







*注:此笔记为个人在学习Oracle时从教学视频、参考书上摘录整理而成,纯手打完成,如需转载麻烦表明出处,附上连接(http://blog.csdn.net/sherkyoung/article/details/27712819),谢谢!
集合操作
在数学的操作中存在交、差、并、补的概念,在数据的查询中也存在这些概念,有如下几个连接符号:
l UNION:连接两个查询,相同的部分不显示
l UNION ALL:连接两个查询,相同的部分显示
l INTERSECT:返回两个查询中的相同部分
l MINUS:返回两个查询中的不同部分
为了验证以上的操作,下面创建一张包含20部门的雇员信息表:
CREATE TABLE emp20 AS SELECT * FROM emp WHERE deptno=20 ;
1、验证UNION;
SELECT * FROM emp
UNION
SELECT * FROM emp 20 ;
2、验证UNION ALL;
SELECT * FROM emp
UNION ALL
SELECT * FROM emp20 ;
3、验证INTERSECT;
SELECT * FROM emp
UNION
SELECT * FROM emp 20 ;
4、验证MINUS;
SELECT * FROM emp
UNION ALL
SELECT * FROM emp20 ;
序列(重点)
在许多数据表的操作之中都存在一种称之为自动增长的列操作。
而在Oracle中,这种自动增长列并不是自动控制的,而是需要用户手动控制的,这是为了开发的方便。创建序列的语法如下:
CREATE SEQUENCE sequence
[INCREMENT BY n][START WITH n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n| NOCACHE}] ;
范例:创建序列
CREATE SEQUENCE myseq ;
当创建了一个序列之后,可以通过以下的方式进行访问:
l 序列名.nextval:让序列增长到下一个内容;
l 序列名.currval:取得当前的内容 ;
范例:验证序列的操作
SELECT myseq.currval FROM dual ;
可是直接执行上面的程序会出现如下的错误提示:”ORA——08002:序列MYSEQ.CURRVAL尚未在此会话中定义”
在Oracle中如果想操作currval,则必须先使用nextval:
SELECT myseq.nextval FROM dual ;
SELECT myseq.currval FROM dual ;
序列一般都作为主键使用,例如下面定义一张表:
DROP TABLE mytab PURGE ;
CREATE TABLE mytab(
id NUMBER PRIMARY KEY,
name VARCHAR2(10) NOT NULL
) ;
下面向mytab表中插入数据
INSERT INTO mytab(id,name) VALUES(myseq.nextval,’姓名’) ;
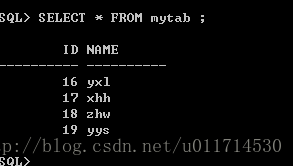
查看mytab表:
SELECT * FROM mytabl ;
在默认情况下序列好是从0开始的,但如果在插入数据之前调用了nextval则此时查看的mytab中的ID就不是从0开始了。
同时要记住,这个过程都是由用户自己手工完成,不能自动完成。
在默认情况下,序列从0开始,每次增长1,这也是可以修改的;
范例:创建序列,从10开始,每次增长2;
DROP SEQUENCE myseq ;
CREATE SEQUENCE myseq INCREMENT BY 2 START WITH 10 ;
范例:定义一个序列,这个序列可以在1、3、5、7、9之间循环出现;
DROP SEQUENCE myseq ;
CREATE SEQUENCE myseq INCREMENT BY 2 START WITH 1
MAXVALUE 10 MINVALUE 1 CYCLE NOCACHE ;
关于序列中的CHAHE解释:
在Oracle数据库中,由于序列经常被使用,所以为了提高性能,将序列的操作形式做了如下的处理。
首先,如果在用户每次使用序列的时候序列在增加,则肯定会造成一些性能上的损耗,所以在Oracle中专门为用户准备了一块空间,在这个空间中,为用户准备好了若干个已经生成的序列,每次操作的时候都是从这块空间中取出序列的内容,但这样做就有了一个新问题,如果现在数据库实例关闭了,那么保存在这块空间里的内容就有可能消失了,但是虽然消失了,数据已经增长好了,这样就会出现跳号的现象,而如果想要取消掉这种问题,最好的方法就是将序列的设置为不换村,使用NOCACHE进行声明。
前台工具:PLSQLDeveloper
l Oracle 8i/Oracle 9i:OEM(Oracle企业管理器)、sqlplusw、sqlplus
l Oracle 10g:EM(WEB)、sqlplusw、sqlplus
l Oracle 11g:EM(WEB)、sqlplus、SQLDeveloper(会JAVA)
但是在此之外有一个前台工具——PLSQLDEVELOPER,此工具是一个第三方软件,也是阿紫开发中使用的最多的前台工具。
回顾与总结
1、数据表的创建
a) 主要的数据类型:VARCHAR2、NUMBER、DATE、CLOB
b) 创建表的语法:CREATE TABLE 表名称 ;
c) 清空回收站:PURGE RECYCLEBIN;
2、约束:约束是保证数据表中的数据完整性的一种手段,约束一定要在建立表的同时设置好,而且在表真正使用之前一定要有约束:
a) 约束分类:
i. 非空约束(NOT NULL)
ii. 唯一约束(UNIQUE)
iii. 主键约束(PRIMARY KEY)
iv. 检查约束(CHECK)
v. 外键约束(FOEIGN)
b) 设置外键的时候有以下注意点
i. 默认情况下应该先删除子表在删除父表
ii. 级联删除:ON DELETE CASCADE ;
iii. 级联设置空:ON DELETE NULL ;
3、序列:SEQUENCE,可以形成自动增长列的操作
a) 序列中的两个属性:nextval,currval
b) 序列的操作一定要进行手工控制
视图(重点)
在之前所学的所有的SQL语法之中,查询操作是最麻烦的,如果程序员将大量的精力都浪费在查询语句的编写上,则肯定会影响代码的工作进度,所以一个好的数据库设计人员,除了根据业务的草哦做设计出数据表之外,还需要为用户提供若干个试图,而每一个试图包装了一系列复杂的SQL语句,而视图的创建语法如下:
CREATE [OR REPLACE] VIEW 视图名称
AS 子查询 ;
范例:创建一张视图
CREATE VIEW myview AS
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno) mycount,AVG(e.sal) myave
FROM emp e,dept d
WHERE e.deptno(+)=d.deptno
GROUP BY d.deptno,d.dname,d.loc ;
这里有两个地方需要注意一下:
1、创建试图的语句中不能直接使用函数名,而不必须给函数取个别名,如上述代码中的mycount和myave
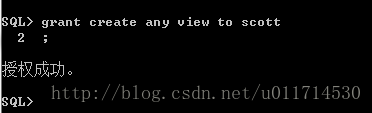
2、我在输入上述代码的时候sqlplus报错,提示权限够。这是scott这个用户默认情况下没有创视图的权限,解决办法:
第一步:切换用户,使用system用户
Win+R打开运行,输入:sqlplus system\manager (manage为sys特码用户密码)
第二步:
输入:GRANT CREAT ANY VIEW SCOTT ; 进行授权。
现在就创建了一个名为myview的视图,现在对myview进行查询:
SELECT * FROM myview ;
此时就会发现查询myview与之前的复杂SQL语句查询结果是一致的。
OR REPLACE
不存在则创建,存在则替换
创建视图的视乎存在两个选项
l 选项一:WTH CHECK OPTION
上面创建的视图,是存在一个创建条件WHERE deptno=20,那么如果现在更新视图中的这个条件呢?
