







内核版本:2.6.34
802.1q
1. 注册vlan网络系统子空间,
err = register_pernet_subsys(&vlan_net_ops);
static struct pernet_operations vlan_net_ops = {
.init = vlan_init_net,
.exit = vlan_exit_net,
.id = &vlan_net_id,
.size = sizeof(struct vlan_net),
};每个子空间注册成功都会分配一个ID,在register_pernet_subsys() -> register_pernet_operations() -> ida_get_new_above()获得,而vlan_net_ops中的vlan_net_id记录了这个ID。注册子空间的最后会调用子空间的初始化函数vlan_init_net(),它会把vlan_net(有关vlan的proc文件系统信息)加到全局的net->gen->ptr数组中去,下标为之前分配的ID。这样,通过vlan_net_id便可随时查到vlan_net的信息,主要与proc有关。
2. 注册vlan_notifier_block
err = register_netdevice_notifier(&vlan_notifier_block);
static struct notifier_block vlan_notifier_block __read_mostly = {
.notifier_call = vlan_device_event,
};
err = raw_notifier_chain_register(&netdev_chain, nb);然后通知事件NETDEV_REGISTER和NETDEV_UP事件到网络系统的中的每个设备:
此时nb就是vlan_notifier_block,调用通知函数vlan_device_event()。假设此时主机上拥有设备lo[环回接口], eth1[网卡], eth1.1[虚拟接口],来看vlan_device_event()函数:
判断是否为vlan虚拟接口,则执行__vlan_device_event(),这个函数的作用就是在proc文件系统中添加或删除vlan虚拟设备的相应项。显然,符合条件的是eth1.1,而事件NETDEV_REGISTER会在/proc/net目录下创建eth1.1的文件。
然后判断dev是否在vlan_group_hash表中[参考最后”vlan设备组织结构”],它以dev->ifindex为hash值,显然,只有eth1才有正确的ifindex,lo和eth1.1会因查询失败而退出vlan_device_event。
grp = __vlan_find_group(dev);
if (!grp)
goto out;下面的事件处理只有eth1会执行,以NETDEV_UP为例,通过vlan_group_hash表可以根据eth1查到所有在其上创建的虚拟网卡接口,如果这些网卡接口没有开启,则开启它,这里开启用到的是dev_change_flags(vlandev, flgs | IFF_UP)。跟踪该函数可以发现它仅仅是修改flags后,通知NETDEV_UP事件,等待设备去处理。这里的含义可以这样理解,如果ifconfig eth1 up,则在eth1上创建的所有vlan网卡接口都会被up。
可以看出,vlan_device_event最后都是操作的vlan虚拟接口,这点是很重要的,不要越权处理其它设备。
3. 添加协议模块vlan_packet_type到ptype_base中
在[net\8021q]目录,主要是关于报文接收的
vlan_skb_recv() [net\8021q\vlan.c]
检查skb是否被多个协议模块引用,如果是则拷贝一份,并递减计数,必要时释放skb,这部分要和netif_receive_skb()中的pt_prev连起来理解,就明白为什么要使用pt_prev而不是直接使用ptype。如果使用ptype,则会多出一次拷贝。
skb_share_check()会调用3个函数:skb_sharde(), skb_clone(), kfree_skb(),都很重要。
skb_shared()检查skb->users数目是否为1,不为1则表示有多个协议栈模块要处理它,此时就需要使用skb_clone()来复制一份skb;kfree_skb()并不一定释放skb,只有当skb->users为1时,才会释放;否则只是递减skb->users。
这一步是核心,此时skb->dev为真正的设备,经过vlan处理后,报文应该被上层协议看作是由vlan虚拟设备接收的,因此这里设置skb->dev为虚拟的vlan设备。
skb->dev = __find_vlan_dev(dev, vlan_id); 以收到ARP请求报文后回应为例,看下skb->dev的变化,使得报文在协议栈中流转:
