






目前对向量topk相似度计算算法有许多,如下图:
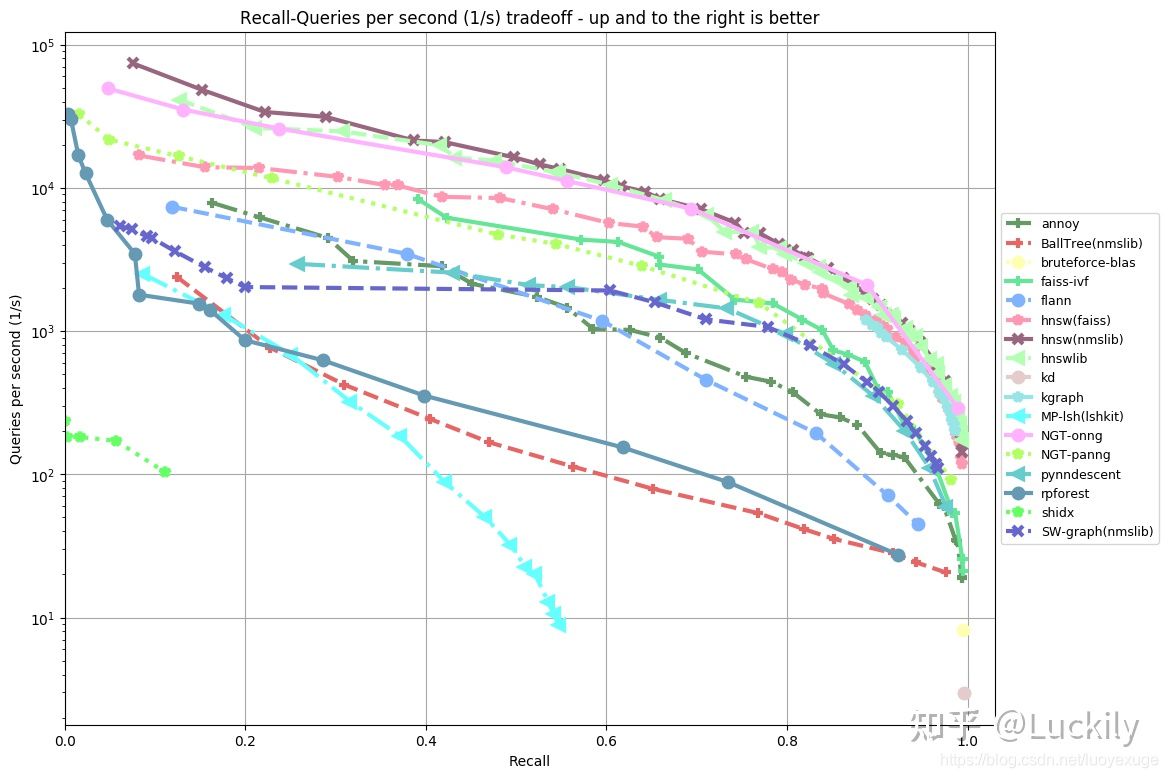
关于向量取topk相似度的应用场景很多,比如推荐系统里面使用item2vec经常离线计算好topk的相似度,搜索领域里面的query2vec使用topk相似度,word2vec领域里面的topk相似度,本文选取了几个经典的算法做性能比较,kd-tree、kd-ball、faiss、线性搜索、annoy几个算法,环境都是mac本地cpu环境,向量是选了一点游戏语料训练的一个word2vec模型,在做之前需要把annoy存储为了一个模型,另外做向量召回时候需要对向量进行L2标准化,使得算余弦相似度和欧式距离是一个东西,便于比较,下面看看代码:
import time, random
import numpy as np
from sklearn.neighbors import KDTree
from sklearn.neighbors import BallTree
from sklearn import preprocessing
from annoy import AnnoyIndex
import faiss
import gensim
import warnings
warnings.filterwarnings("ignore")
path = "/Users/zhoumeixu/Documents/python/word2vec/bin/vectors.bin"
model = gensim.models.KeyedVectors.load_word2vec_format(path, binary=True,unicode_errors='ignore')
model.init_sims(replace=True) #l2-normalized <=> euclidean : (a-b)^2 = a^2 + b^2 - 2ab = 2-2ab <==>2-2*cos
words=["王者"]*1000
class ANNSearch:
word2idx = {}
idx2word = {}
data = []
def __init__(self, model):
for counter, key in enumerate(model.vocab.keys()):
self.data.append(model[key])
self.word2idx[key] = counter
self.idx2word[counter] = key
# leaf_size is a hyperparameter
#这里加L2正则化,使得余弦相似度就是跟欧式距离等价
#self.data=preprocessing.normalize(np.array(self.data), norm='l2')
self.data = np.array(self.data)
# ball树
self.balltree=BallTree(self.data, leaf_size=100)
#kd树
self.kdtree = KDTree(self.data, leaf_size=100)
# self.faiss_index = faiss.IndexFlatIP(200)
# self.faiss_index.train(self.data)
# self.faiss_index.add(self.data)
self.quantizer = faiss.IndexFlatIP(200) # the other index,需要以其他index作为基础
self.faiss_index = faiss.IndexIVFFlat(self.quantizer, 200, 120, faiss.METRIC_L2)
self.faiss_index.train(self.data)
self.faiss_index.nprobe = 80
self.faiss_index.add(self.data) # add may be a bit slower as well
#排除掉自身,从1开始
def search_by_vector_kd(self, v, k=10):
dists, inds = self.kdtree.query([v], k)
return zip([self.idx2word[idx] for idx in inds[0][1:]], dists[0][1:])
# 排除掉自身,从1开始
def search_by_vector_ball(self, v, k=10):
dists, inds = self.balltree.query([v], k)
return zip([self.idx2word[idx] for idx in inds[0][1:]], dists[0][1:])
def search(self, query, k=10,type="kd"):
vector = self.data[self.word2idx[query]]
if type=="kd":
return self.search_by_vector_kd(vector, k)
else:
return self.search_by_vector_ball(vector,k)
def search_by_fais(self,query,k=10):
vector = self.data[self.word2idx[query]]
dists, inds=self.faiss_index.search(vector.reshape(-1,200),k)
return zip([self.idx2word[idx] for idx in inds[0][1:]], dists[0][1:])
def search_by_annoy(self,query,annoymodel,k=10):
index=self.word2idx[query]
result= annoymodel.get_nns_by_item(index, k)
