






Spark的shuffle框架是从1.1版本开始的,提供了便于测试和扩展的可插拔式框架。在spark1.1之前,spark中只实现了一种shuffle方式,就是基于hash的shuffle。在基于hash的shuffle实现方式中,每个mapper阶段的task都会为每个reduce阶段的task生成一个文件,通常会产生大量的文件即M*R个文件,伴随着大量的磁盘IO及其大量的内存开销。
spark0.8.1中引入了基于hash的shuffle的实现引入了shuffleconsolidate机制,即合并文件机制,在mapper端生成的中间文件进行合并的处理机制。通过将spark.shuffle.consolidateFiles设置为true,来减少中间生成文件数量。最终将文件个数从M*R修改为E*(C/T)*R。其中E表示excutor个数,C表示可用的core个数,T表示task所分配的core个数,M表示mapper阶段task个数,R表示reducer阶段task个数。
基于hash的shuffle实现方式都会依赖于reduce阶段的task个数,spark1.1引入了基于sort的shuffle方式并且在1.2版本之后,默认方式也从hash变为了sort的shuffle方式,基于sort-shuffle的方式,mapper阶段的task不会为每个reduce阶段的task生成一个单独的文件,而是全部写到一个文件,意思就是mapper阶段的每个task只会生成两个文件 ,一个是数据文件一个是索引文件最终生成文件个数减少到2MB。并且通过标识变量设置可以对sort-shuffle判断是否进行分区的内部的排序。
随着spark1.4开始shuffle过程中逐渐开始引入基于Tungsten-Sort的shuffle方式,通过tungsten项目所做的优化,可以极大提高spark在数据处理上的性能。
shuffleManager类图如下:
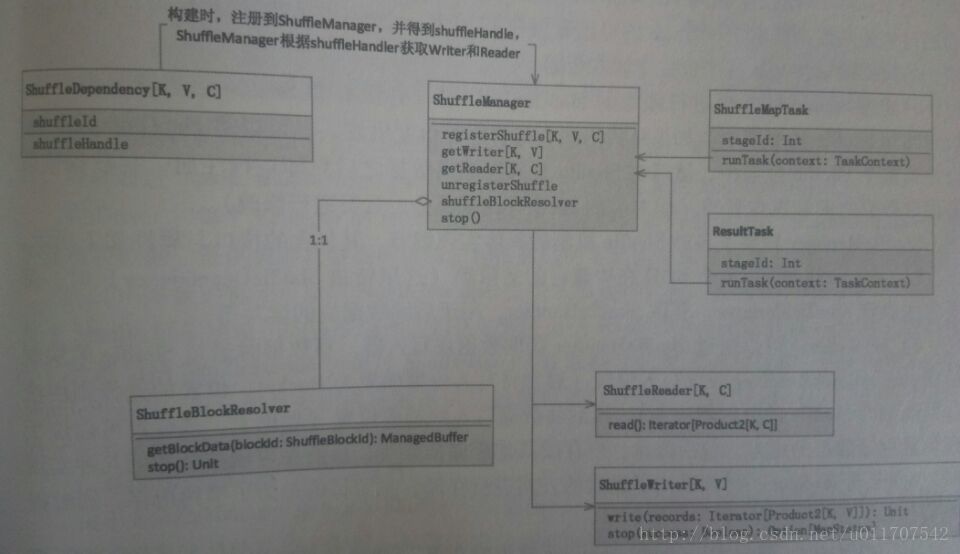
shuffle框架设计的两方面可以理解:一是为了shuffle模块更加内聚并与其他模块解耦;二是为了更方便测试 替换和扩展shuffle的不同实现方式。spark框架中通过shufflemanager来管理所有shuffle实现方式,尤其统一构建,管理具体实现子类来实现shuffle框架的可插拔式shuffle机制。
DAG在调度过程中,stage阶段划分是根据是否有shuffle过程,也就是当存在shuffledependency的宽依赖时候,需要shuffle。把job划分为多个stage。每个job左右提交最后都会生成一个ResultStage(作业结果所在的stage) 和若干个ShuffleMapStage。这两个中的task分别对应了ResultTask 和ShuffleMapTask。
shuffle框架源代码解析如下:
在SparkEnv.scala源码中如下:
// 下面三种已经支持的shufflemanager
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"tungsten-sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
//指定shufflemanager配置属性spark.shuffle.manager
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)ShufferManger.scala源码如下:
package org.apache.spark.shuffle
import org.apache.spark.{TaskContext, ShuffleDependency}
/**
* Shuffle 系统的可插拔接口 在Drive和每个Executor的SparkEnv实例中创建
*/
private[spark] trait ShuffleManager {
/**
* 在Driver端向ShuffleManager注册一个shuffle,获取一个handle,
* 在具体task中会通过该handle来读写数据
*/
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
/**
* 获取对应给定的分区所使用的ShuffleWriter 该方法在executor上执行 各个map任务时调用
*/
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V]
/**
* 获取在reduce阶段读取分区的ShuffleReader 对应读取的分区由【startPartition to endPartition-1】区间指定
* 该方法在executor上执行, 各个reduce时调用
* Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive).
