









长短时记忆网络(Long Short Term Memory (LSTM))
LSTM 模型
LSTM模型是RNN 模型的改进,可以避免梯度消失的问题,有更长的记忆。
LSTM也是一种循环神经网络,每当读取一个输入x就会更新状态h。LSTM的结构比简单RNN要复杂很多,简单RNN只有一个参数矩阵,LSTM有四个参数矩阵。下面我们具体来看LSTM的内部结构。

LSTM最重要的设计是传输带,记为向量
C
C
C,过去的信息通过传送带直接送到下一个时刻,不会发生太大的变化,LSTM就是靠传输带来避免梯度消失的问题。

LSTM中有很多gate,可以有选择的让信息通过。
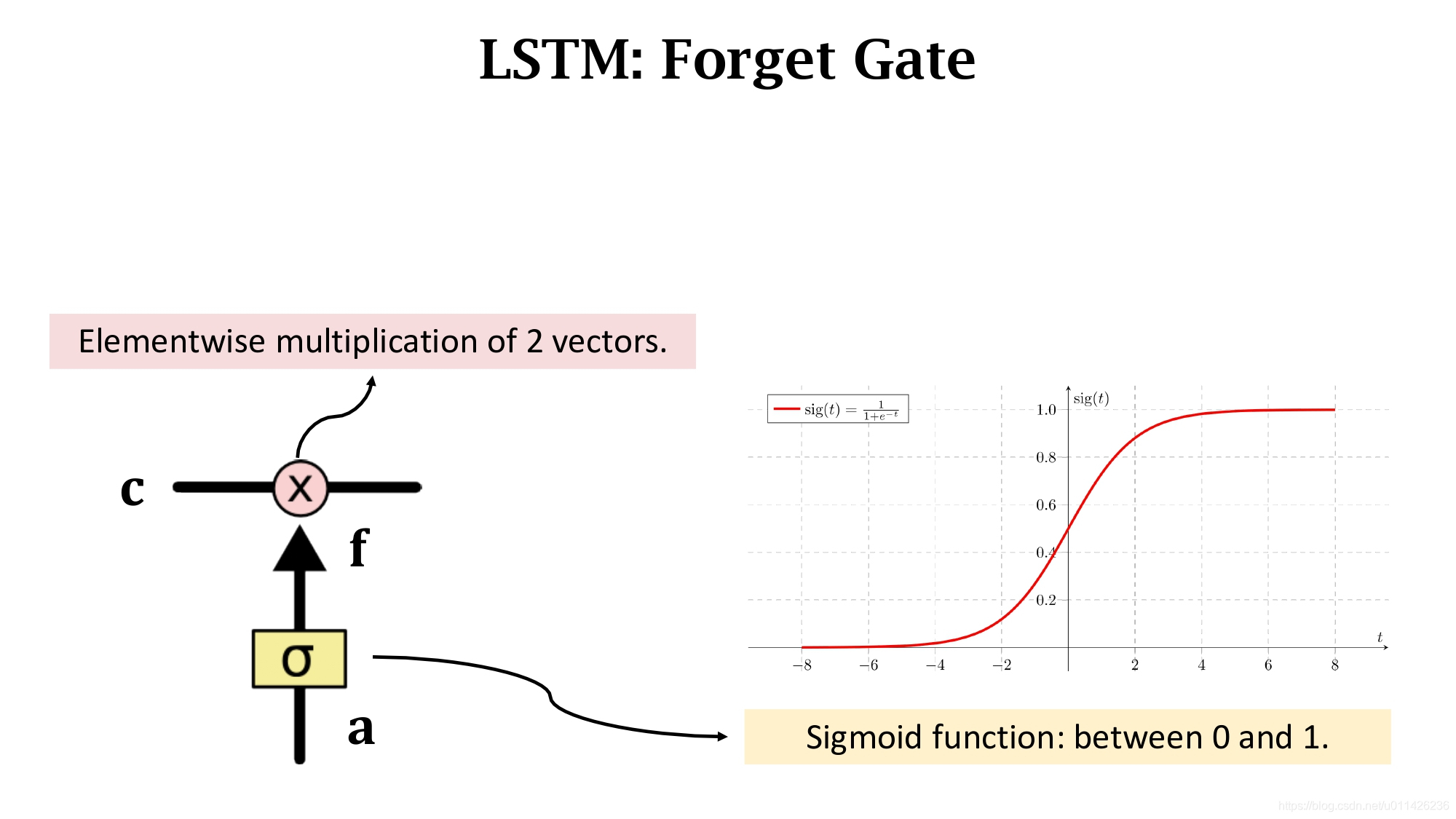
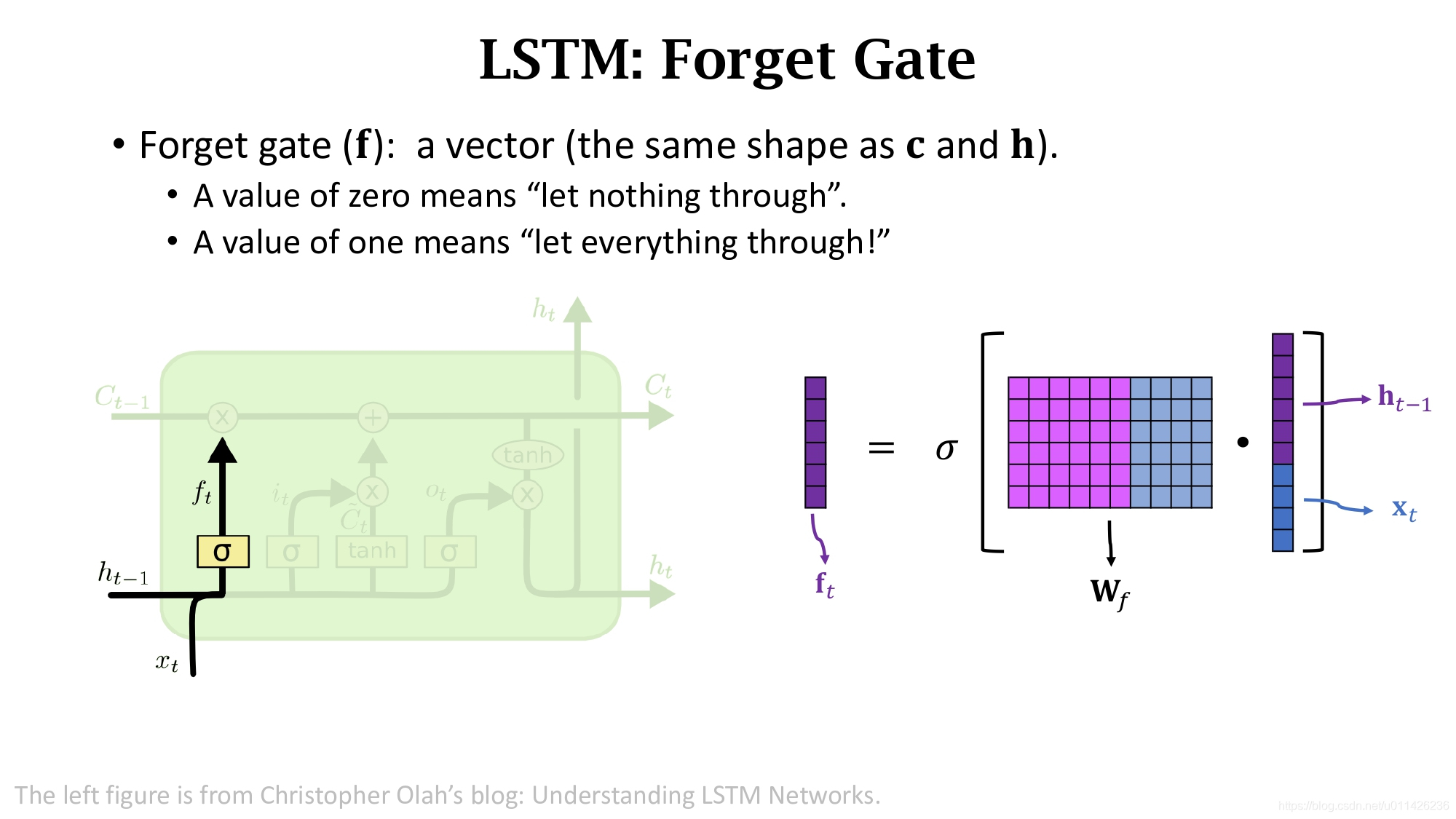
