









对一个二分类问题,实际取值只有正、负两例,而实际预测出来的结果也只会有0,1两种取值。如果一个实例是正类,且被预测为正类,就是真正类(True Positive),如果是负类,被预测为正类,为假正类(False Positive),如果是负类被预测成负类。称为真负类(True Negative),正类被预测为负类称为假负类(False Negative)。如图所示:
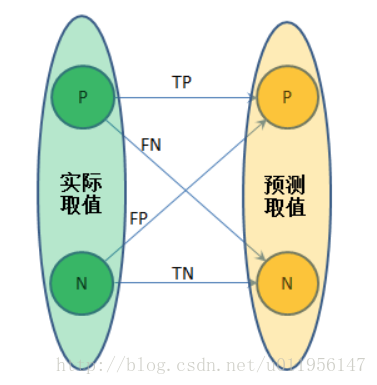
从列联表引入两个新名词。其一是真正类率(true positive rate ,TPR), 计算公式为TPR=TP / (TP + FN),刻画的是分类器所识别出的正实例占所有正实例的比例。另外一个是负正类率(false positive rate, FPR),计算公式为FPR= FP / (FP + TN),计算的是分类器错认为正类的负实例占所有负实例的比例。还有一个真负类率(True Negative Rate,TNR),也称为specificity,计算公式为TNR=TN / (FP + TN) = 1 − FPR。
False positive rate (α) = FP / (FP + TN) = 1 − specificity
False negative rate (β) = FN / (TP + FN) = 1 − sensitivity
Power = sensitivity = 1 − β
Likelihood ratio positive = sensitivity / (1 − specificity)
Likelihood ratio negative = (1 − sensitivity) / specificity
其他各种参数:
-
condition positive (P)
- the number of real positive cases in the data condition negatives (N)
- the number of real negative cases in the data
-
true positive (TP)
- eqv. with hit true negative (TN)
- eqv. with correct rejection false positive (FP)
- eqv. with false alarm, Type I error false negative (FN)
- eqv. with miss, Type II error
-
sensitivity,
recall,
hit rate, or
true positive rate (TPR)
 specificity or
true negative rate (TNR)
specificity or
true negative rate (TNR)
 precision or
positive predictive value (PPV)
precision or
positive predictive value (PPV)
 negative predictive value (NPV)
negative predictive value (NPV)
 miss rate or
false negative rate (FNR)
miss rate or
false negative rate (FNR)
 fall-out or
false positive rate (FPR)
fall-out or
false positive rate (FPR)
 false discovery rate (FDR)
false discovery rate (FDR)
 false omission rate (FOR)
false omission rate (FOR)
 accuracy (ACC)
accuracy (ACC)

-
F1 score
- is the harmonic mean of precision and sensitivity
 Matthews correlation coefficient (MCC)
Matthews correlation coefficient (MCC)
 Informedness or Bookmaker Informedness (BM)
Informedness or Bookmaker Informedness (BM)
 Markedness (MK)
Markedness (MK)

Sources: Fawcett (2006), Powers (2011), and Ting (2011) [6] [3] [7]
参考维基百科: https://en.wikipedia.org/wiki/Matthews_correlation_coefficient#cite_note-Powers2011-2














 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