UPDATE myview SET deptno=30 WHEREempbo=7369 ;
此时更新的是一张视图,但是视图本身并不是一个具体的数据表,而且现在更新操作又是视图的创建条件,这样的做法不可取,所以此时为了解决这个问题,可以加入WITH CHECK OPTION;
CREATE OP REPLACE VIEW myview AS
SELECT * FROM emp WHERE deptno=20
WITH CHECK OPTION ;
此时再次执行视图的更新操作,会出现如下错误提示:视图WITH CHECK OPTION where子句违规
意味着现在根本就不能去更行视图创建条件。
l 选项二:WITH READ ONLY
虽然使用WITH CHECK OPTION可以保证视图的创建条件不被更新,但是其他字段还是允许更新的。
UPDATE myview SET sal=9000 WHERE empno=7369 ;
与之前的问题一样,视图本身不是具体的真实数据,而是一些查询语句,所以这样的更新并不合理,那么在创建视图的时候建议将其设置为只读视图:
CREATE OR REPLACE VIEW myview AS
SELECT * FROM emp WHERE deptno=20
WITH READ ONLY ;
此时再次发出更新操作,则直接提示如下错误:此处不允许虚拟列
而且一定要注意,以上给出的是一个简单的操作语句的视图,但是如果现在视图中的查询语句是统计操作,则根本不可能更新;
CREATE OR REPLACE VIEW myview AS
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno) mycount,AVG(e.sal) myave
FROM emp e,dept d
WHERE e.deptno(+)=d.deptno
GROUP BY d.deptno,d.dname,d.loc ;
现在这些信息是统计而来的,根本不能更新。
在一个项目之中,视图的数量可能超过表的数量,因为查询语句会很多。
同义词
就是意思相近的一组词语,实际上对于同义词的操作之前已知在使用,如下的一个查询语句:
SELECT SYSDATE FROM dual ;
在之前就说过“dual”是一张虚拟的表,但是虚拟表肯定有它自己非用户,经过查询可以发现,这张表是属于sys用户的,但是这个时候出现乐一个问题,再之前讲解过,不同的用户想要访问其他用户的表,则需要写上“用户名称”.“表名称”,那么此时为什么scott用户访问的时候直接使用dual即可。而不使用“sys.dual”呢,这个实际上就是同义词的应用,dual表示的是sys.dual的同义词,而同义在Oracle中称为SYNONYM,同义词的创建语法如下:
CREATE [PUBLIC] SYNONYM 同义词的名称 FOR 用户表名称 ;
范例:下面创建一个同义词为myemp,此同义词指向scott.emp
CREATE SYNONYM myemp FOR scott.emp ;
此时创建成功之后,以后在sys用户中就可以使用myemp这个同义词名称了,但是曾格格同义词只适合sys用户个人使用没其他用户无法使用,因为创建的时候没有使用PUBLIC,如果没有使用,则表示创建的不是公共同义词。
范例:创建公同义词
DROP SYNONYM myemp
CREATE PUBLIC SYNONYM myemp FOR scott.emp ;
但是同义词也只是Oracle自己的概念,其他数据库中并没有,了解即可。
索引
索引的主要功能就是提升数据库的操作性能。
纠正一个误区:性能优化的技术服务。而这些所谓的性能优化大部分指的是不规范的卡发项目。
下面通过代码分析一个简单的索引操作:
SELECT * FROM emp where sal>1500 ;
此时由于在sal上没有设置索引,所以在sal的判断上是逐行判断的。这种操作随着数据量的上升,性能会出现问题,但是如果将数据排列一下呢?
例如:现在将工作在内存之中形成这样的一种数据结构;
1600、1500、2850、1250、2450、3000、5000、800
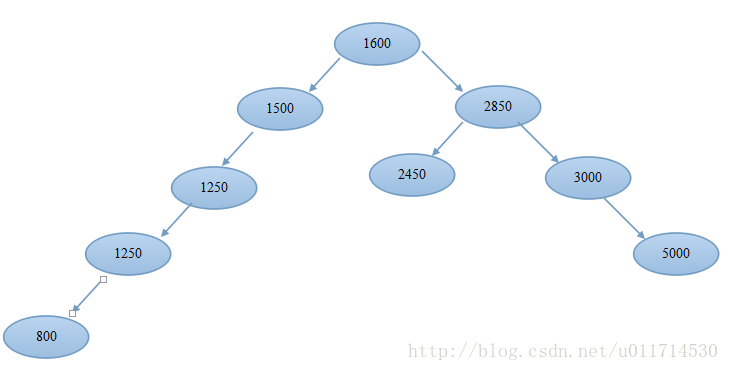
如果现在假设所有的数据都排列成以上的树型挤乳沟的话,同样的查询,现在还会查询全部记录么?只会查询部分
在Oracle中创建索引有一下两种方式:
l 主键约束:如果一张表中的列撒谎能够存在了主键约束的话自动创建索引
l 手工创建:在某一操作列上指定一个索引
范例:在emp.sal字段上创建索引
CREATE INDEX emp_sal_ind ON emp(sal) ;