先来看一下Forget gate(遗忘门)。它由sigmoid函数和Elementwise multiplication两部分组成。Sigmoid函数将输入向量a的每一个元素都压到0和1之间,输入向量a和输出有相同的维度。
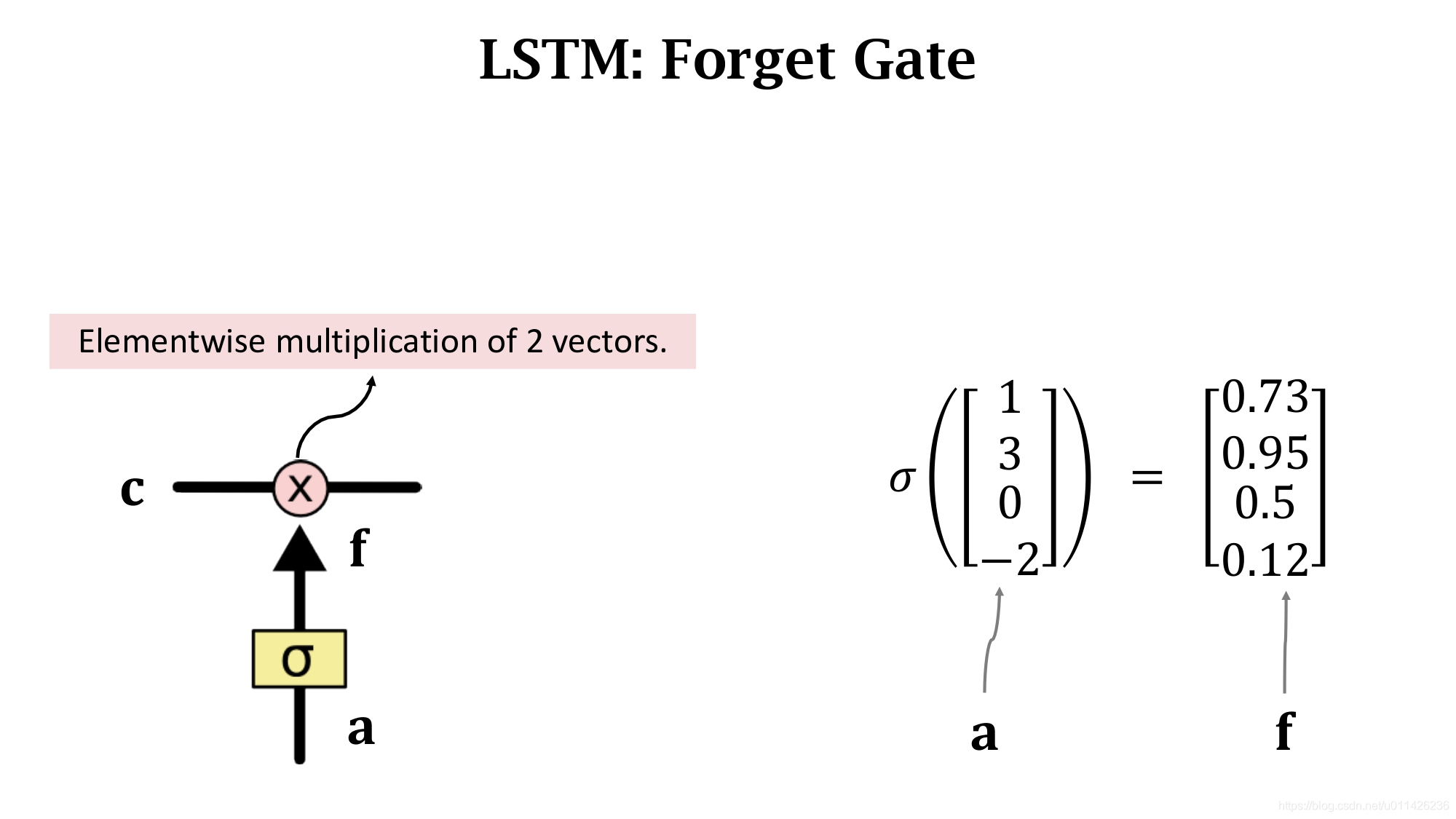
算出输出f后,再和c进行Elementwise multiplication得到最后输出。
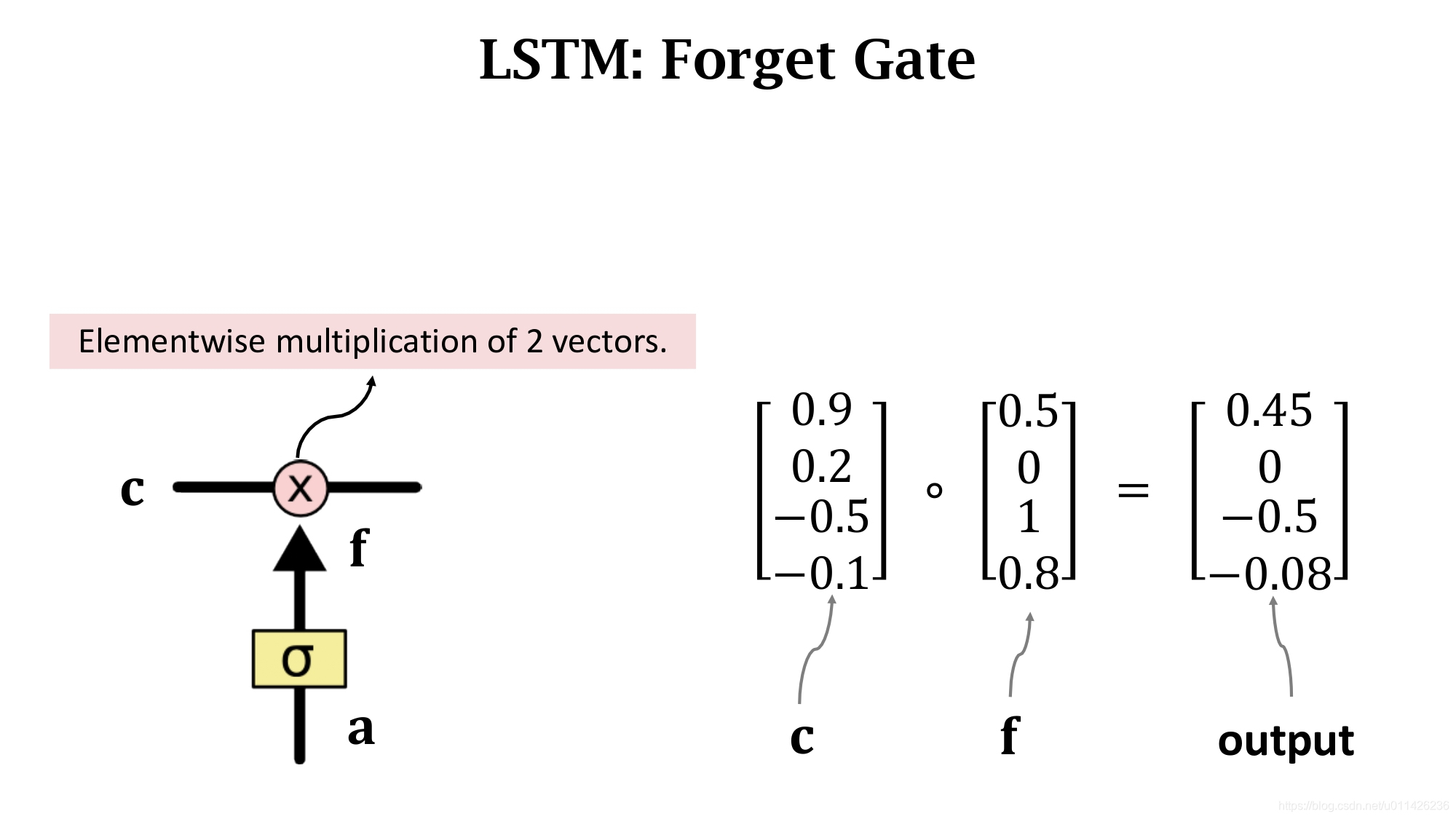
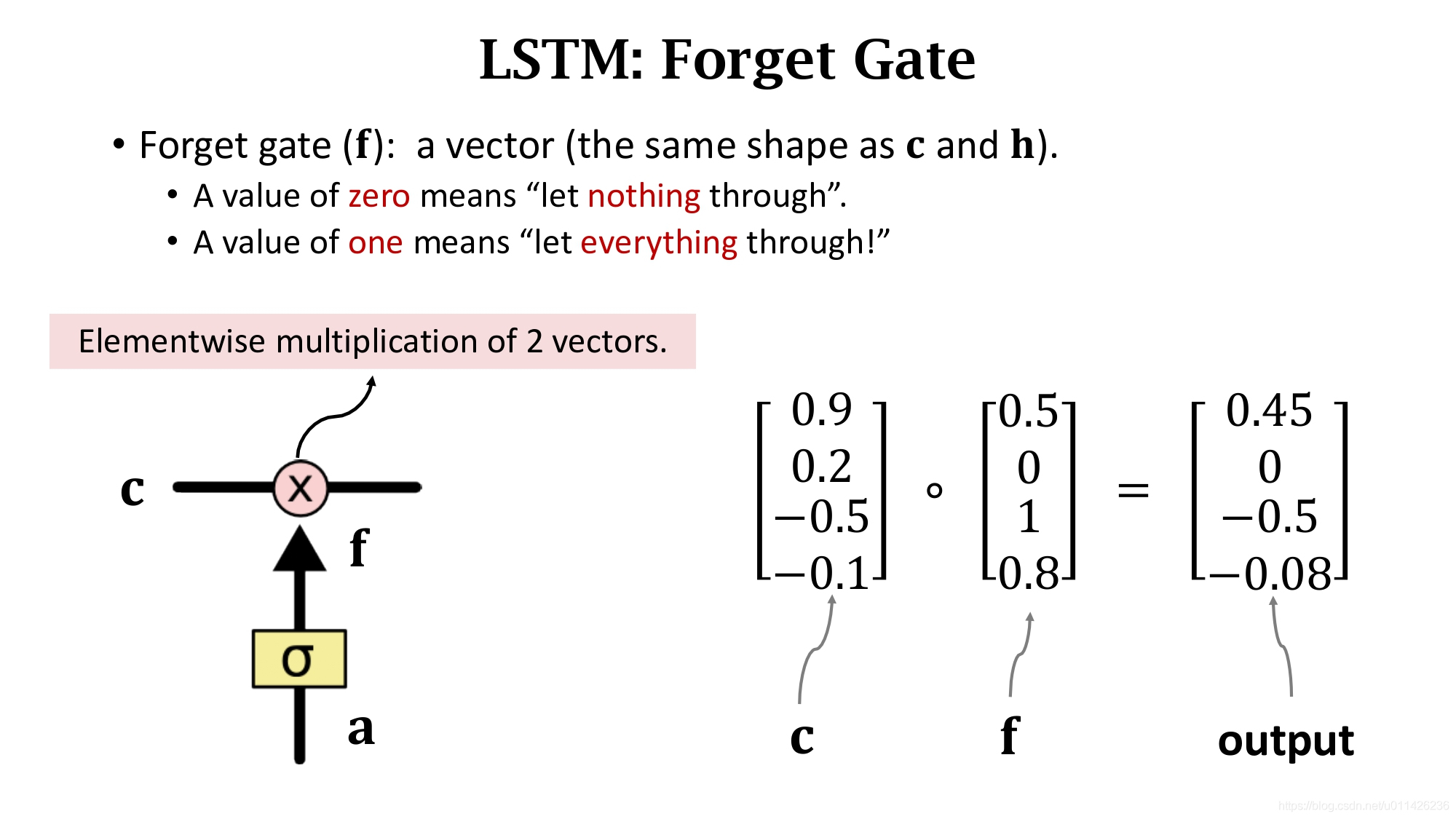
遗忘门f有选择的让传送带C的值通过,假如f的一个元素为0,那么C对应的元素就不能通过,对应的输出就为0;假如f的一个元素为1,那么C对应的元素就全部能通过,对应的输出就为C中这个元素本身。
