







微信翻译应用与研究
1. 微信翻译及典型应用场景
微信翻译典型应用场景–聊天、朋友圈:
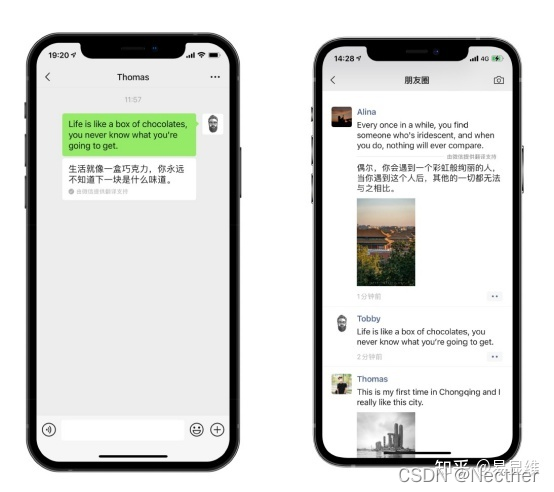
聊天、朋友圈、朋友圈评论
l 文本长按翻译
l 图片长按翻译
目标语言默认为系统设置语言
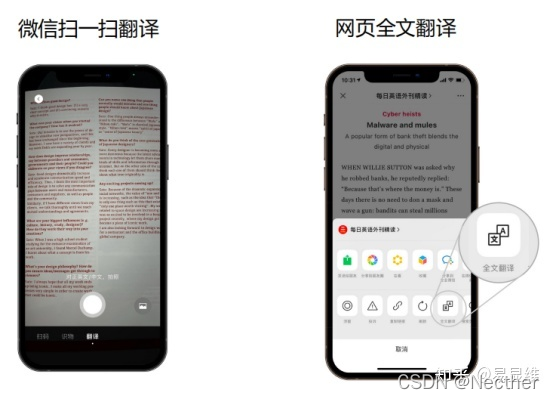
微信翻译典型应用场景–扫一扫、网页:
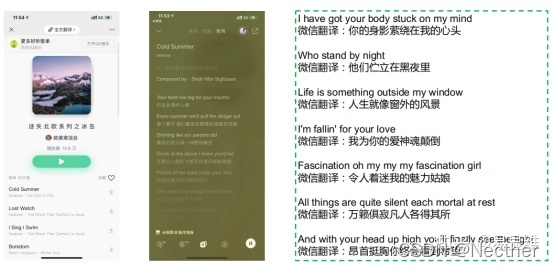
微信翻译典型应用场景–QQ音乐歌词:
2. 机器翻译与微信翻译模型
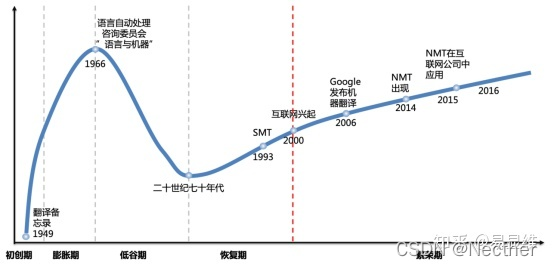
机器翻译发展历史:规则 --> 统计 --> 神经网络
神经机器翻译: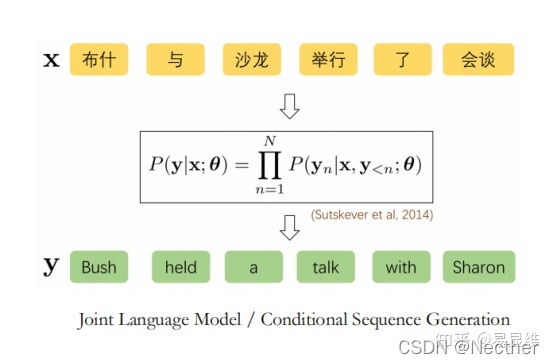
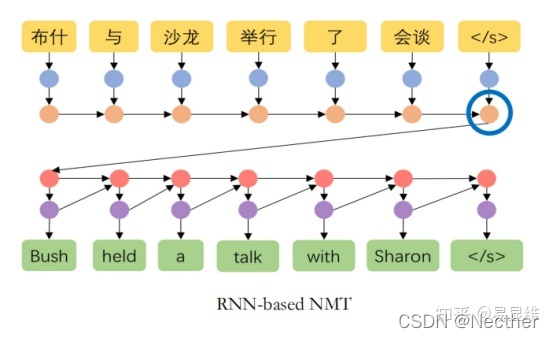
