own virtual address space).
During process execution, no more memory references are needed for the page table. The advantages of this method are that it is straightforward and requires no memory references during mapping
注意,这里是进程运行的时候不会有和page table有关的内存读写,而不是其他普通数据的读写。内存映射是在进程创建之初就已经映射好了的
Translation Lookaside Buffers
TLB这家伙完全可以看成一个专门为了page table而生的硬件buffer,没啥其他好说的
When software TLB management is used, it is essential to understand the dif-ference between two kinds of misses. A soft miss occurs when the page refer-enced is not in the TLB, but is in memory. All that is needed here is for the TLB to be updated
In contrast, a hard miss occurs when the page itself is not in memory (and of course, also not in the TLB). A disk access is required to bring in the page, which takes several milliseconds. A hard miss is easily a million times slower than a soft miss.
3.3.4 Page Tables for Large Memories
Multilevel Page Tables
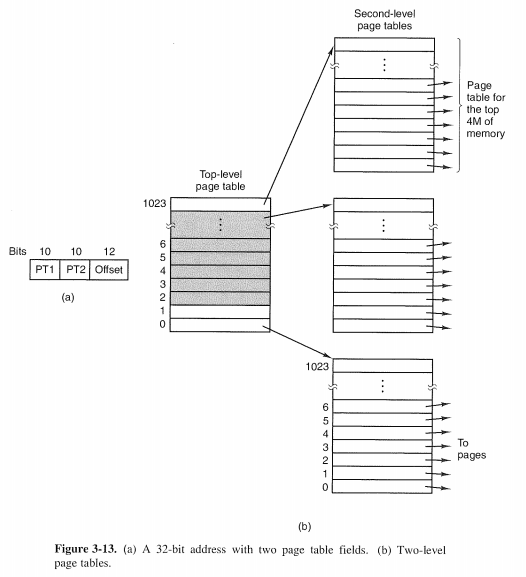
通过多级page可以降低page的数目,减少由于page而产生的不必要的内存消耗
Inverted Page Tables
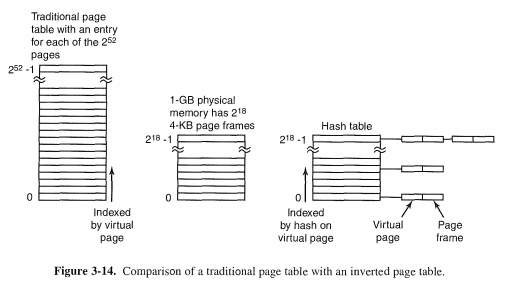
3.4 PAGE REPLACEMENT ALGORITHMS
讲了N种实现算法,最优的还是最后一个
3.4.9 The WSClock Page Replacement Algorithm
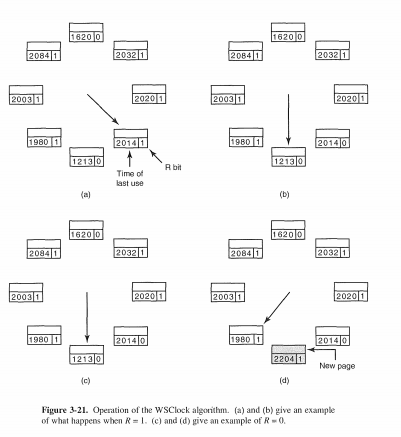
环形双向列表实现。
如果找到clean page,并且age大于给定的时间常数,那么这个page就会被写到swap里面去。空出内存空间为正准备进入内存的page做准备。
What happens if the hand comes all the way around to its starting point?
There are two cases to consider:
1. At least one write has been scheduled.
2. No writes have been scheduled.
In the first case,
the hand just keeps moving, looking for a clean page. Since one or more writes have been scheduled, eventually some write will complete and its page will be marked as clean. The first clean page encountered is evicted. This page is not necessarily the first write scheduled because the disk driver may reorder writes in order to optimize disk performance.
In the second case,
all pages are in the working set, otherwise at least one write would have been scheduled. Lacking additional information, the simplest thing to do is claim any clean page and use it. The location of a clean page could be kept track of during the sweep. If no clean pages exist, then the current page is chosen as the victim and written back to disk.
To reduce disk traffic, a limit might be set, allowing a maximum of pages to be written back.
