









基于麻雀搜索算法优化的SVM回归预测
摘要:利用麻雀搜索算法对SVM回归预测进行优化。优化参数主要是SVM的惩罚参数和核惩罚参数。优化结果表面麻雀搜索算法能够提升SVM的性能。
1.数据集
测试数据:上证指数 ( 1990. 12. 19-2009.08. 19)
整体数据存储在 chapter_sh. mat ,数据是一个 4 579 × 6 的 double 型矩阵,记录的是从1990 年 12 月 19 日开始到 2009 年 8 月 19 日这期间内 4579 个交易日每日上证综合指数的各 种指标,1579 行表示每一天的上证指数的各种指标, 6 列分别表示当天上证指数的开盘指数、 指数最高值、指数最低值、收盘指数、当日交易量、 当 日交易额。上证指数每日的开盘指数如图1所示 。
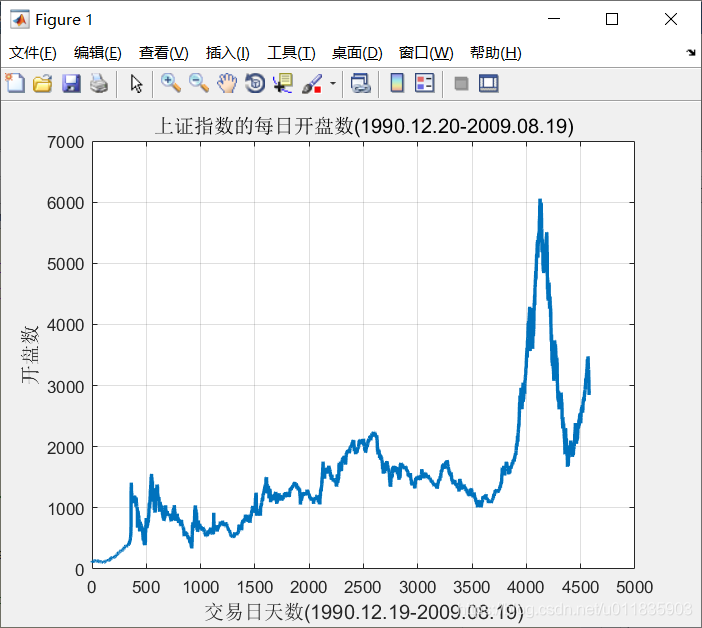
模型目的:利用 SVM 建立的回归模型对上证指数每日的开盘数进行回归拟合.
模型假设:假设上证指数每日的开盘数与前一日的开盘指数、指数最高值、指数最低值、收盘指数、交易量、交易额相关,即把前一日的开盘指数、指数最高值、指数最低值、收盘指数、交易量、交易额作为当日开盘指数的自变量,当日的开盘指数为因变量。