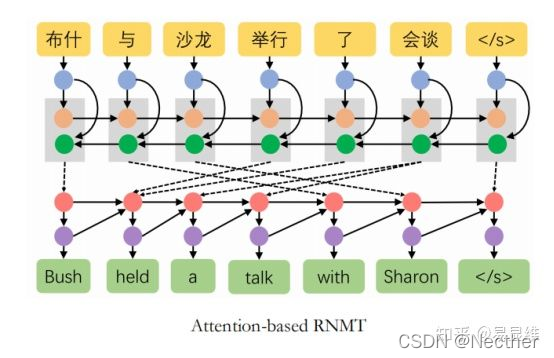
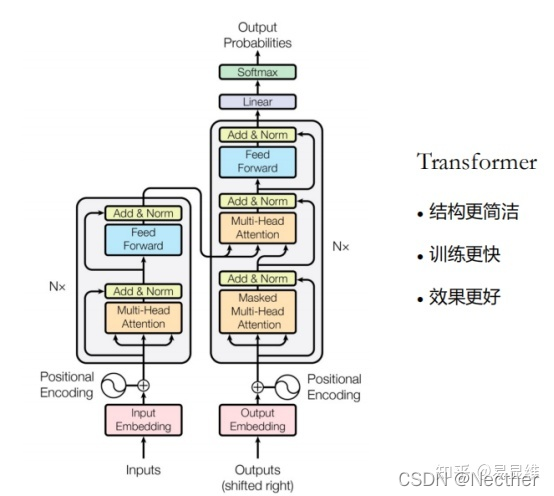
业务特点:
l 多语言、多领域、语言混杂Query、表达不规范Query
n 这几天天阴雨天
n 不是一个level总想和我battle
n 今天喝快乐肥宅水了吗?
n You are so cxk
模型特点:
l 深层&多路Encoder
l 多语言、生成+拷贝
l 通用的模型训练优化技术
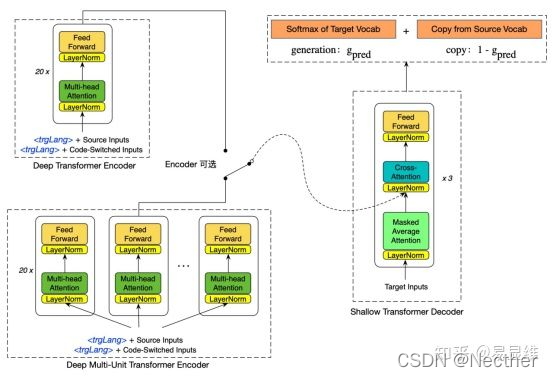
3. 翻译模型训练优化 (ACL 2021)
3.1词级别的自适应学习
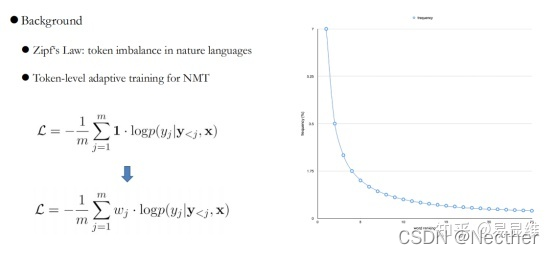
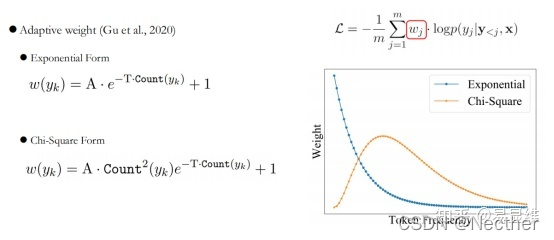
双语背景、测量学习困难
