






2024-09-26,芝加哥大学的研究者们发布了一个名为BeanCounter的大规模商业文本数据集。这个数据集的发布,不仅为语言模型的发展和评估提供了新的资源,还可能推动商业领域文本处理的进一步研究。
一、研究背景
在商业领域,准确的文本分析对于理解市场趋势、消费者行为、竞争情报等至关重要。然而,现有的数据集往往存在一些问题,比如包含大量有毒内容、缺乏时效性、质量参差不齐等。为了解决这些问题,研究者们创建了BeanCounter数据集。
目前遇到的问题和挑战
1、数据源的局限性:现有的大规模文本数据集主要来源于网络抓取,这可能导致数据的质量和时效性无法满足高级语言模型的需求。
2、数据质量:网络数据集可能包含大量重复、质量低下或与事实不符的内容,这些都会影响模型的训练效果。由于网络数据集的开放性,它们可能包含各种偏见和虚假信息,这在训练过程中难以控制。
3、包含敏感信息:公开的数据集可能会意外地包含个人身份信息,这涉及到隐私和合规风险。
4、数据集的毒性:许多现有的数据集含有较高毒性的内容,这可能导致训练出的模型生成有害或冒犯性的内容。
5、时效性:与网络数据集相比,商业披露文件具有明确的时间戳,这对训练时效性强的模型非常重要。
数据集地址:BeanCounter|金融数据数据集|文本数据集数据集
二、让我们一起来看BeanCounter数据集:
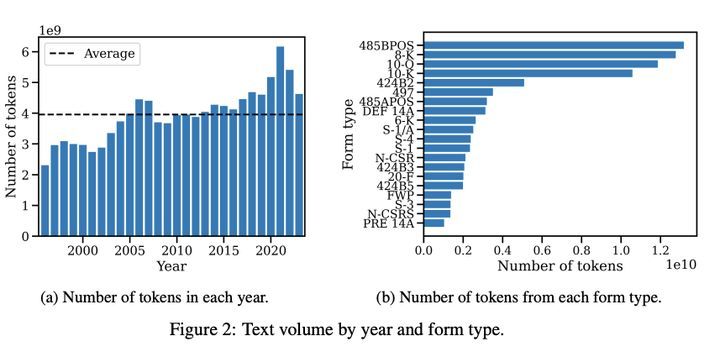
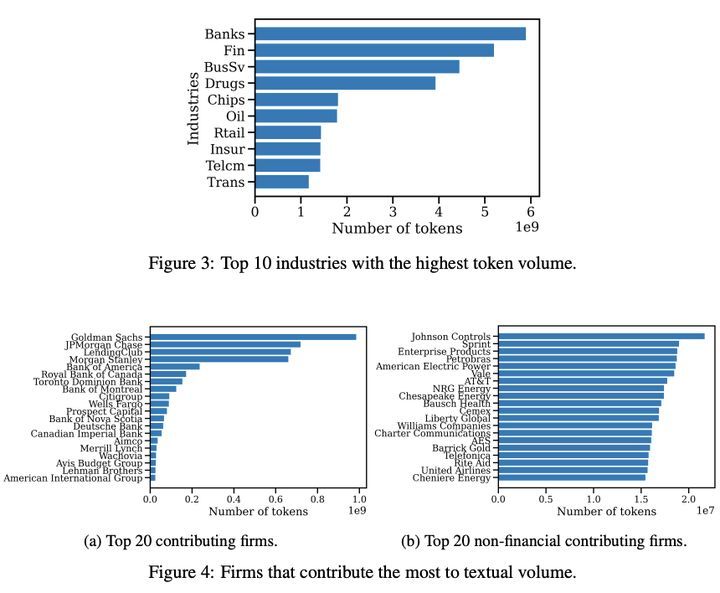
BeanCounter数据集是一个由芝加哥大学推出的大型商业披露文本数据集,包含超过1590亿个词汇,是目前公开可用的同类数据集中最大的一个。
数据集构建:
BeanCounter数据集从美国证券交易委员会(SEC)的EDGAR系统中提取,涵盖了企业向投资者和监管机构披露的各种公告。
数据集特点:
- 覆盖复杂几何形状:数据集包含多种商业文件类型,从简单的年报到复杂的信用协议。
- 包含多物理场模拟:数据集不仅包括文本内容,还涵盖了与这些文本相关的时间戳和元数据。
- 提供详细评估指标:研究者提供了多种评估模型性能的指标,包括毒性分析和领域特定任务的性能。
基准测试:
基准测试显示,在BeanCounter数据集上训练的模型在金融领域的应用中表现更好,同时生成的有毒内容减少了18-33%。
三、展望BeanCounter数据集的应用:
比如,我是一名金融分析师。
我的任务是深入研究一家公司的财务状况和市场表现。我要从从各种渠道搜集公司的年报、季度报告、新闻稿,甚至是行业分析报告。我需要需要一页一页地翻看这些报告,提取关键的财务数据,比如营收、利润、负债等。接下来,我需要把这些数据输入到Excel或专业的财务分析软件中,进行进一步的分析。最后,根据分析结果,撰写投资报告,预测公司未来的发展趋势。 通常要加班才能搞定。
现在可好,有了BeanCounter数据集训练的智能系统
我直接在电脑上输入公司名称或股票代码,唰唰唰,该公司历年的财报、公告、甚至市场反应相关材料全都一目了然。智能系统通过深度学习模型,能够自动识别和提取关键的财务指标,并且实时生成分析图表。我只需要对系统说:帮我生产一份报告,包含分析公司的财务数据,评估其市场策略,甚至预测未来的发展趋势。再也不用翻阅厚重的纸质文档或等待缓慢的人工处理了。这就像是拥有了一本实时更新的金融百科全书,但我的“阅读”速度是光速的
这个系统不仅提高了我的工作效率,也让我能够提供更加深入和精准的分析,帮助我的投资者或公司做出更明智的投资决策。 当然,我也不用加班,可以早点下班了。















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









