









本篇来学习一些计算时间复杂度相关的概念和规则,然后理解一些常见的时间复杂度。
1.最坏时间复杂度
分析算法时,存在几种可能的考虑:
算法完成工作最少需要多少基本操作,即最优时间复杂度。
算法完成工作最多需要多少基本操作,即最坏时间复杂度。
算法完成工作平均需要多少基本操作,即平均时间复杂度。
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面反映了这个算法的性质。但,另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算机,也会因为应用算法实例分布可能并不均匀而难以计算。
因此,我们主要关注算法最坏情况,也就是最坏时间复杂度。
2.时间复杂度的几条基本计算规则
1.基本操作,即只有常数项,认为其时间复杂度为O(1)
2.顺序结构,时间复杂度按加法进行计算
3.循环结构,时间复杂度按乘法进行计算
4.分支结构,时间复杂度取最大值
5.判断一个算法的效率时,往往只需要关注操作数量的最高次项,其他次要项和常数项可以忽略。
6.在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度。
3.常见的时间复杂度
看看下面这张表
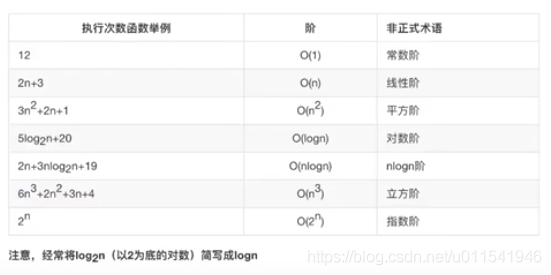
上面这个表,给了以后计算时间复杂度的一个参考。
4.常见时间复杂度之间关系
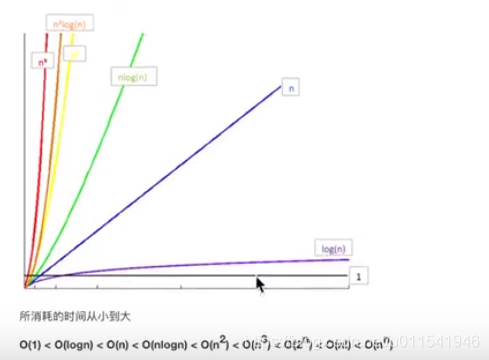
这个图很形象告诉我们常见几个时间杂度耗时间关系。
5.python中代码执行时间测量模块timeit
在python中有一个测量函数执行时间的模块叫timeit,下面利用这个模块来测量几种创建list的效率问题。
先来看看这两行代码的含义
time1 = Timer("test1()", "from __main__ import test1") # 调用测量时间模块的方法
time1.timeit(1000) # 1000指的是测量1000次之后取平均值# coding:utf-8
from timeit import Timer
def test1():
li = []
for i in range(10000):
li.append(i)
def test2():
li = []
for i in range(10000):
li.insert(0, i)
def test3():
li = [i for i in range(10000)] # 列表生成器方式
def test4():
li = list(range(10000))
time1 = Timer("test1()", "from __main__ import test1")
print("append:", time1.timeit(1000))
time2 = Timer("test2()", "from __main__ import test2")
print("insert:", time2.timeit(1000))
time3 = Timer("test3()", "from __main__ import test3")
print("[i in range(10000)]:", time3.timeit(1000))
time4 = Timer("test4()", "from __main__ import test4")
print("list转换:", time4.timeit(1000))
运行效果
append: 0.9357269000000001
insert: 20.1958311
[i in range(10000)]: 0.44400420000000196
list转换: 0.23993809999999982在列表中,append方法是从尾部添加元素,而insert方法是从头部插入元素,发现insert比append太慢。其实上面还有一种没有写出来就是li = li + [i], 如果i取值10000,这个执行时间差不多要3到4分钟。
6.python中列表和字典操作时间复杂度
list内置操作时间复杂度

dict内置操作时间复杂度















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