遗忘门f具体是这样被算出来的。如图所示, f t f_t ft是上一个状态 h t − 1 h_{t-1} ht−1和当前输入 x t x_t xt的函数,将状态 h t − 1 h_{t-1} ht−1和当前输入 x t x_t xt进行concatenation得到一个更高的向量,然后算矩阵 W f W_f Wf和这个向量的乘积得到一个向量,然后再经过Sigmoid函数得到输出 f t f_t ft在0到1之间。遗忘门有一个参数矩阵 W f W_f Wf需要通过反向传播从训练数据中学习。
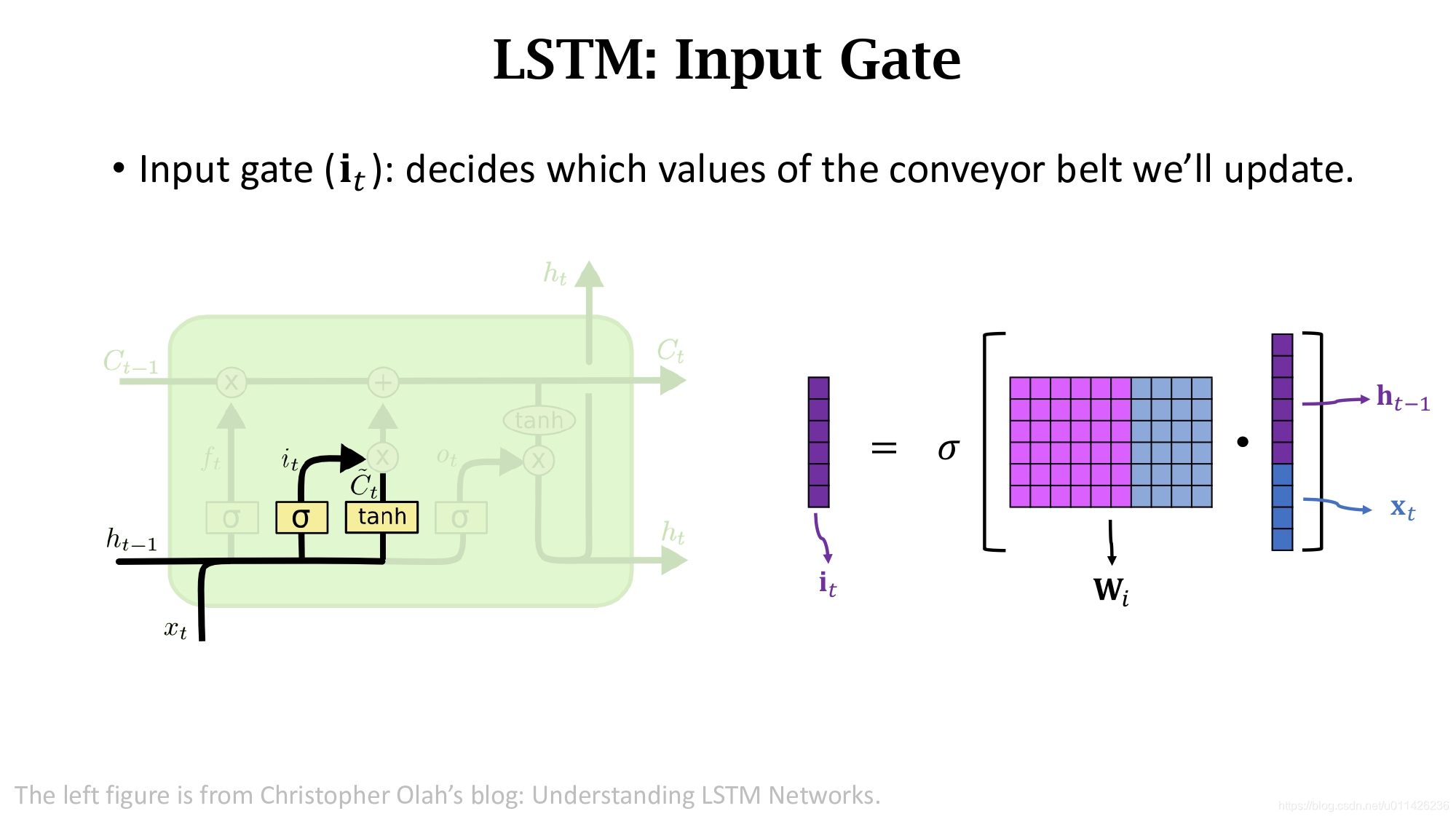
上面讲了遗忘门,现在来看一下输入门(Input Gate)。输入门
i
t
i_t
it依赖于旧的状态向量
h
t
−
1
h_{t-1}
ht−1和输入
x
t
x_t
xt。输入门的就算很类似与遗忘门。将状态
h
t
−
1
h_{t-1}
ht−1和当前输入
x
t
x_t
xt进行concatenation得到一个更高的向量,然后算矩阵
