







1.etcd原理简介
- etcd作为一个分布式键值存储系统,解决了分布式场景中的数据一致性问题,为服务发现提供了一个稳定、高可用的消息注册仓库,为以微服务协同工作的架构提供了无限的可能。
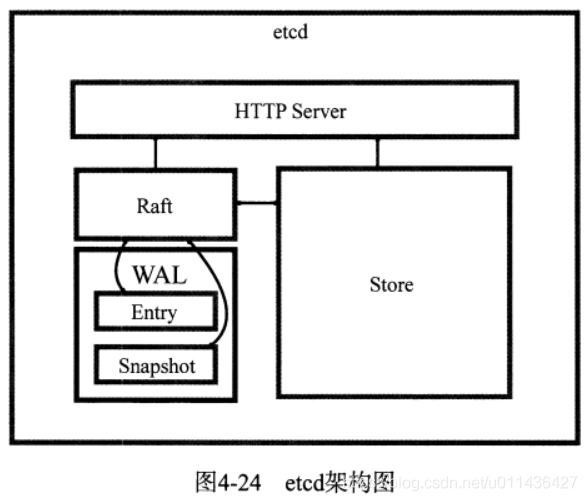
- etcd的架构,如图4-24
(1)HTTP Server:处理用户的API请求,处理其它etcd节点的同步与心跳信息请求
(2)Store:是etcd对用户提供的大多数API功能的具体实现
(3)Raft:强一致性算法的具体实现,是etcd的核心
(4)WAL:即Write Ahead Log(预写式日志),他是etcd的数据存储方式,除了在内存中存有所有数据的状态以及节点的索引日志外,etcd还通过WAL进行持久化存储。
(5)Entry是存储的具体日志的内容,Snapshot是为了防止数据过多而进行的状态快照;
一个用户的请求会由HTTP server转发给Store进行具体的事务处理。
若是节点的修改,则交给Raft模块进行状态的变更、日志的记录;
然后再同步给别的etcd节点以确认数据提交,最后进行数据的提交,再次同步;
- 集群化应用与实现原理
(1)etcd是一个高可用的键值存储系统,天生就是为集群化而设计的。
etcd一般部署集群推荐奇数个点
(2)集群启动的3种方案:静态配置启动,etcd自身服务发现,通过DNS进行服务发现
(3)运行时重构使得etcd集群无须重启即可修改集群的配置;在配置etcd集群数量时,至少配置3个核心节点,配置述目越多,可用性越强;
(4)etcd的节点都是实时同步的,每个节点上都存储了所有的信息
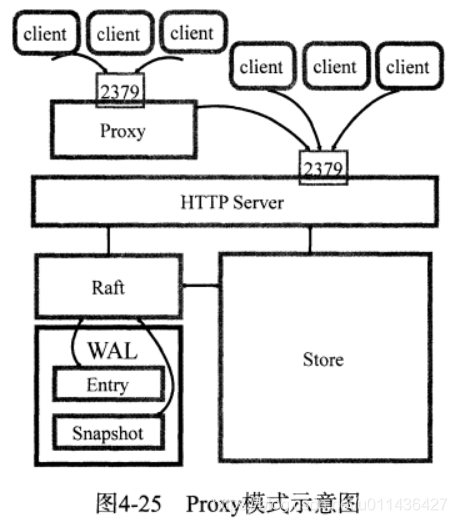
(5)Proxy模式下的etcd作为一个反向代理把客户的请求转发给可用的etcd集群。
Proxy并不是直接加入到符合强一致性的etcd集群中的,它没有增加集群的可靠性,也没有降低集群的写入性能。
为什么要有Proxy模式而不是直接增加etcd核心节点呢?