算法流程图如下图2所示:

3.模型处理
选取第 1 ~ 4 578 个交易日内每日的开盘指数、指数最高值、指数最低值,收盘指数、交易量、交易额作为自变量 ,选取第 2~4 579 个交易日内每日的开盘数作为因变量 .同时对数据进行归一化处理。
4.基于麻雀搜索的SVM回归预测
麻雀搜索算法的具体原理参考博客:https://blog.csdn.net/u011835903/article/details/108830958。
优化参数主要是SVM的惩罚参数和核惩罚参数。是适应度函数设计为:
f
i
t
n
e
s
s
=
a
r
g
m
i
n
(
M
S
E
p
r
i
d
e
c
t
)
fitness = argmin(MSE_{pridect})
fitness=argmin(MSEpridect)
适应度函数选取SVM训练后的MSE误差。MSE误差越小表明预测的数据与原始数据重合度越高。
5.测试结果:
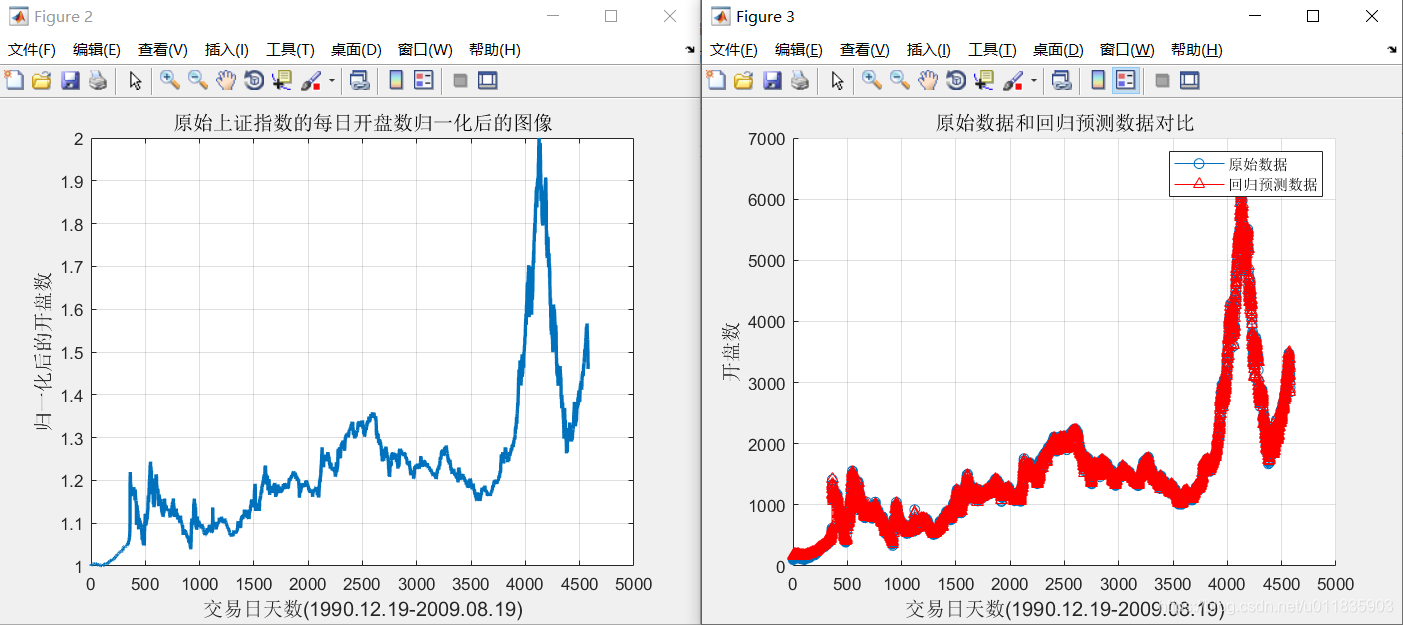