W
i
W_i
Wi和这个向量的乘积得到一个向量,然后再经过Sigmoid函数得到输出
i
t
i_t
it在0到1之间。输入门有一个参数矩阵
W
i
W_i
Wi需要通过反向传播从训练数据中学习。
除此之外,还需要计算一个new value
C
t
~
\tilde{C_{t}}
Ct~。
C
t
~
\tilde{C_{t}}
Ct~是个向量,计算跟遗忘门和输入门都很像,将状态
h
t
−
1
h_{t-1}
ht−1和当前输入
x
t
x_t
xt进行concatenation得到一个更高的向量,然后算矩阵
W
c
W_c
Wc和这个向量的乘积得到一个向量后通过激活函数。
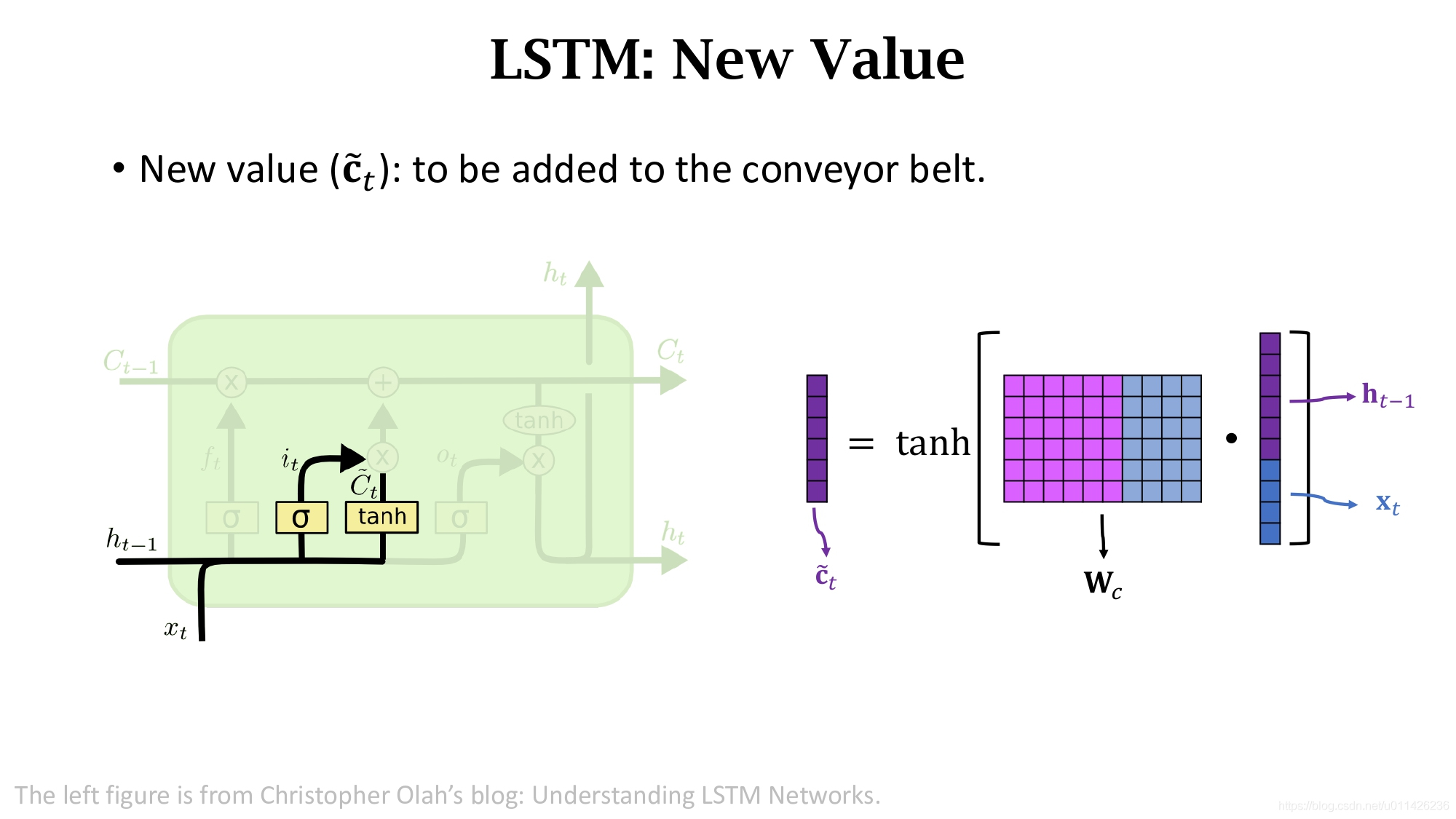
它的区别在于激活函数不是Sigmoid而是双曲正切函数。我们已经算出了遗忘门
f
t
f_t
ft、输入门
i
t
