








 超级会员免费看
超级会员免费看

 本文介绍了Flink的异步IO算子,用于优化流处理中对外部数据的耗时查询。通过对比同步IO、线程池模式和异步IO的示例,展示了异步IO在提高系统吞吐量上的优势。同时,文章强调了使用异步IO时的注意事项,包括避免在asyncInvoke中进行耗时操作、处理超时回调以及确保正确完成异步请求。
本文介绍了Flink的异步IO算子,用于优化流处理中对外部数据的耗时查询。通过对比同步IO、线程池模式和异步IO的示例,展示了异步IO在提高系统吞吐量上的优势。同时,文章强调了使用异步IO时的注意事项,包括避免在asyncInvoke中进行耗时操作、处理超时回调以及确保正确完成异步请求。
上篇介绍了常见的算子,本文介绍另外一个重要的算子:Async I/O,即异步IO。它是流中频繁访问外部数据的利器,特别是当访问比较耗时的时候。
产生背景
先考虑一个实际中挺常见的场景:一个流处理程序中对于每个事件都要查一次外部的维表(比如HBase,这里暂不考虑缓存机制)做关联,那在Flink中如何实现呢?典型的做法就是增加一个map/flatmap,在里面做一下查询关联。这样功能没问题,但这个查询很容易会变成系统的瓶颈,特别是当外部查询比较耗时的时候。好在Flink里面有一个异步IO算子,可以很好的解决这个问题。
异步IO是阿里巴巴贡献给Flink非常重要的一个特性,在Flink 1.2版本中正式发布,对应的提案是FLIP-12: Asynchronous I/O Design and Implementation。这个特性解决的问题和所有其它的异步IO、IO多路复用技术是一致的:IO往往比较耗时,通过异步IO可以提高系统的吞吐量。这个Async I/O特性只不过是流处理场景里面的异步IO而已,原理没有什么特殊之处,看下官方的一个图:
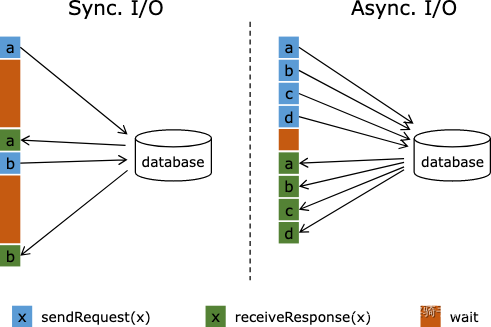
左侧是同步IO,可以看到大部分时间用来等待了;右侧是异步IO,提升效果很明显。当然,通过提高任务的并行度也能一定程度的缓解同步IO的问题,这种方式有点类似于网络编程早期的per-connection-per-thread模型,但这种模式不够彻底,而且提高并行度的代价比较高。道理都懂,就不再赘述了,下面看怎么用。
如何使用
使用概述
回想一下网络编程中的异步IO(这里指的是IO多路复用技术),必须要内核支持select、poll/epoll才可以。Flink的异步IO也类似,需要访问外部数据的客户端支持异步请求才可以。如果不支持的话,也可以通过线程池技术模拟异步请求,当然效果上会差一些,但一般还是比同步IO强的。具体到编码层面,分3个步骤:
- 1.实现
AsyncFunction接口,这个接口的作用是分发请求。Flink内置了一个实现类RichAsyncFunction,一般我们继承这个类即可。 - 2.在
AsyncFunction#asyncInvoke(...)中实现一个回调函数,在回调函数中获取异步执行的结果,并且传递给ResultFuture。 - 3.将异步操作应用到某个流上面。
下面是官方给的一段示例代码:
// This example implements the asynchronous request and callback with Futures that have the
// interface of Java 8's futures (which is the same one followed by Flink's Future)
/**
* An implementation of the 'AsyncFunction' that sends requests and sets the callback.
