







注:此文摘自Hadoop学习及应用---方宸 2013.06.09 ppt
Hadoop简介
•Hadoop集群是主从关系:一个Master,多个Slave
•Master充当NameNode,管理文件系统,运行着JobTracker,负责整个作业的调度。
•Slave充当DataNode,是数据存储的真正所在地,运行着TaskTracker,负责完成由JobTracker分配过来的任务。

•HDFS文件系统(HadoopDistributed File System)
NameNode管理文件系统的命名空间和客户端对文件系统的访问操作。
DataNode管理存储的数据。
•MapReduce框架
MapReduce框架是由一个单独运行在NameNode上的JobTracker和运行在每个集群DataNode的TaskTracker共同组成的。
JobTracker负责调度构成一个作业的所有任务,这些任务分布在不同的DataNode上,DataNode仅负责由NameNode指派的任务。
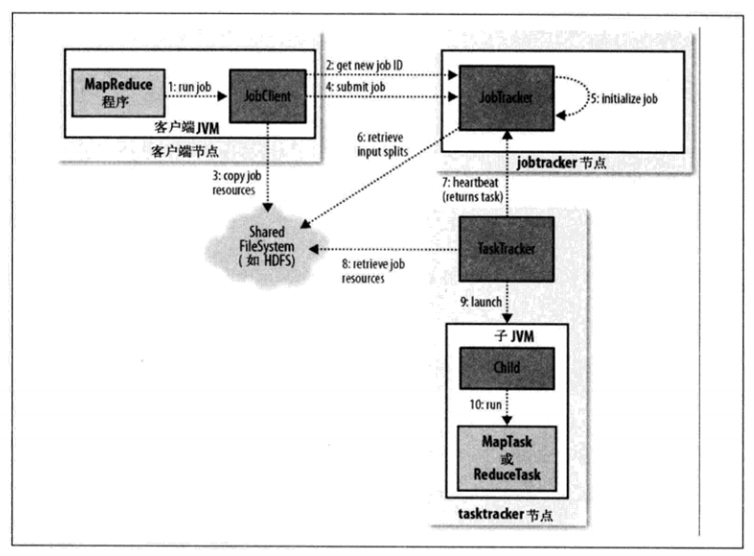
MapReduce作业的工作原理
•运行MapReduce作业的工作原理
MapReduce示例--WordCount
•map→combine→partition→reduce