3.5 DESIGN ISSUES FOR PAGING SYSTEMS
3.5.1 Local versus Global Allocation Policies
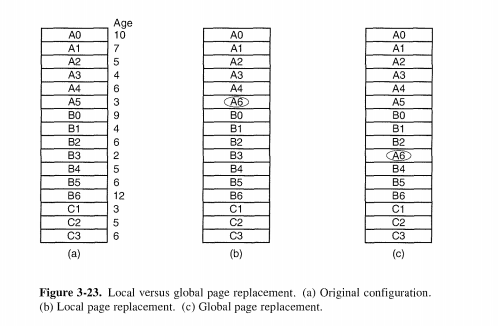
勘误:
其实这里不应该是age,而是referenced times,如果是age,被写出的应该是age数值最大的,而不是最小的。错误很明显。可能是作者的疏漏吧,同样,有其他读者发现了这个问题。这个《modern operating system》每个勘误表,怎么说都感觉不完美。
3.5.4 Separate Instruction and Data Spaces
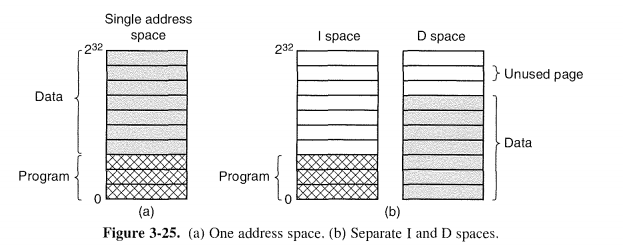
有这两种方案。
update:2014.06.13
之前一直任务0.12的内核是数据和代码不是分离的,其实错了。今天和@凯旋冲锋 讨论的时候,被指出,只要是虚拟抽象空间使用的时候分离就可以了,物理上,无所谓。内存的使用每次都是以page为单位的。物理上,也不一定连续。
3.5.5 Shared Pages
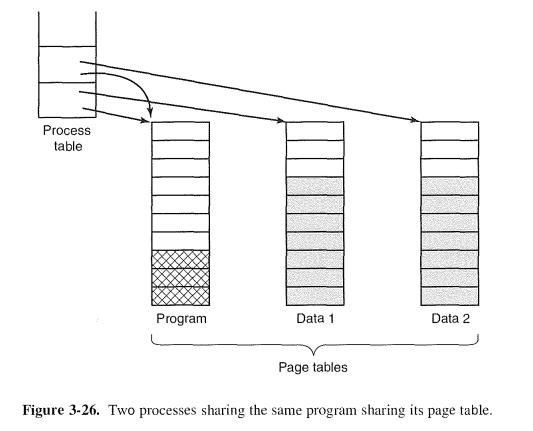
共享data page实现数据共享。如果两个进程都没有对共享数据进行写操作的话,可以不用copy出两份相同的数据page,利用COW即可
3.5.6 Shared Libraries
共享库绝对是光辉思想的代表。
Depending on the system and the confi-guration details, shared libraries are loaded either when the program is loaded or when functions in them are called for the first time. Of course, if another program has already loaded the shared library, there is no need to load it again—that is the whole point of it.
In addition to making executable files smaller and saving space in memory, shared libraries have another advantage: if a function in a shared library is up-dated to remove a bug, it is not necessary to recompile the programs that call it. The old binaries continue to work.
3.5.7 Mapped Files
If two or more processes map onto the same file at the same time, they can communicate over shared memory. Writes done by one process to the shared memory are immediately visible when the other one reads from the part of its vir-tual address spaced mapped onto the file.
3.5.8 Cleaning Policy
At the very least, the paging daemon ensures that all the free frames are clean, so they need not be writ-ten to disk in a big hurry when they are required.
3.6 IMPLEMENTATION ISSUES
3.6.1 Operating System Involvement with Paging
There are four times when the operating system has paging-related work to do: process creation time, process execution time, page fault time, and process termination time
When a process is scheduled for execution, the MMU has to be reset for the new process and the TLB flushed, to get rid of traces of the previously executing process.
the pages in memory and on disk can only be released when the last process using them has terminated.
3.6.2 Page Fault Handling
We are finally in a position to describe in detail what happens on a page fault.
The sequence of events is as follows:
1. The hardware traps to the kernel, saving the program counter on thestack. On most machines, some information about the state of thecurrent instruction is saved in special CPU registers.
2. An assembly code routine is started to save the general registers and other volatile information, to keep the operating system from destroying it. This routine calls the operating system as a procedure.
3. The operating system discovers that a page fault has occurred, and tries to discover which virtual page is needed. Often one of the hardware registers contains this information. If not, the operating system
must retrieve the program counter, fetch the instruction, and parse it in software to figure out what it was doing when the fault hit.
4. Once the virtual address that caused the fault is known, the system checks to see if this address is valid and the protection consistent with the access. If not, the process is sent a signal or killed. If the
address is valid and no protection fault has occurred, the system checks to see if a page frame is free. If no frames are free, the page replacement algorithm is run to select a victim.
5. If the page frame selected is dirty, the page is scheduled for transfer to the disk, and a context switch takes place, suspending the faulting process and letting another one run until the disk transfer has com-
pleted. In any event, the frame is marked as busy to prevent it from being used for another purpose.