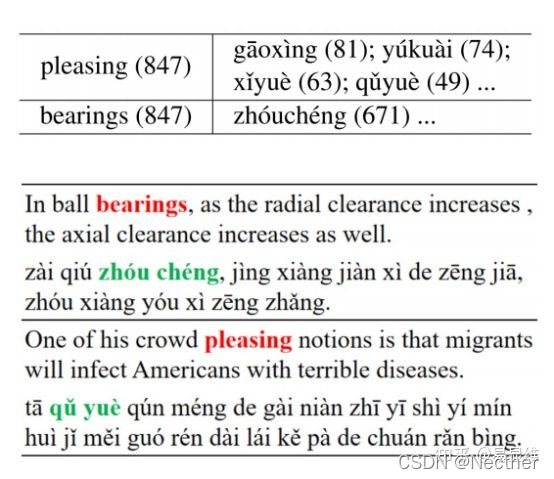
双语互信息:
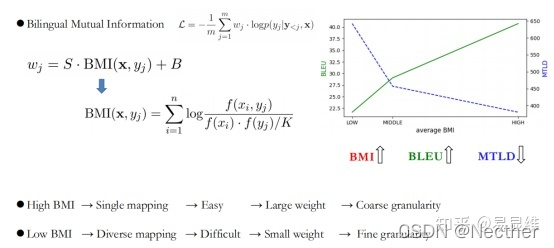
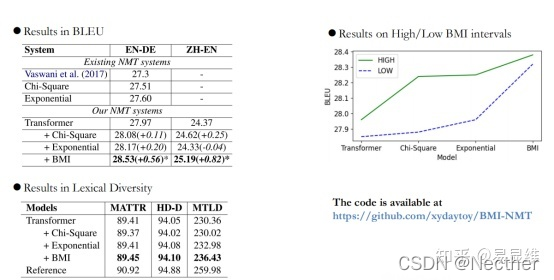
3.2 防止潜在的语言模型过自信



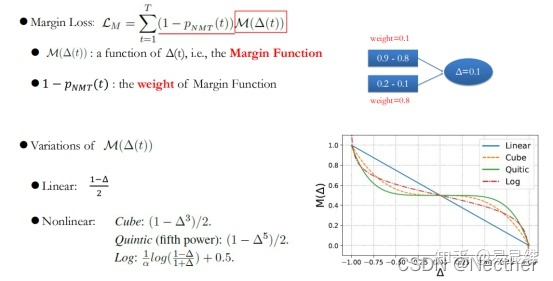


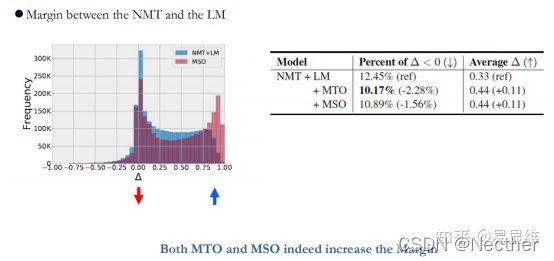

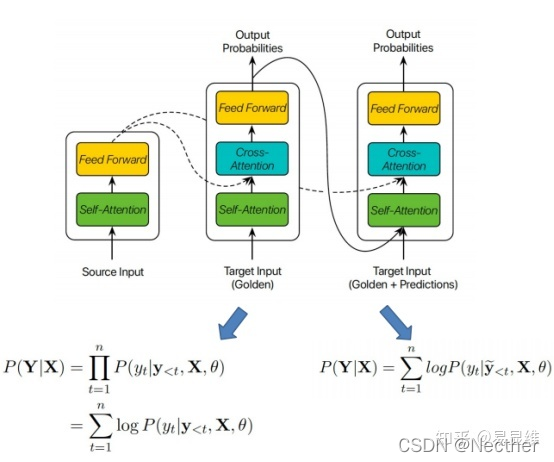
3.3 基于模型置信度的调度采样
计划抽样:
l 减轻NMT的暴露偏差
l 模拟训练期间的推理场景
n 随机用预测的目标输入令牌替换地面真实的目标输入令牌
衰减策略:
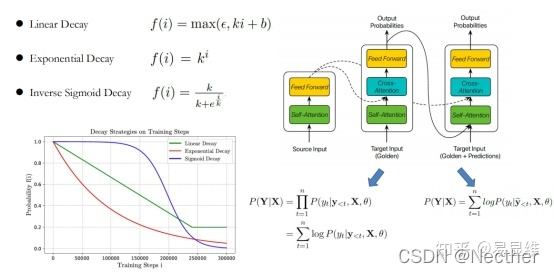
存在的问题:
l 忽略实时模型的能力
l 限制其潜在的性能和收敛速度