•WordCount是一个统计文件内单词数量的程序。
•目标:
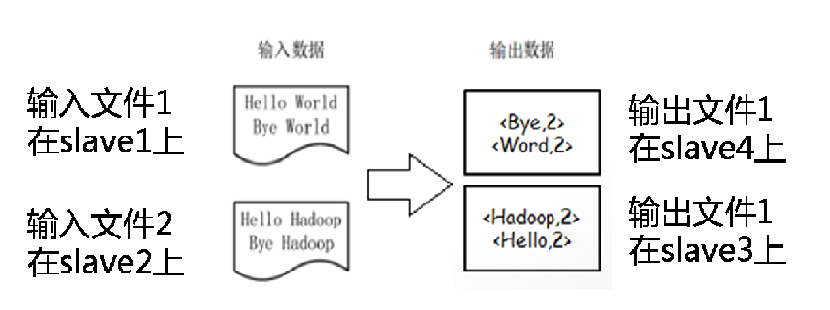
假设有4个slave,两个文件
•map过程(map-combine-partition-reduce):
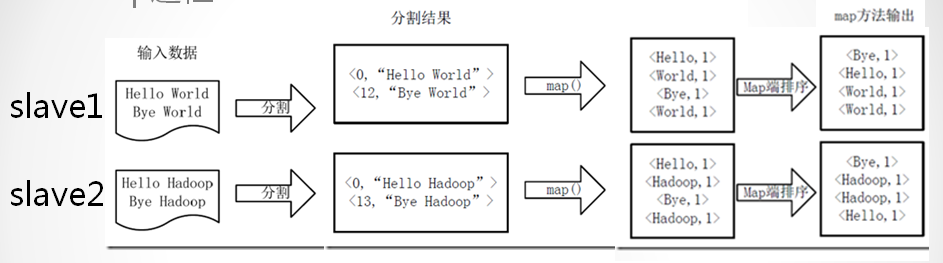
•map的输入key是每行数据在文件中的偏移量
•map的输入value是每行数据
•map的输出key是每个单词
•map的输出value是一个固定字符串”1”
•注意:map自带排序功能
•combine过程(map-combine-partition-reduce):
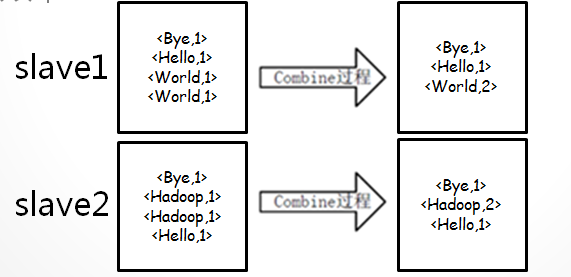
•combine不是必须的
•combine使用的类与reduce使用的类相同
•combine在map结束的时候进行,在map本地进行一些合并,可以减少从map端到reduce端的数据复制,提高效率
•partition过程(map-combine-partition-reduce):
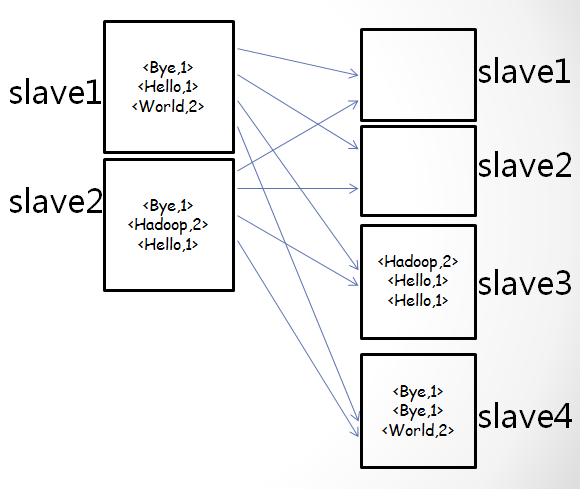
•partition过程使用partitioner对map端的输出数据进行重定向,默认使用HashPartitioner。
•因此,根据map输出key的hash值,重定向map的输出结果
•注意:这里假设hash分区之后如上图所示
•reduce过程(map-combine-partition-reduce):
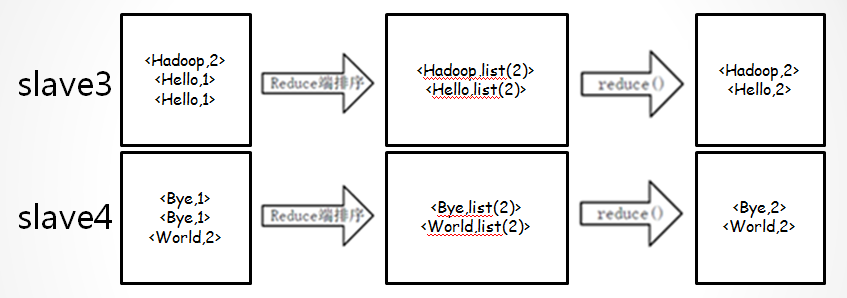
•注意:每个reduce输出的结果是有序的,但所有reduce合起来看,并不是全局有序的。
源码分析(Java):
publicstatic class MyMap extends Mapper<Object,Text, Text, Text>{
private final static Text one = new Text("1");
private Text word = new Text();
public void map(Object key, Text value, Context context) throwsIOException,
InterruptedException{
StringTokenizeritr = newStringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
publicstatic class MyReduce extends Reducer<Text,Text,Text,IntWritable> {
privateIntWritable result = newIntWritable();
publicvoid reduce(Text key, Iterable<Text> values, Context context) throws
IOException,InterruptedException{
int sum = 0;
for (Textval: values) {
sum+=val.get();
}
result.set(sum);
context.write(key, result);
}
}
public class wordCount {
public static classMyMap extends Mapper<Object, Text, Text, Text> {
}
public static classMyReduce extends Reducer<Text, Text, Text,IntWritable> {
}
public static void main(String[]args) {
Configuration conf =new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2 ) {
System.err.println("Usage:MapMapReduce <in> <out>");
System.exit(2);
}
conf.set(“mapred.textoutputformat.separator”,“|”);//设置输出key、value之间的分隔符,
默认为制表符
intnumReduce = 20;
Job job = new Job(conf,"word count");
job.setNumReduceTasks(numReduce);//设置reduce的个数
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMap.class);//设置map类
job.setCombinerClass(MyReduce.class);//设置combine类
job.setReducerClass(MyReduce.class);//设置reduce类
job.setOutputKeyClass(Text.class);//设置输出reduce的key的类型
job.setOutputValueClass(IntWritable.class);//设置输出reduce的value的类型
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));//设置输入路径
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));//设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









