







http://www.oschina.net/p/oryx
Oryx的目标是帮助Hadoop用户搭建并部署能够实时查询的机器学习模型,例如垃圾邮件过滤和推荐引擎。随着数据的不断流入,Oryx还将支持自我更新。
无论从建模还是部署,Oryx都可以随需扩展,Owen认为这是Oryx与Hadoop的传统“甜蜜点”——探索性分析和运营性分析最大的不同。
Owen认为传统的在Hadoop上部署机器学习的技术——Apache Mahout已经走到尽头。
“Mahout受制于第一代MapReduce只能处理批任务的局限,用户需要做大量的工作才能搭建并让机器学习系统运转起来,而Myrrix重写 了Mahout,解决了所有老问题。如果Mahout还有药可救,Cloudera就不会收购Myrrix。Oryx差不多有90%的代码都来自 Myrrix,也有一些代码来自Cloudera”Owen说道。
人人都能使用的开源推荐引擎?
Oryx的定位不是机器学习算法的程序库,Owen关注的重点有四个:回归、分类、集群和协作式过滤(也就是推荐)。其中推荐系统非常热门,Owen正在与几个Cloudera的客户合作,帮他们使用Oryx部署推荐系统。
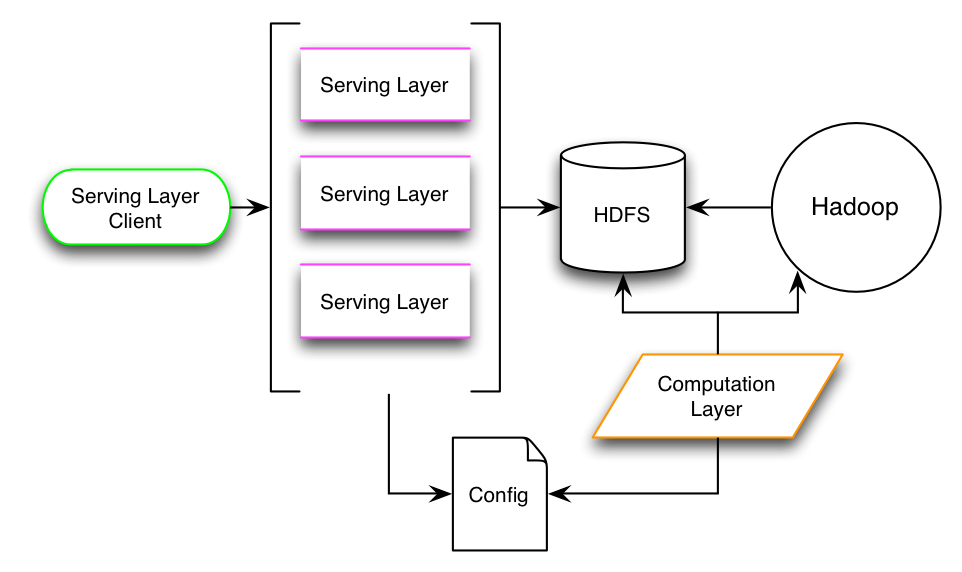
将Oryx打造成开发推荐系统的标准化工具的做法将使这个项目赢得极大关注,因为推荐系统几乎已经成了主流网站的标配,无论是电商还是内容网站都需要推荐系统提高网站的用户体验和转化率。但是推荐引擎技术目前面临的最大问题就是缺乏标准和开源工具。
致力于推荐技术标准化的公司不仅是Oryx一家,另外一家云计算创业公司Mortar Data也在积极推动用户推荐引擎技术的开发,并展现其开源推荐框架的优点。其他一些公司注入Expect Labs虽然没有开源,但试图通过人工智能API接口实现推荐系统的自动化。
目前还不是一个产品
Owen认为Cloudera的所有客户(以及绝大多数的Hadoop用户)最终都想要部署运营型机器分析系统——不仅仅是推荐,Oryx将来有可能成为实现工具,但目前Oryx还只是一个实验性项目。
目前Owen还在花费大量时间担当Apache Spark目的贡献者,他想重写Oryx,将Spark而不是MapReduce作为主要的处理框架,因为Spark已经成为下一代大数据应用的热门技术。由于性能 和速度优于MapReduce,且更加容易使用,Spark目前已经拥有一个庞大的用户和贡献者社区。这意味着Spark更加符合下一代低延迟、实时处 理、迭代计算的大数据应用的要求,包括基于Oryx开发的实时机器学习系统。















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