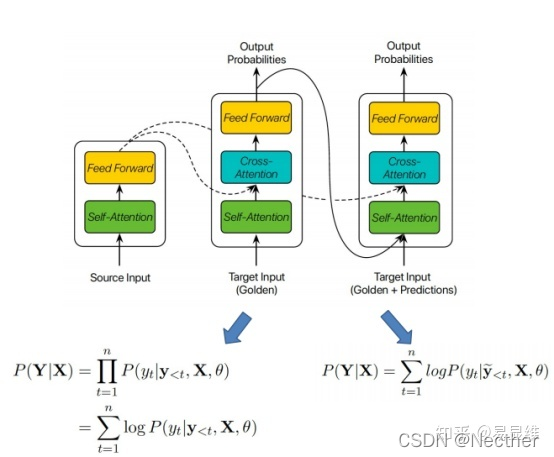
模型置信度估计:

置信度计划抽样: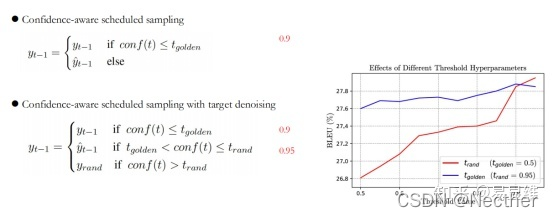
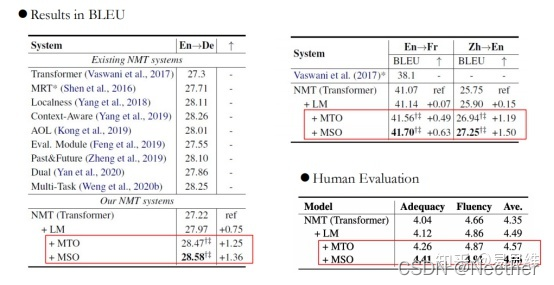
实验与分析:
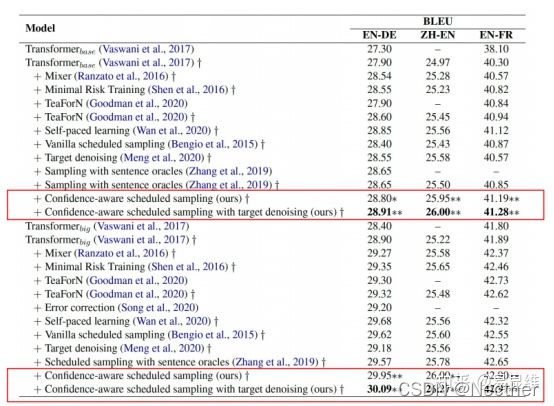
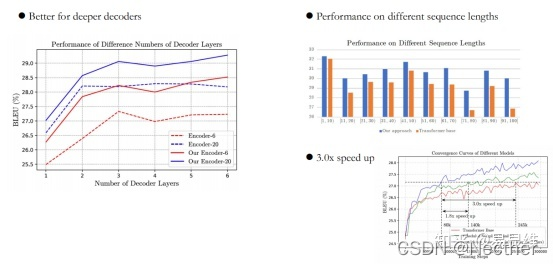
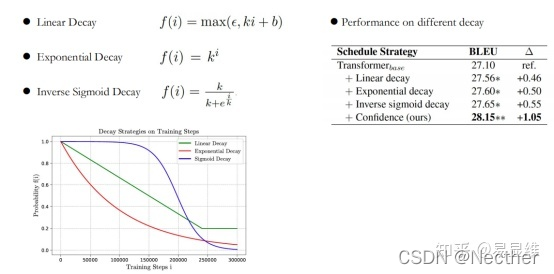
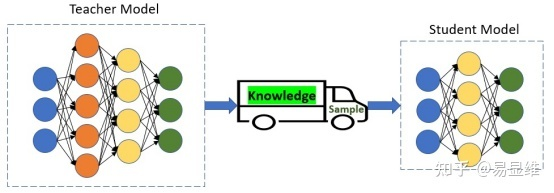
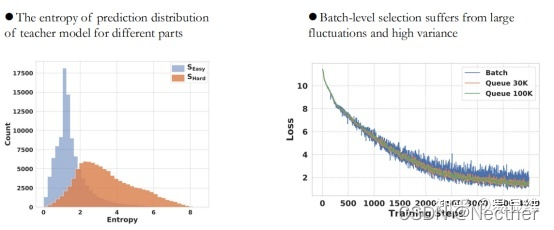
3.4 选择性的知识蒸馏
针对NMT的选择性知识蒸馏:
训练样本:蒸馏知识的介质和载体
存在问题:
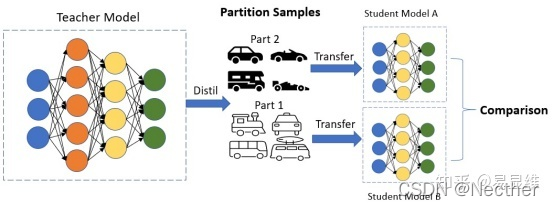