6. As soon as the page frame is clean (either immediately or after it is written to disk), the operating system looks up the disk address where the needed page is, and schedules a disk operation to bring it in. While the page is being loaded, the faulting process is still suspended and another user process is run, if one is available.
7. When the disk interrupt indicates that the page has arrived, the page tables are updated to reflect its position, and the frame is marked as being in normal state.
8. The faulting instruction is backed up to the state it had when it began and the program counter is reset to point to that instruction.
9. The faulting process is scheduled, and the operating system returns to the (assembly language) routine that called it.
10. This routine reloads the registers and other state information and re- turns to user space to continue execution, as if no fault had occurred.
3.6.4 Locking Pages in Memory
Locking a page is often called pinning it in memory. Another solution is to do all I/O to kernel buffers and then copy the data to user pages later.
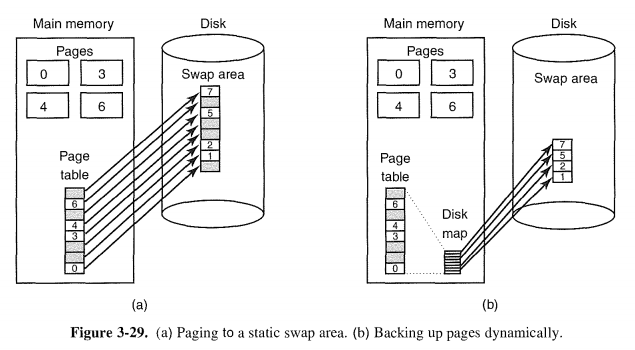
3.6.5 Backing Store
When the system is booted, this swap partition is empty and is represented in memory as a single entry giving its origin and size.
Calculating the address to write a page to becomes simple: just add the offset of the page within the virtual address space to the start of the swap area.
3.6.6 Separation of Policy and Mechanism
Here the memory management system is divided into three parts:
1. A low-level MMU handler.
2. A page fault handler that is part of the kernel.
3. An external pager running in user space.
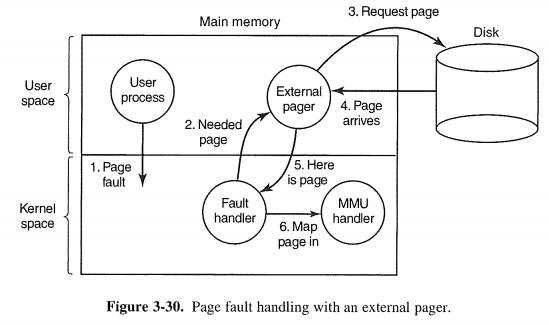
Once the process starts running, it may get a page fault. The fault handler fig-ures out which virtual page is needed and sends a message to the external pager, telling it the problem. The external pager then reads the needed page in from the disk and copies it to a portion of its own address space. Then it tells the fault handler where the page is.
我始终不明白,为嘛后面才讲分段机制。。。。
3.7 SEGMENTATION
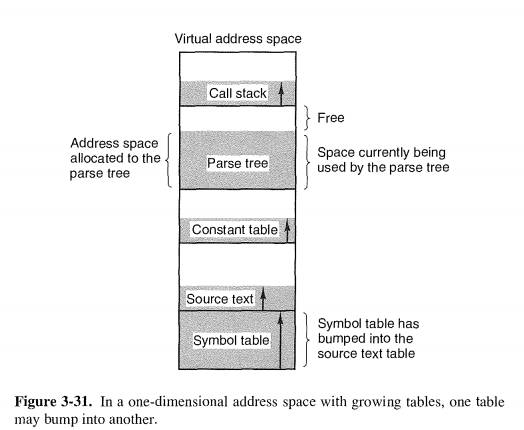
A straightforward and extremely general solution is to provide the machine with many completely independent address spaces, called segments. Each seg-ment consists of a linear sequence of addresses, from 0 to some maximum.
Moreover, segment lengths may change during execution.
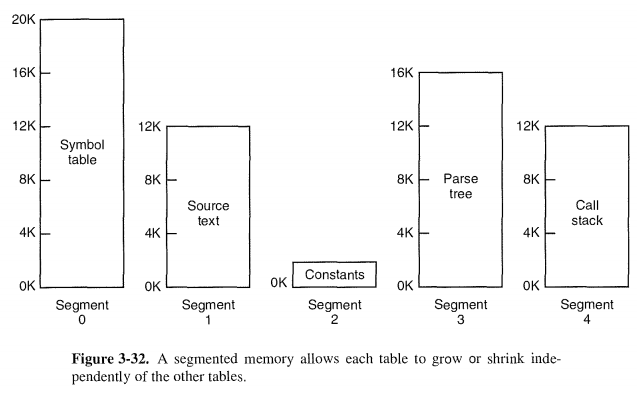
Since each segment contains only a single type of object, the segment can have the protection appropriate for that particular type.