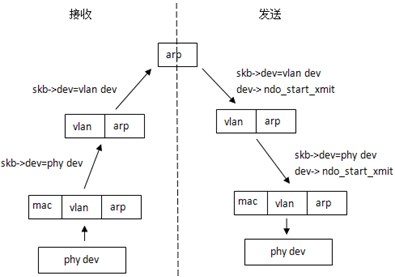
更新网卡接收报文的信息:
设置skb->len和skb->data指针,从而跑过vlan标签,而对skb->csum的计算会忽略,因为在网卡驱动收到报文时,skb->ip_summed== CHECKSUM_NONE。
重置skb->protocol为vlan标签后面接的协议类型,之前的protocol为0x8100(即ETH_P_8021Q)
最后调用netif_rx(),它会将skb重新放入接收队列中,让skb在协议栈中继续向上走。要注意的是这时候skb->protocol已经是vlan标签后的协议标识,因此重新进入netif_receive_skb()时会被更上一层的ptype处理掉。
此时协议模块802.1q已经处理完,此时skb会被释放掉,此时skb->users是1。
netif_rx()这个函数很重要,可以说是各个协议模块之前报文流向的纽带,这里详细讲解下:
获取当前CPU的softnet_data结构体
softnet_data这个结构体在设备初始化时会被赋值,见[net\core\dev.c中net_dev_init()];对于每个CPU,都会分配一个softnet_data,里面重要的是backlog.poll = process_backlog;在软中断处理中,会调用poll_list链表上的poll方法,在稍后会看到加入poll_list链表的是queue->backlog,因此当再次在软中断中处理该报文时,会使用process_backlog()函数;作为对比,可以看在网卡驱动中加入poll_list链表的是bp->napi,这时候的poll方法是网卡驱动自己的b44_poll()。
判断input_pkt_queue队列长度,如果长度为0,则将queue->backlog加入poll_list中,并触发软中断,同时也将skb加入input_pkt_queue队列;如果长度>=1,则表明input_pkt_queue队列中还有未处理的skb,并且队列头的skb已经触发了软中断,只是还未被处理,因此此时只需将skb加入input_pkt_queue队列,而不用再次触发软中断。
这里有两个地方要注意,第一是skb加入的链队是input_pkt_queue,但加入poll_list的却是backlog,这是因为在软中断中调用的是backlog.poll方法,而它会处理input_pkt_queue;第二是软中断的触发只在队列为空时再发生,因为每次软中断net_rx_action()中,不只是处理一个skb,而是队列上所有的skb:while (!list_empty(list))。
整体流程如图所示:

4. 添加ioctl供用户空间调用
添加IOCTL选 项,供用户空间进行内核的vlan配置,比如ADD_VLAN_CMD会创建vlan虚拟接口;DEL_VLAN_CMD会删除vlan虚拟接口。
VLAN设备的组织结构
如果只是vlan模块的接收与发送,那了解到vlan_skb_recv()与vlan_dev_hard_start_xmit()函数就可以了。但vlan的实现考虑的要多很多,比如:新创建的eth1.1存储在哪里?eth1.1和eth1如果进行关联?这些都是下面要讲的。
数据结构vlan_group_hash是vlan虚拟网卡存储与关联的核心结构:
static struct hlist_head vlan_group_hash[VLAN_GRP_HASH_SIZE]; [net\8021q\vlan.c]
当通过vconfig创建了eth1.1, eth1.2, eth1.100三个虚拟网卡后,vlan_group_hash的整体结构如图所示,先有个整体印象:
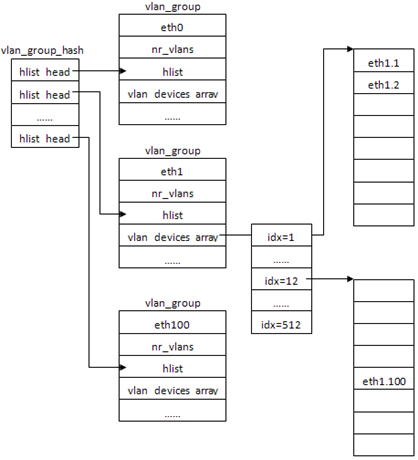
vlan_group_hash是大小为32的hash表,所用的hash函数是:
而传入参数idx就是dev->ifindex,比如eth1的就是1。因此可以这样理解,vlan_group_hash表插入的是真实网卡设备信息(eth1)。对于一般主机来说,网卡不会太多,32个表项的hash表是完全足够的。
在添加vlan时,会创建新的vlan虚拟网卡:
register_vlan_device() -> register_vlan_dev()
首先查找网卡是否已存在,这里的real_dev一般是真实的网卡如eth1等。以real_dev->ifindex值作hash,取出vlan_group_hash的表项,由于可能存在多个网卡的hash值相同,因此还要匹配表项的real_dev是否与real_dev相同。
如果不存在相应的表项,则分配表项struct vlan_group,并加入vlan_group_hash:
结构定义如下,它可以代表在vlan下真实网卡的信息。real_dev指向真实网卡如eth1;nr_vlans表示网卡下创建的vlan数;vlan_devices_arrays用于存储创建的vlan虚拟网卡:
创建完表项vlan_group,紧接初始化vlan_devices_arrays二维数组中相应元素
最后,设置vlan_devices_arrays相应元素指向创建的vlan虚拟网卡(如eth1.1)的struct net_device。这里值得注意的是vlan_devices_arrays是二维数组,内核支持的最大vlan数是4096,为了查找效率,应用了二级目录的概念。vlan_devices_arrays指向大小512的数组,数组中每个再指向大小8的数组,像eth1.100则位于第12组的第5个(vlan_devices_arrays[11][4])。
以一个例子来说明,当主机收到报文,交由vlan协议模块处理后(vlan_rcv),此时需要更换skb->dev所指向的设备,以使上层协议认为报文是来自于虚拟网卡(比如eth1.1),而不知道网卡eth1的存在。更换设备就需要知道skb->dev更换的目标。这由两个因素决定:skb->dev和vlan_id。skb->dev即报文来自主机的哪个网卡,如来自eth1,则skb->dev->name=”eth1”;vlan_id即vlan号,这在报文中的vlan报文中可以提取出。有了这两个信息,从vlan_group_hash出发,首先根据skb->dev->ifindex查找vlan_group_hash的相应项(eth1),取出vlan_group;然后,根据vlan_id,在vlan_devices_array中查找到虚拟网卡设备(eth1.1)。
一般支持的最大vlan数是4096,为了查询效率,vlan_devices_array并不是一个4096的数组,而是二维数组,将每8个vlan分为一组,共512组,像eth1.100则位于第12组的第5个。
看完了路由表,重新回到netif_receive_skb ()函数,在提交给上层协议处理前,会执行下面一句,这就是网桥的相关操作,也是这篇要讲解的内容。
skb = handle_bridge(skb, &pt_prev, &ret, orig_dev); 网桥可以简单理解为交换机,以下图为例,一台linux机器可以看作网桥和路由的结合,网桥将物理上的两个局域网LAN1、LAN2当作一个局域网处理,路由连接了两个子网1.0和2.0。从eth0和eth1网卡收到的报文在Bridge模块中会被处理成是由Bridge收到的,因此Bridge也相当于一个虚拟网卡。

STP五种状态
DISABLED
BLOCKING
LISTENING
LEARNING
FORWARDING
创建新的网桥br_add_bridge [net\bridge\br_if.c]
当使用SIOCBRADDBR调用ioctl时,会创建新的网桥br_add_bridge。
首先是创建新的网桥:
然后设置dev->dev.type为br_type,而br_type是个全局变量,只初始化了一个名字变量
然后注册新创建的设备dev,网桥就相当一个虚拟网卡设备,注册过的设备用ifconfig就可查看到:
最后在sysfs文件系统中也创建相应项,便于查看和管理:
ret = br_sysfs_addbr(dev);
将端口加入网桥br_add_if() [net\bridge\br_if.c]
当使用SIOCBRADDIF调用ioctl时,会向网卡加入新的端口br_add_if。
创建新的net_bridge_port p,会从br->port_list中分配一个未用的port_no,p->br会指向br,p->state设为BR_STATE_DISABLED。这里的p实际代表的就是网卡设备。
将新创建的p加入CAM表中,CAM表是用来记录mac地址与物理端口的对应关系;而刚刚创建了p,因此也要加入CAM表中,并且该表项应是local的[关系如下图],可以看到,CAM表在实现中作为net_bridge的hash表,以addr作为hash值,链入net_bridge_fdb_entry,再由它的dst指向net_bridge_port。
err = br_fdb_insert(br, p, dev->dev_addr); 
设备的br_port指向p。这里要明白的是,net_bridge可以看作全局量,是网桥,而net_bridge_port则是与网卡相对应的端口,因此每个设备dev有个指针br_port指向该端口。
将新创建的net_bridge_port加入br的链表port_list中,在创建新的net_bridge_port时,会分配一个未用的port_no,而这个port_no就是根据br->port_list中的已经添加的net_bridge_port来找到未用的port_no的[具体如下图]。

重新计算网桥的ID,这里根据br->port_list链表中的net_bridge_port的最小的addr来作为网桥的ID。
网卡设备的删除br_del_bridge()与端口的移除add_del_if()与添加差不多,不再详述。