虽然索引创建完成了,但是无法观察出其特点。
但是这种索引有一个最大的问题,即:如果想要实现性能的提高,则必须始终维持以上一棵树那么如果说这棵树上的数据需要修改的话,则代码的性能肯定会有所降低。
所以一般索引只是用在不会频繁修改的表中,而如果一张表上频繁修改数据且又使用了索引,那么性能肯定会严重降低,所以说性能提升永远都是相对的。
以上的索引只是Oracle实际中索引中的一种也是最简单的一种称为B树索引,还有其他很多的索引。
用户管理
SQL语句分为三类:DML、DDL和DCL,现在只剩下DCL没讲了。DCL就是数据库的控制语言,控制的就是操作权限,而在DCL中,主要有两个语法:GRANT、REVOKE;
权限的操作基础需要有用户,而这个时候就需要通过一个新的用户来进行演示,而要想创建新用户,就必须是具备管理员操作权限的sys或system用户。
范例:创建一个person的用户,密码是huang
CREATE USER person IDENTIFIED BY huang ;
此时一个新的用户就创建成功了,此时登录新用户时,会提示用户现在没有创建session的权限,之前有提到过,对于sqlplus而言,每一个用户就是一个SESSION,如果没有创建SESSION的权限就不能登录
范例:给person用户创建SESSION的权限
GRANT CREATE SESSION TO person ;
现在新用户登录成功之后就可以执行表的创建工作了
CREATE TABLE mytab(
ID NUMBER PRIMARY KEY ,
name VARCHAR2() NOT NULL,
age NUMBER
)
但是此时却无法创建
解释:关于数据表的保存问题
在Oracle中所有的数据表都是保存在硬盘上的,但不是每一张数据表都是保存在硬盘上的,而是表空间保存在硬盘上,而数据表保存在表空间之中。
如果把硬盘表示成一个图书馆的话,那么表空间就是一个个书柜,每一张表表就表示是一本书。
范例:将创建表的权限给person用户
GRANT CREATETABLE TO person ;
此时只是将创建表的权限给person用户,但是没有将使用表空间的权限给用户。
为了解决用户的授权操作,在Oracle’之中为用户提供了很多的角色,每一个角色都会包含多个权限,而角色主要有两个:CONNECT,RESOURCE ;
范例:将CONNECT和RESOURCE角色给person用户
GRANT CONNECT,RESOURCE TO person ;
但是现在一旦存在了用户的操作,那么就需要有用户的管理操作,如修改密码:
范例:修改密码
ALTER USER person INDETIFIED ke ;
但是当管理员为一个用户重置了密码之后,往往会希望用户在第一次登录的时候就可以修改密码,所以此时可以通过命令使密码失效;
ALTER USER person PASSWORD EXPIRE ;
亦可已控制一个账户的锁定操作
ALTER USER person ACCOUNT LOCK ;
ALTER USER person ACCOUNT UNLOCK ;
以上就是对一个基本用户的操作,但是再之前也学习过,不同的用户可以访问其他用户的数据表,此时只需要加上完整的”用户名.表名称”即可。
范例:使用person用户查询scott.emp表 ;
SELECT * FROM scott.emp ;
但是现在却无法查找,此时需要将scott用户的权限授予person用户才可以让person用户访问scott用户的资源,主要权限有四个:INSERT、DELETE、UPDATE、SELECT
范例:将scott.emp表的SELECT和INSERT权限给personyonghu
GRANT SELECT INSERT ON scott.emp TO person ;
既然现在有授权的功能,那么就可以进行授权的回收,权限的回收使用REVOKE指令
范例:回收person用户的权限
DROP USER person CASCADE ;
在工作中,以上操作都是由DBA来完成的,个人基本用不到。
数据库的备份
数据库的备份操作是在整个项目运行中最重要的工作之一。
数据的导出和导入
数据的导出了导入是针对一个用户的备份操作,可以按照以下的方式来完成:
1、数据的导出
l 在硬盘上建立一个文件夹:d:\backup
l 输入exp指令;
l 输入用户名和密码;
l 设置到导出文件的名称;导出文件:EXPDAT.DMP;
2、数据的导入
l 进入到导出文件所在的文件夹之中:cd dbbackup ;
l 输入imp指令 ;
l 导入整个导出文件(yes/no):no>yes ;