i_t
it和new value
C
t
~
\tilde{C_{t}}
Ct~,我们还知道传输带上旧的值
C
t
−
1
C_{t-1}
Ct−1。现在就可以更新传输带C了。

利用遗忘门 f t f_t ft和传送带旧的值 C t − 1 C_{t-1} Ct−1算Elementwise multiplication。遗忘门 f t f_t ft可以选择性的遗忘传送带旧的值 C t − 1 C_{t-1} Ct−1中的一些元素。

在选择性遗忘旧的传输带信息后,我们需要往上面添加新的信息。计算输入门输入门 i t i_t it和new value C t ~ \tilde{C_{t}} Ct~的Elementwise multiplication。将这个乘积直接加到传送带上就可以了,这样就完成了一轮更新:用遗忘门删除了一些旧的信息,同时又加入了一些新的信息。
现在已经更新完传送带C了,最后一步就是计算LSTM的输出,也就是状态向量 h t h_t ht,其计算过程如下:

首先计算输出门 o t o_t ot,它的计算方式跟前面输入门、遗忘门的计算方式基本一样。 将状态 h t − 1 h_{t-1} ht−1和当前输入 x t x_t xt进行concatenation得到一个更高的向量,然后算矩阵 W o W_o Wo和这个向量的乘积得到一个向量,然后再经过Sigmoid函数得到输出 o t o_t ot在0到1之间。输出忘门有一个参数矩阵 W o W_o Wo需要从训练数据中学习。

现在计算状态向量 h t h_t ht,对传输带 c t c_t ct的每一个元素求双曲正切,把元素都压到-1和+1之间。然后求这两个向量的Elementwise multiplication。这样就得到了输出向量 h t h_t ht。如图所示, h t h_t ht有两份copy,一个传输到了下一步,另一份copy成了LSTM的输出。