熟悉了网桥的创建与添加,再来看下网桥是如何工作的。
当收到数据包,通过netif_receive_skb()->handle_bridge()处理网桥:
1. 如果报文来自lo设备,或者dev->br_port为空(skb->dev是收到报文的网卡设备,而在向网桥添加端口时,dev->br_port被赋予了创建的与网卡相对应的端口p),此时不需要网桥处理,直接返回报文;
2. 如果报文匹配了之前的ptype_all中的协议,则pt_prev不为空,此时要先进行ptype_all中协议的处理,再进行网桥的处理;
3. br_handle_frame_hook是网桥处理钩子函数,在br_init() [net\bridge\br.c]中
br_handle_frame_hook = br_handle_frame;
br_handle_frame() [net\bridge\br_input.c]是真正的网桥处理函数,
下面进入br_handle_frame()开始网桥部分的处理:
与前面802.1q讲的一样,首先检查users来决定是否复制报文:
skb = skb_share_check(skb, GFP_ATOMIC);如果报文的目的地址是01:80:c2:00:00:0X,则是发往STP的多播地址,此时调用br_handle_local_finish()来完成报文的进一步处理:
而br_handle_local_finish()所做的内容很简单,因为是多播报文,主机要做的仅仅是更新报文的源mac与接收端口的关系(在CAM表中)。
接着br_handle_frame()继续往下看,然后根据端口的状态来处理报文,如果端口state= BR_STATE_FORWARDING且设置了br_should_route_hook,则转发后返回skb;否则继续往下执行state=BR_STATE_LEARNING段的代码:
如果端口state= BR_STATE_LEARNING,如果是发往本机的报文,则设置pkt_type为PACKET_HOST,然后执行br_handle_frame_finish来完成报文的进一步处理。要注意的是,这里将报文发往本机的报文设为PACKET_HOST,实现了经过网桥处理后,再次进入netif_receive_skb()时,不会再被网桥处理(结果进入网桥的条件理解):
除此之外,端口处于不可用状态,此时丢弃掉报文:
下面来详细看下br_handle_frame_finish()函数。
首先还是会根据收到报文的源mac和端口更新CAM表,这是交换机区别于hub的重要特征:
br_fdb_update(br, p, eth_hdr(skb)->h_source);然后如果端口处于LEARNING状态,则只是学习到CAM表中,而不对报文作任何处理,所以丢弃掉报文:
否则端口已处于FORWARDING状态,此时分情况:
1. 如果报文是多播的,则br_flood_forward(br, skb, skb2);
2. 如果报文是单播的,但不在网桥的CAM表中,则br_flood_forward(br, skb, skb2);
3. 如果报文是单播的,在网桥的CAM表中,但不是发往本机,则br_forward(dst->dst, skb, skb2);
4. 如果报文是单播的,在网桥的CAM表中,且是发往本机,则br_pass_frame_upbr_pass_frame_up(skb2);
br_handle_frame_finish()处理完后,顺着最后一种情况继续往下走,br_pass_frame_up()。
该函数比较简单,我们知道,在底层报文的向上传递就是通过设备的更换来进行的(参考802.1q),这里将skb的设备换成网桥设备,使上层协议不知道报文来自网卡,而是认为报文来自于网桥;然后调用netif_receive_skb()再次进入接收栈:
经过网桥处理后,再次进入netif_receive_skb()->handle_bridge(),此时skb->dev已经不是网卡设备了,而是网桥设备,注意到在向网桥添加端口时,是相应网卡dev->br_port赋值为创建的端口,网桥设备是没有的,因此其br_port为空,在这一句会直接返回,进入正常的协议栈流程:
当发送数据报文时,会调用br_dev_xmit()[net\bridge\br_device.c],大致会根据目的地址调用br_multicast_deliver()或br_flood_deliver()或br_deliver(),在其过程中会将skb->dev由原来的网桥设备brdev换面网卡设备dev,然后通过网卡变更向下传递报文;
内核协议栈中,发送与接收是分离的,接收像是报文脱壳的过程,发送则是函数的嵌套调用。有关发送的流程,稍后专门详述。















 1650
1650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