因为etcd每增加一个核心节点peer,都会给Leader节点增加一定程度的负担(网络,CPU,负载)。每次增加信息的变化都需要进行同步备份,增加一个轻量级的Proxy模式etcd节点就是对直接增加etcd节点的一个有效的替代。
2.etcd数据存储原理
- etcd存储分为内存存储和持久化(硬盘)存储两部分。
(1)内存中的存储:顺序化地记录所有用户对节点数据变更的记录,对数据进行索引,建堆等方便查询的操作
(2)WAL:对数据进行持久化的存储 - etcd的持久化存储目录有2个:
(1)WAL:存储着所有事务的变化记录,在数据的修改提交之前,都要先写入到WAL中。使用WAL进行数据的存储,使得etcd能够故障快速恢复,数据回滚或重做
(2)Snapshot:用于存储某一个时刻etcd所有目录的数据
3.Raft算法关键内容理解
-
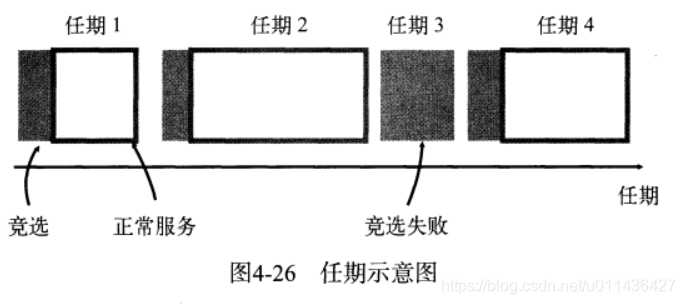
Raft中的一个任期是啥意思?
定义:从某一次竞选开始到下一次竞选开始。
若Follower接收不到Leader节点心跳,就会结束当前任期,变为Candidate发起竞选
-
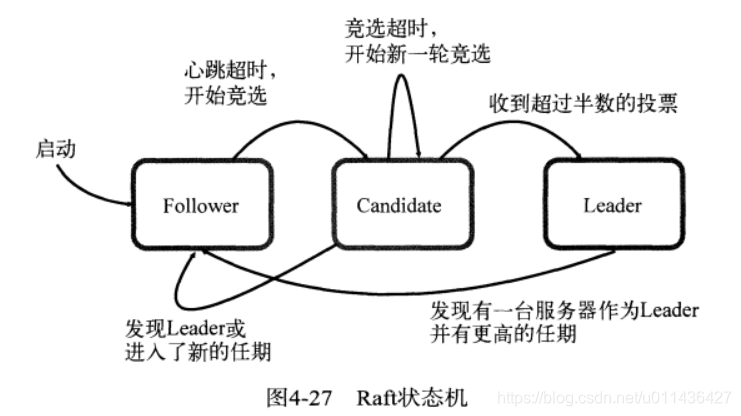
Raft状态机是如何切换的?
Raft刚刚开始运行时,节点默认进入到Follower的状态,等待Leader发来心跳信息
-
如何保证最短时间内竞选出Leader,以防止竞选冲突
在Candidate状态下有个心跳超时,这是个随机值。在时间差内,若Candidate1收到的竞选信息比自己发起的竞选信息的任期要大,那么Candidate1就会投票给Candidate2 -
如何防止遗漏数据的节点成为Leader?
若发起竞争的节点在上一个任期中保存的已提交的数据不完整,节点就会拒绝投票给他 -
Raft某个节点宕机后会如何?
(1)若是Follower节点宕机,集群基本不受影响
(2)若是Leader节点宕机,则开启竞选机制 -
为什么Raft短发在确定可用节点数量时不需要考虑拜占庭将军问题?
(1)拜占庭将军问题指出:允许n个节点宕机还能提供正常服务的分布式架构,需要的总结点数量为3n+1,而raft只需要2n+1。
原因是:拜占庭将军问题中存在数据欺骗的现象,而etcd中假设的所有节点都是诚实的
(2)etcd严格限制Leader到Follower这样的数据流向,以保证数据一致性不出错 -
用户从集群中哪个节点读写数据?
所有用户更新的数据请求都是最先由Leader获得并保存下来,然后通知其它节点将其保存,等到大多数节点反馈时,一个已提交的数据项才是Raft真正稳定存储下来的数据项。 -
etcd实现的Raft算法的性能?
单实例节点每秒1千次数据写入。
节点增加,网络延迟会对数据同步造成影响;由于每个节点都能处理用户的读请求,所以读性能会提升。 -
etcd的API
etcd中处理API的包称之为Store,该API都是对etcd存储的键值进行操作。















 9310
9310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