3.7.1 Implementation of Pure Segmentation
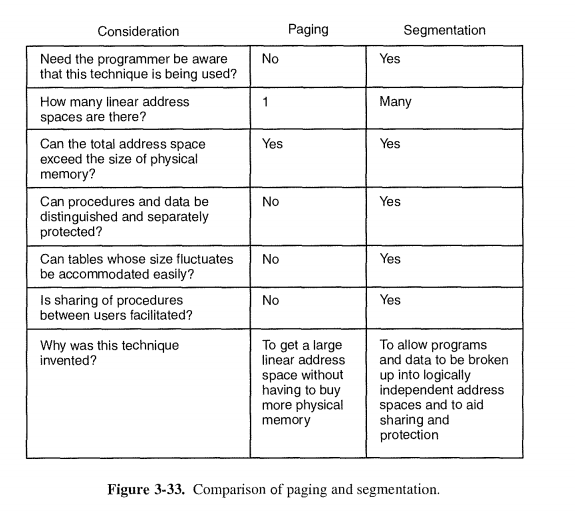
3.7.2 Segmentation with Paging: MULTICS
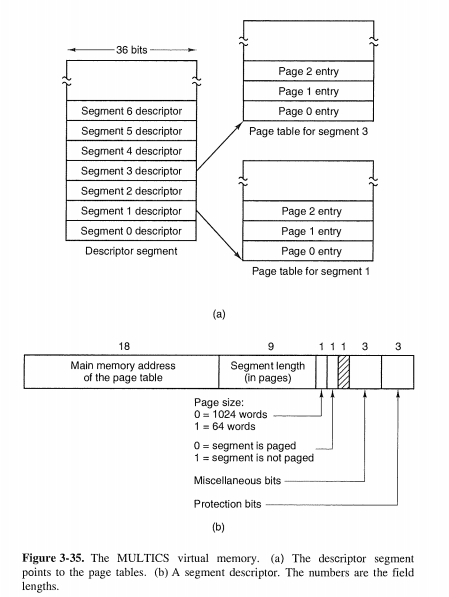
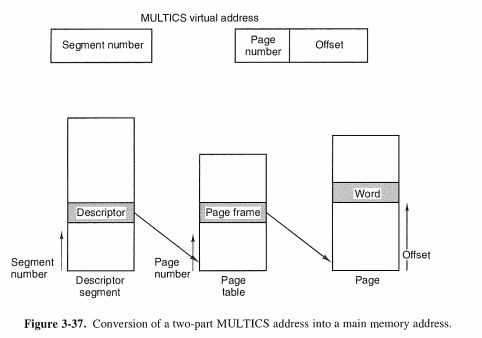
Intel采用了两种机制的结合。。。。终于到重点了。。。。
3.7.3 Segmentation with Paging: The Intel Pentium
The heart of the Pentium virtual memory consists of two tables, called the LDT (Local Descriptor Table) and the GDT (Global Descriptor Table).
这里还是赵炯博士的《注释》讲的比较细一点
http://blog.csdn.net/cinmyheart/article/details/24354735
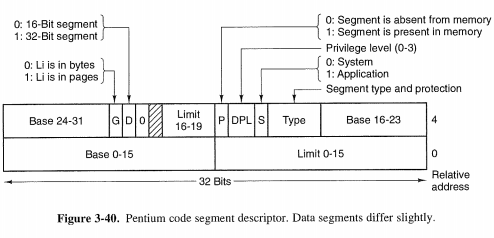
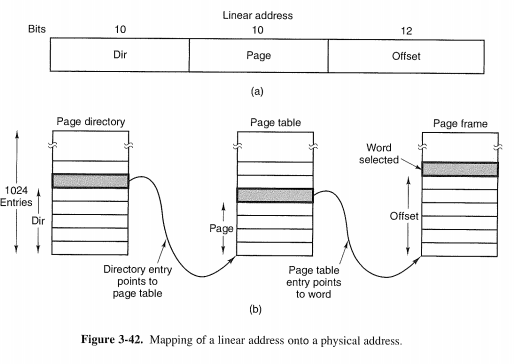
linear address divided into three fields, Dir, Page, and Offset. The Dir field is used to index into the page directory to locate a point-er to the proper page table. Then the Page field is used as an index into the page table to find the physical address of the page frame. Finally, Offset is added to the address of the page frame to get the physical address of the byte or word needed.
此blog仅作为个人复习“恢复记忆”用
笔记,是为了更好的感悟
















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