* 第1步:实现`AsyncFunction`接口
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** The database specific client that can issue concurrent requests with callbacks */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future<String> result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
// 第2步:实现一个回调函数
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
// 获取异步执行的结果
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
// 并且传递给`ResultFuture`
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream<String> stream = ...;
// apply the async I/O transformation
// 第3步:将异步操作应用到某个流上面。
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
同步模式&线程池模式&异步模式对比demo
这部分主要是给了两个示例,演示如何使用Flink异步IO。
第一个例子中包含了3种场景:
- 在flatmap中实现外部访问的同步IO
- 使用线程池实现的异步IO,且不保证顺序
- 使用线程池实现的异步IO,且保证顺序
其中,为了体现异步IO的优势,并没有真正访问数据库,而是使用了一个sleep操作,模拟比较耗时的IO操作。
public void update(Tuple2<String, Integer> tuple2) throws SQLException {
// 为了模拟耗时IO,这里使用sleep替换真正的数据库操作
//ps.setLong(1, balance);
//ps.setLong(2, 1);
//ps.execute();
try {
Thread.sleep(tuple2.f1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
注意:虽然没有真正访问数据库,但整个代码都是按照模拟真实场景写的,只是把里面执行数据库操作的换成了sleep,所以运行时还是会连接数据库、创建连接池。如果要自己运行代码,请修改代码中的数据库连接地址。另外,3个场景使用的数据源是同一个,而sleep的时间也是在数据源中定义好的,所以它们的IO耗时是相同的:
static List<Tuple2<String, Integer>> dataset() {
List<Tuple2<String, Integer>> dataset = new ArrayList<>(10);
for (int i = 0; i < 10; i++) {
// f0: 元素名称 f1: sleep的时间,模拟该元素需要的IO耗时
dataset.add(new Tuple2<>("e" + i, i % 3 + 1));
}
return dataset;
}
下面是完整代码:
package com.flinkpro.asynctest;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* @Author: cuiwenxu
* @Date: 2022/2/15 3:20 下午
*/
public class ThreadPoolAsyncDemoFakeQuery {
public static void main(String[] args) throws Exception {
// --------------------------------- Async IO + Unordered -------------------------
StreamExecutionEnvironment envAsyncUnordered = StreamExecutionEnvironment.getExecutionEnvironment();
envAsyncUnordered.setParallelism(1);
envAsyncUnordered.setBufferTimeout(0);
DataStream<Tuple2<String, Integer>> source = envAsyncUnordered.fromCollection(dataset());
DataStream<String> result = AsyncDataStream.unorderedWait(source, new ThreadPoolAsyncMysqlRequest(),
10, TimeUnit.SECONDS, 10);
result.print();
System.out.println("Async + UnorderedWait:");
envAsyncUnordered.execute("unorderedWait");
// --------------------------------- Async IO + Ordered -------------------------
StreamExecutionEnvironment envAsyncOrdered = StreamExecutionEnvironment.getExecutionEnvironment();
envAsyncOrdered.setParallelism(1);
envAsyncOrdered.setBufferTimeout(0);
AsyncDataStream.orderedWait(envAsyncOrdered.fromCollection(dataset()),
new ThreadPoolAsyncMysqlRequest(), 10, TimeUnit.SECONDS, 10)
.print();
System.out.println("Async + OrderedWait");
envAsyncOrdered.execute("orderedWait");
// --------------------------------- Sync IO -------------------------
StreamExecutionEnvironment envSync = StreamExecutionEnvironment.getExecutionEnvironment();
envSync.setParallelism(1);
envSync.setBufferTimeout(0);
envSync.fromCollection(dataset())
.process(new ProcessFunction<Tuple2<String, Integer>, String>() {
private transient MysqlClient client;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
client = new MysqlClient();
}
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<String> out) throws Exception {
try {
client.update(value);
out.collect(value + ": " + System.currentTimeMillis());
} catch (Exception e) {
e.printStackTrace();
}
}
}).print();
System.out.println("Sync IO:");
envSync.execute("Sync IO");
}
static List<Tuple2<String, Integer>> dataset() {
List<Tuple2<String, Integer>> dataset = new ArrayList<>(10);
for (int i = 0; i < 10; i++) {
// f0: 元素名称 f1: sleep的时间
dataset.add(new Tuple2<>("e" + i, i % 3 + 1));
}
return dataset;
}
static class ThreadPoolAsyncMysqlRequest extends RichAsyncFunction<Tuple2<String, Integer>, String> {
private transient ExecutorService executor;
private transient MysqlClient client;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
executor = Executors.newFixedThreadPool(30);
client = new MysqlClient();
}
@Override