到第t步为止,一共有t个向量输入了LSTM,可以认为所有这些x的信息都积累在了 h t h_t ht里面。
我们来算一下LSTM的参数,LSTM有遗忘门、输入门、new value以及输出门。这四个模块都有各自的参数矩阵W,矩阵的行数为 h的维度,列数为h的维度加上x的维度。所以,LSTM(不含intercept)的参数数量为: 4 × s h a p e ( h ) × [ s h a p e ( h ) + s h a p e ( x ) ] 4 \times shape(h) \times [ shape(h) + shape(x)] 4×shape(h)×[shape(h)+shape(x)]
使用Keras实现LSTM(LSTM Using Keras)
Keras 实现略
总结(Summary)
-
LSTM与简单RNN的区别就是用了一条传输带,让过去的信息很容易的传输到下一时刻,这样就有了更长的记忆。
-
LSTM的表现总是比简单RNN要好。在使用RNN时可以优先选择LSTM。
-
LSTM有四个组件,分别是:
- Forget gate(遗忘门)
- Input gate(输入门)
- New values(新的输入)
- Output gate(输出门)
-
LSTM的参数数量为 4 × s h a p e ( h ) × [ s h a p e ( h ) + s h a p e ( x ) ] 4 \times shape(h) \times [ shape(h) + shape(x)] 4×shape(h)×[shape(h)+shape(x)]














 8875
8875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