但是以上的操作只是作为一种演示,只适用与数据量很小的情况,如果数据量较大,这种操作就非常损耗性能,而且时间也很长,想要解决大数据量的问题只能对数据分区操作。
数据表的冷备份
在数据库中,有可能有些用户不会进行事务的提交,那么现在这种情况之下很可能无法进行完整的备份操作,而所谓的备份指的就是在关闭数据库实例的情况下进行数据库备份操作的实现。
如果要进行冷备份,则需要备份出数据库中的一些几个核心内容:
l 控制文件:指的是控制整个Oracle数据库的实例服务的核心文件,直接通过“v$controlfile”找到;
l 重做日志文件:可以进行数据的灾难恢复,直接通过“v$logfile”找到;
l 数据文件、表空间文件:通过“v$datafile”和“v$tablesapce”找到 ;
l 核心操作的配置文件(pfile),通过“SHOW PARAMETER.pfile”找到 ;
从实际的Oracle部署来讲,所有的文件为了达到IO的平衡操作,要保存在不同的硬盘上。
确定了要备份的文件之后,下面按照如下的步骤查找:
1、使用超级管理员账户登录
CONN system/change_on_install AS SYSTEMABA ;(change_on_install为system用户密码)
2、查找所有的控制文件目录
SELECT * FROM v$controlfile ;
3、备份重做日志文件
SELECT * FROM v$logfile ;
4、查找表空间文件
SELECT * FROM v$tablbspace ;
SELECT * FROM v$datafile ;
5、找到pfile文件
SHOW PARAMETER pfile ;
6、关闭数据库实例
SHOWDOWN IMMEDIATE ;
7、将所有查找到的数据备份到从盘上;
8、启动数据库实例
STARTUP
一个专业的DBA开发人员必须熟练以上的步骤,这样才可能在哦出现灾难孩子后进行及时的恢复。
数据库设计范式
数据库设计范式是一个重要的概念,但是这个重要的程度只是适合月参考,使用的数据设计范式,可以让数据表更好的进行数据的保存,因为再合理的设计如果数据量足够大也会存在性能上的问题,所以在开发之中,唯一可以被称为设计宝典的就是:设计的时候尽量避免日后的程序中出现多表查询。
第一范式
第一范式:指的就是数据表中的数据列不可再分。例如,以下的一张表:
CREATE TABLE member(
Mid NUMBER PRIMARY KEY ,
Name VARCHAR2(10) NOT NULL ,
Contact VARCHAR2(200)
) ;
这个时候表的设计就不怎么合理,因为联系方式由多种数据组成:电话、地址、手机、email、邮编等等,所以这种设计是不符合第一范式的,现在修改为:
CREATE TABLE member(
Mid NUMBER PRIMARY KEY ,
Name VARCHAR2(10) NOT NULL ,
Moblie NUMBER NOT NULL,
Email VARCHAR2()
) ;
这里还有两点要说明:
1、关于姓名:在国外的表的设计中也要分为姓和名,国内是不需要的
2、关于生日:生日有专门的数据类型(DATE),所以不能将其设置成”生日-年”,”生日-月”,”生日-日”
所谓的不可再分指的是所有的数据类型都使用数据库提供好的各个数据类型。
第二范式
第二范式:数据表中的非关键字段存在对任意候选字段的部分函数依赖
第二范式分为两部分理解:
n 理解一:列之间不存在函数关系,如下设计:
CREATE TABLE orders(
Oid NUMBER PRIMARY KEY ,
Amount NUMBER NOT NULL ,
Price NUMBER ,
Allprice NUMBER
) ;
此时的列字段中的allprice就与price和amount字段有函数关系,不符合第二范式。
n 理解二:通过一个例子来展现,如下建表
CREATE TABLE studntcourse(
Stuid NUMBER PRIMARY,
Stuname VARCHAR2(10) NOT NULL ,
Cname VARCHAR2(10) NOT NULL ,
Sredit NUMBER NOT NULL ,
Score NUMBER NOT NULL
);
INSERT INTO studentcourse(stuid,stuname,cname,credit,score)
VALUES(1,’zhang3’,’java’,3,89) ;
INSERT INTO studentcourse(stuid,stuname,cname,credit,score)
VALUES(1,’li4’,’java’,3,99) ;