训练样本的贡献相同吗?
训练样本之间的联系是什么?
所有的单词都同样适合KD吗?
l 对每个样本的消融研究是耗时和棘手的
l 将样品分成两部分,并分析它们之间的差异
n 数据属性:句子长度,Word频率
n 学生模型:WordCE,句子CE,Word的嵌入规范
n 教师模式:教师P_golden、预测分布的熵
一些发现: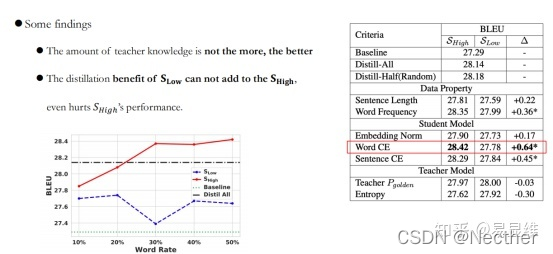

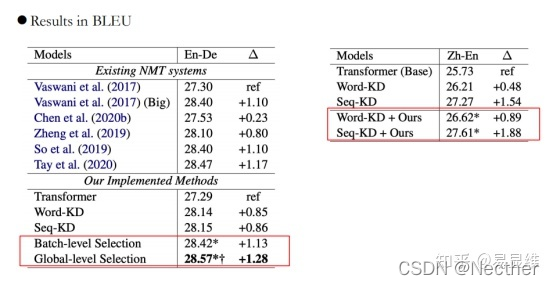
实验与分析:
3.5对话翻译/多语言对话
聊天翻译的双语对话特征建模:
聊天翻译——使多个说话者能够使用其母语相互交流。
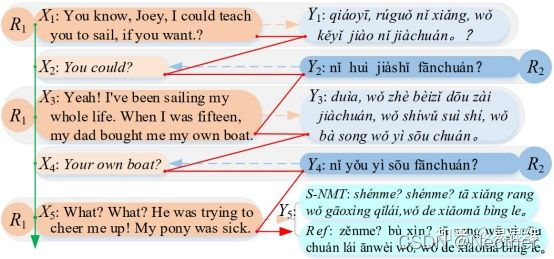
双语对话:
l 角色偏好
l 对话一致性
l 翻译一致性
挑战:
l 现有的具有上下文感知功能的NMT模型还不够