* Called on executors by reduce tasks.
*/
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
/**
* 该接口和registershuffle 分别负责元数据的取消注册于注册
* 调用unregisterShuffle接口时候,会移除ShuffleManager中对应的元数据信息
*/
def unregisterShuffle(shuffleId: Int): Boolean
/**
*
* 返回 一个可以基于块坐标来获取Shuffle块数据的ShuffleBlockResolver
*/
def shuffleBlockResolver: ShuffleBlockResolver
/**
* 终止ShuffleManager
def stop(): Unit
}
ShuffleHandle.scala源码如下:
package org.apache.spark.shuffle
import org.apache.spark.annotation.DeveloperApi
/**
* ShuffleHandle用于记录task与shuffle相关的一些元数据,同时也可以作为不同具体shuffle实现机制的
* 一种标志信息,控制不同具体实现子类的选择等。
* An opaque handle to a shuffle, used by a ShuffleManager to pass information about it to tasks.
*
* @param shuffleId ID of the shuffle
*/
@DeveloperApi
abstract class ShuffleHandle(val shuffleId: Int) extends Serializable {}
ShuffleReader源代码如下:
package org.apache.spark.shuffle
/**
* 继承ShuffleReader每个具体的子类会实现read接口,计算时负责从上一个阶段stage的输出数据中读取记录
* Obtained inside a reduce task to read combined records from the mappers.
*/
private[spark] trait ShuffleReader[K, C] {
/** Read the combined key-values for this reduce task */
def read(): Iterator[Product2[K, C]]
/**
* Close this reader.
* TODO: Add this back when we make the ShuffleReader a developer API that others can implement
* (at which point this will likely be necessary).
*/
// def stop(): Unit
}
ShuffleWriter源代码如下:
import java.io.IOException
import org.apache.spark.scheduler.MapStatus
/**
* 继承ShuffleWriter的每个子类会实现write接口,给出任务在输出时的记录具体写的方法
* Obtained inside a map task to write out records to the shuffle system.
*/
private[spark] abstract class ShuffleWriter[K, V] {
/** Write a sequence of records to this task's output */
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
def stop(success: Boolean): Option[MapStatus]
}
ShuffleBlockResolver源码解析如下:
/**
* 该特质的具体实现子类知道如何通过一个逻辑shuffle块标识信息来获取一个块数据,具体实现可以使用文件或文件段来封装shuffle数据。这是获取shuffle块数据时所使用的抽象接口口,在BlockStore中使用
*/
trait ShuffleBlockResolver {
type ShuffleId = Int
/**
* 获取指定块的数据 如果指定块的数据无法获取 则抛异常
* Retrieve the data for the specified block. If the data for that block is not available,
* throws an unspecified exception.
*/
def getBlockData(blockId: ShuffleBlockId): ManagedBuffer
def stop(): Unit
}
ShuffleDependency类在Dependency.scala中
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
/**
* 唯一标识信息,可以看到是通过rdd的上下文去获取的,因此针对特定的rdd,每个shuffleId值都是唯一的
* */
val shuffleId: Int = _rdd.context.newShuffleId()
/**
* 获取ShuffleHandle实例,后续获取Shuffle写入器和读取器时需要
* */
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
/**
* Shuffle数据清理器的设置,可以扩展到当前使用外部Shuffle服务时,数据如何清理等
* */
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}














 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