INSERT INTO studentcourse(stuid,stuname,cname,credit,score)
VALUES(1,’wang5’,’java’,3,79) ;
INSERT INTO studentcourse(stuid,stuname,cname,credit,score)
VALUES(1,’zhang3’,’Oracle’,1,89) ;
这种设计虽然符合第一范式但是不符合第二范式,因为程序会出现如下错误:
1、数据重复:学生和课=课程都处于重复的状态,而且最为严重的是主键的设置问题
2、数据更新过多的时:如果更新了学分的分值而又有很多人都选了这门课,那么就要对这些学生的记录全部进行修改
3、如果有一些课没有人选,那么这门课的相关信息就全部消失,不再数据库中保存。
此时可以对程序进行如下修改:
CREATE TABLE student (
Stuid NUMBER PRIMARY KEY ,
Stuname VARCHAR2(10) NOT NULL
) ;
CREATE TABLE course(
Cid NUMBER PRIMARY KEY ,
Cname VARCHAR2(20) NOT NULL ,
Cedit NUMBER NOT NULL
) ;
CREATE TABLE grade(
Stuid NUMBER REFERENCES student(stuid) ,
Cid NUMBER RESERENCES course(cid) ,
Score NUMBER NOT NULL
) ;
INSERT INTO student(stuid,stuname) VALUES(1,’zhang3’) ;
INSERT INTO student(stuid,stuname) VALUES(2,’li4’) ;
INSERT INTO student(stuid,stuname) VALUES(3,’wang5’) ;
INSERT INTO course(cid,cname) VALUES(10,’java’,3) ;
INSERT INTO course(cid,cname) VALUES(20,’oracle’,1) ;
INSERT INTO course(cid,cname) VALUES(30,’linux’,5) ;
INSET INTO studentcourse(stuid,cid,score) VALUES(1,10,89) ;
INSET INTO studentcourse(stuid,cid,score) VALUES(2,10,99) ;
INSET INTO studentcourse(stuid,cid,score) VALUES(3,10,79) ;
第二范式从表的设计上来说就是多对多的关系。
第三范式
例如,现在一个学校有多个学生,如果用第一范式无法实现,而如果用第二范式则表示多对多的关系,即:一个学校有多个学生,一个学生有多个学校,不符合要求,所以此时可以使用第三范式。参考之前的部门和雇员的操作实现,创建如下代码:
CREATE TABLE school(
Sid NUMBER PRIMARY KEY ,
Sname VARCHAR(20) NOT NULL
) ;
CREATE TBALE student(
Stuid NUMBER PRIMARY ,
Stuname VARCHAR2() NOT NULL ,
Sid NUMBER REFERENCES school(sid)
) ;
这里就体现了一对多的关系,而在实际工作之中,第三范式的使用是最多的。
以上的三个范式只是作为参考使用,实际中的问题需要具体问题具体分析。
数据库的设计工具:PowerDesigner
对于数据库设计工具,其中最著名的就是sybase的PowerDesigner。
现在要进行数据表的设计,则建立物理数据模型。
使用这个工具最大的好处了自动生成数据库的创建脚本。
这个生成后的数据库创建脚本,建议还是进行一些修改,以满足个人的操作习惯。
但是在PowerDesigner工具也可以从数据库中导出数据表的表结构,如果想要完成此操作,则必须配置ODBC数据源。ODBC数据源是微软的一种数据库连接操作模式。
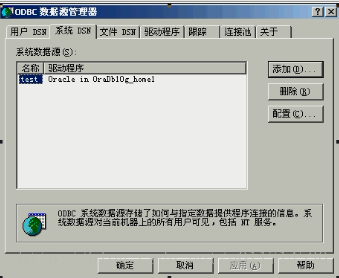
此时打开数据库然后点击下图的按钮:
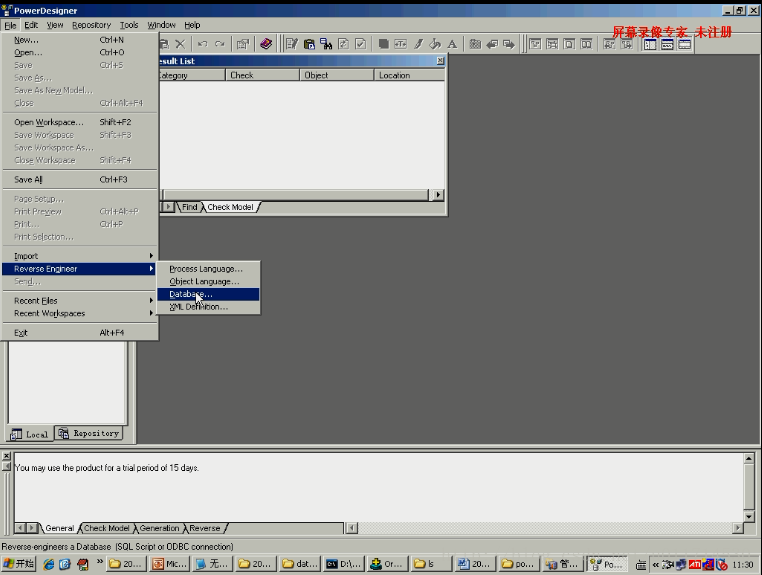
这就是帮助用户将数据库中的表结构自动导出














 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