public void asyncInvoke(Tuple2<String, Integer> input, ResultFuture<String> resultFuture) {
executor.submit(() -> {
long current = System.currentTimeMillis();
String output = input + ":" + current;
try {
client.update(input);
resultFuture.complete(Collections.singleton(output));
} catch (SQLException e) {
e.printStackTrace();
resultFuture.complete(Collections.singleton(input + ": " + e.getMessage()));
}
});
}
@Override
public void timeout(Tuple2<String, Integer> input, ResultFuture<String> resultFuture) throws Exception {
System.out.printf("%s timeout\n", input);
resultFuture.complete(Collections.singleton(input + ": time out"));
}
@Override
public void close() throws Exception {
client.close();
super.close();
}
}
static class MysqlClient {
// static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
// static final String DB_URL = "jdbc:mysql://10.9.1.18:3306/test?useSSL=false";
// private Connection conn;
// private PreparedStatement ps;
public MysqlClient() throws Exception {
// Class.forName(JDBC_DRIVER);
// conn = DriverManager.getConnection(DB_URL, "root", "root123.");
// ps = conn.prepareStatement("UPDATE account SET balance = ? WHERE id = ?;");
}
public void update(Tuple2<String, Integer> tuple2) throws SQLException {
// 为了模拟耗时IO,这里使用sleep替换真正的数据库操作
//ps.setLong(1, balance);
//ps.setLong(2, 1);
//ps.execute();
try {
Thread.sleep(tuple2.f1 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void close() {
// try {
// if (conn != null) {
// conn.close();
// }
// if (ps != null) {
// ps.close();
// }
// } catch (Exception e) {
// e.printStackTrace();
// }
}
}
}
执行结果:
Async + UnorderedWait:
(e0,1):1644914599209
(e3,1):1644914599209
(e9,1):1644914599211
(e6,1):1644914599210
(e7,2):1644914599210
(e1,2):1644914599209
(e4,2):1644914599210
(e5,3):1644914599210
(e2,3):1644914599209
(e8,3):1644914599210
Async + OrderedWait
(e0,1):1644914602431
(e1,2):1644914602432
(e2,3):1644914602432
(e3,1):1644914602432
(e4,2):1644914602432
(e5,3):1644914602432
(e6,1):1644914602432
(e7,2):1644914602432
(e8,3):1644914602432
(e9,1):1644914602432
Sync IO:
(e0,1): 1644914606613
(e1,2): 1644914608618
(e2,3): 1644914611623
(e3,1): 1644914612625
(e4,2): 1644914614630
(e5,3): 1644914617630
(e6,1): 1644914618633
(e7,2): 1644914620637
(e8,3): 1644914623641
(e9,1): 1644914624642
可以看到:
- Async + UnorderedWait:耗时4ms,且输出的事件是乱序的
- Async + OrderedWait:耗时2ms,输出事件是保持原有顺序的
- Sync IO:耗时26ms,输出的事件也是保持原有顺序的
该程序运行多次,输出不太稳定,但Async方式都是远远小于Sync的。因为数据量比较小,而且耗时都比较平均,所以无序的优势不明显,有时甚至还会比有序高。这个例子并不是一个严格的性能测试,但却可以用来体现Async相比于Sync的明显优势。
使用注意点
- 1.不要在AsyncFunction#asyncInvoke(…)内部执行比较耗时的操作,比如同步等待异步请求的结果(应该放到回调中执行)。因为一个流中每个Partition只有一个AsyncFunction实例,一个实例里面的数据是顺序调用asyncInvoke的,如果在里面执行耗时操作,那异步效果将大打折扣,如果同步等待异步的结果,那其实就退化成同步IO了。
- 2.异步请求超时回调默认是抛出异常,这样会导致整个Flink Job退出。这一般不是我们想要的,所以大多数时候都需要覆写timeout方法。
- 3.在自定义的回调函数里面一定要使用ResultFuture#complete或ResultFuture#completeExceptionally将执行结果传递给ResultFuture,否则异步请求会一直堆积在队列里面。当队列满了以后,整个任务流就卡主了。
- 4.Flink异步IO也是支持Checkpoint的,所以故障后可以恢复,提供Exactly-Once语义保证。
Q&A
Q1.使用RichMapFunction+自定义线程池不可以吗,为什么要用AsyncDataStream+RichAsyncFunction
Ans:自己开线程池可以,但是线程从外界返回的结果没办法回传到datastream流中,因为MapFunction中没有提供类似ResultFuture的句柄,详见如下代码
// --------------------------------- Async IO + mapfunction test -------------------------
envAsyncMapTest.fromCollection(dataset())
.map(new RichMapFunction<Tuple2<String, Integer>, String>() {
private transient ExecutorService executor;
private transient MysqlClient client;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
executor = Executors.newFixedThreadPool(30);
client = new MysqlClient();
}
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
executor.submit(() -> {
try {
client.update(value);
long current = System.currentTimeMillis();
String output = value + ":" + current;
return output;
} catch (SQLException e) {
e.printStackTrace();
}
return value;
});
return null;
}
})
.print();
System.out.println("Async + map function");
envAsyncMapTest.execute("asyncMapFunction");
有一种情况RichMapFunction+自定义线程池可以替代AsyncDataStream+RichAsyncFunction,也就是不需要从外部获取返回值,但是这种场景基本没什么意义,因为现实场景中为了保证可靠性,访问外部接口肯定是要获取调用状态的(即使不需要返回值,程序也需要知道是否调用成功)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