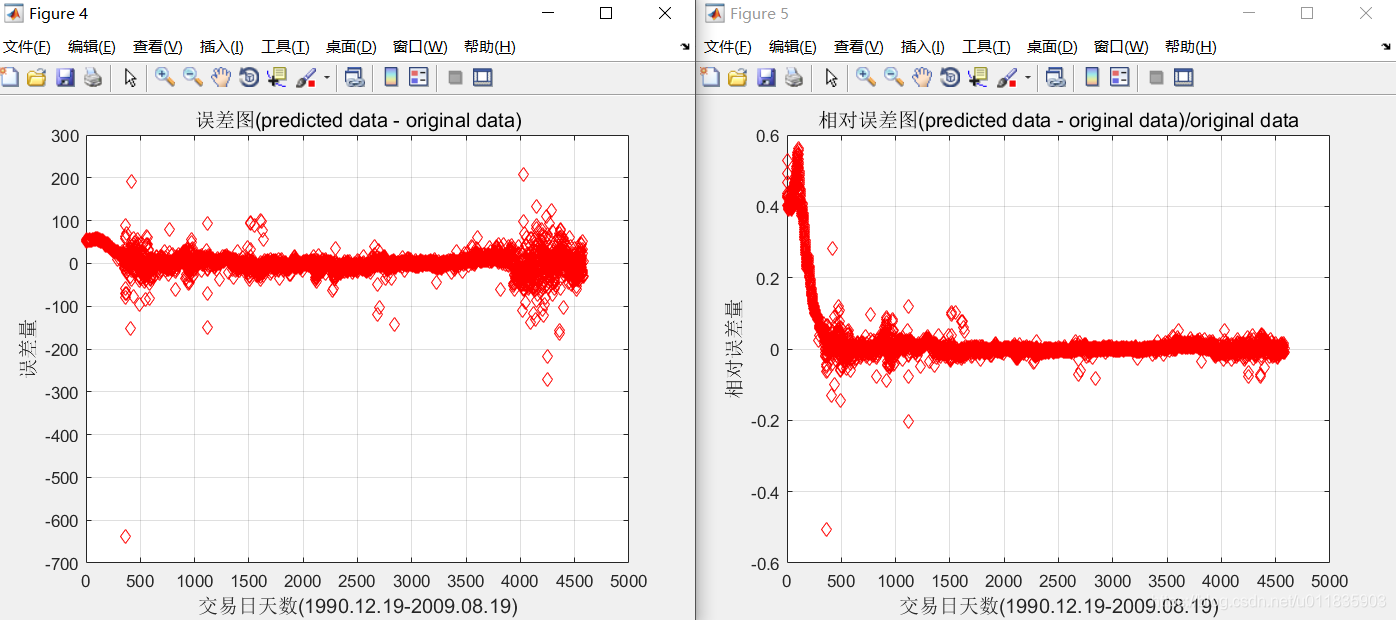
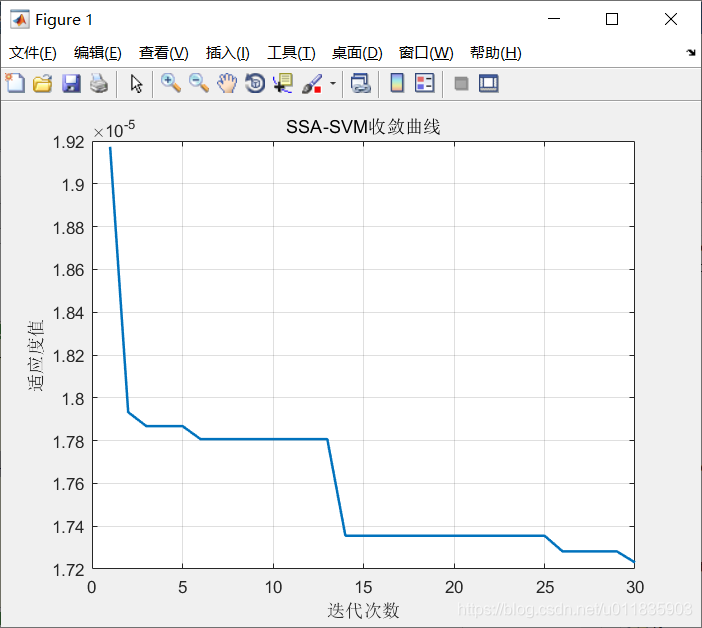
最终均方误差 MSE = 1.71874e-05 相关系数 R = 99.943% 。没优化前的结果:均方误差 MSE = 2.35705e-05 相关系数 R = 99.9195%(数据来源于《MATLAB神经网络43个案例分析》)
从结果上来看,改进后的SVM能够取得更好的结果。
6.参考文献
书籍《MATLAB神经网络43个案例分析》
7.matlab代码
[基于麻雀搜索算法优化的SVM回归预测]
[基于引力搜索算法优化的SVM数据回归预测]
[基于鲸鱼算法优化的SVM数据回归预测]
[基于郊狼算法优化的SVM回归预测]
[基于粒子群算法优化的SVM回归预测]
[基于遗传算法优化的SVM回归预测]
个人资料介绍















 5593
5593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