l 设计模型来捕捉这些固有的特征
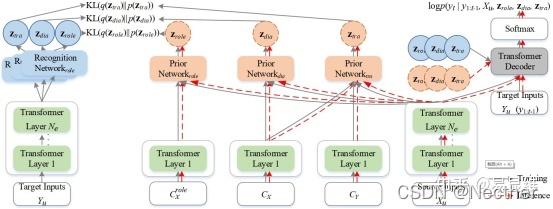
模型架构:
包含了角色偏好、对话一致性和翻译一致性的三个潜在变分模型
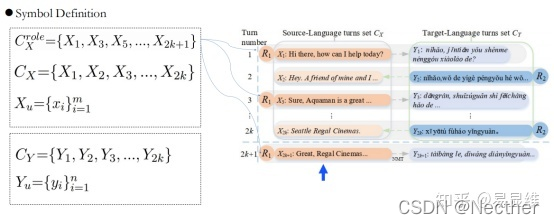
体系结构:符号定义和输入表示法
后期变分模型:

在解码器中注入潜在变量:
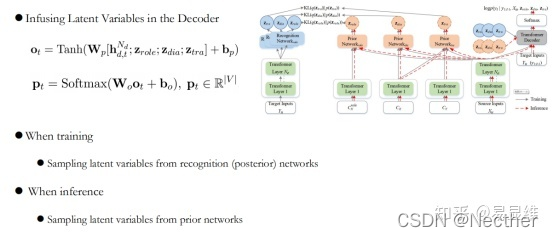
训练目的:
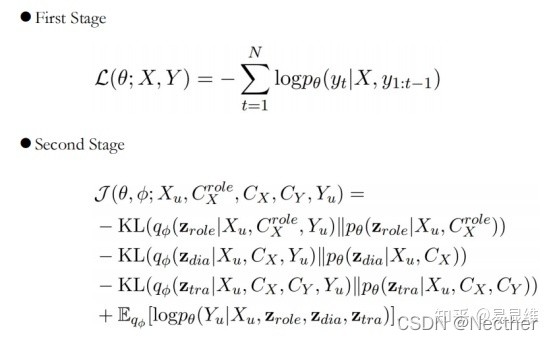
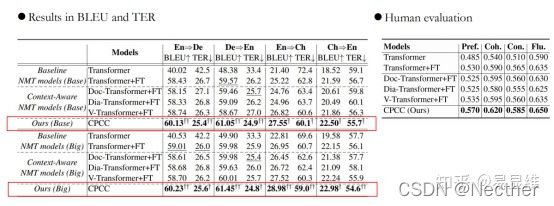
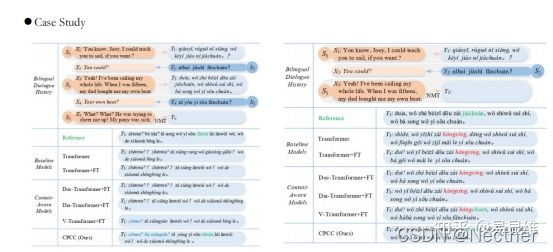
实验与分析:














 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