word_result=[self.idx2word[idx] for idx in result[1:]]
return word_result
def time_test():
# Linear Search
start = time.time()
for word in words:
model.most_similar(word, topn=10)
stop = time.time()
print("time/query by (gensim's) Linear Search = %.2f s" % (float(stop - start)))
search_model = ANNSearch(model)
#faiss搜索
start = time.time()
for word in words:
search_model.search_by_fais(word, k=10)
stop = time.time()
print("time/query by faiss Search = %.2f s" % (float(stop - start)))
# KDTree Search
start = time.time()
for word in words:
search_model.search(word, k=10)
stop = time.time()
print("time/query by kdTree Search = %.2f s" % (float(stop - start)))
## ballTree Search
start = time.time()
for word in words:
search_model.search(word, k=10, type="ball")
stop = time.time()
print("time/query by BallTree Search = %.2f s" % (float(stop - start)))
###annoy serarch
annoy_model = AnnoyIndex(200)
annoy_model.load('/Users/zhoumeixu/Documents/python/word2vec/bin/annoy.model')
start=time.time()
for word in words:
search_model.search_by_annoy(word,annoy_model,k=10)
stop=time.time()
print("time/query by annoy Search = %.2f s" % (float(stop - start)))
def result_test():
print("gensim:",model.most_similar("王者", topn=5))
search_model = ANNSearch(model)
print("kd tree:",list(search_model.search("王者", k=6)))
print("ball tree:",list(search_model.search("王者", k=6,type="ball")))
print("faiss:",list(search_model.search_by_fais("王者",k=6)))
annoy_model = AnnoyIndex(200)
annoy_model.load('/Users/zhoumeixu/Documents/python/word2vec/bin/annoy.model')
print("annoy:",list(search_model.search_by_annoy("王者",annoy_model,k=6)))
if __name__=="__main__":
#time_test()
result_test()
准确性:
gensim: [('荣耀', 0.9508273005485535), ('李白', 0.5334799289703369), ('韩信', 0.46967631578445435), ('李元芳', 0.46955445408821106), ('诸葛亮', 0.45386096835136414)]
kd tree: [('荣耀', 0.3136006177182185), ('李白', 0.9659400491036177), ('韩信', 1.029877357244912), ('李元芳', 1.0299956733648787), ('诸葛亮', 1.0451210619937399)]
ball tree: [('荣耀', 0.3136006177182185), ('李白', 0.9659400491036177), ('韩信', 1.029877357244912), ('李元芳', 1.0299956733648787), ('诸葛亮', 1.0451210619937399)]
faiss: [('荣耀', 0.09834535), ('李白', 0.9330402), ('韩信', 1.0606475), ('李元芳', 1.060891), ('诸葛亮', 1.092278)]
annoy: ['荣耀', '李白', '韩信', '李元芳', '诸葛亮']
算法性能耗时:
time/query by (gensim's) Linear Search = 0.72 s
time/query by faiss Search = 1.09 s
time/query by kdTree Search = 6.80 s
time/query by BallTree Search = 6.42 s
time/query by annoy Search = 0.03 s
在这里可以看到annoy最快,kddtree最慢,当然在gpu环境下面可能是faiss最快的
转载于


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









