






导读
本文提出了一种适用于细长物体检测的自适应标签分配方案。具体来说,提出了中心轴先验用于正训练样本,使正训练样本的最终位置分布更加合理。其次,建议进一步增加细长物体的正训练样本数量,以解决细长物体与常规物体之间正训练样本不平衡的问题。

摘要
细长物体具有较大的纵横比并且通常是定向的,这导致当前通用检测器在细长物体检测任务上的性能较差。因此,本文提出了一种适用于细长物体检测的自适应标签分配方案。具体来说,提出了中心轴先验用于正训练样本,使正训练样本的最终位置分布更加合理。其次,建议进一步增加细长物体的正训练样本数量,以解决细长物体与常规物体之间正训练样本不平衡的问题。在MS COCO数据集上的实验结果证明了所提出方法的有效性。
1 介绍
物体检测旨在识别并定位图像中的感兴趣物体,这是计算机视觉中的一个基本但富有挑战性的问题。近年来,基于深度神经网络的物体检测算法迅速发展,并在通用物体检测领域取得了巨大成功。然而,在工业应用中存在许多特殊场景,例如小物体、密集物体和细长物体。对于小物体检测和密集物体检测,已经提出了许多优秀的工作,但就我们所知,关于细长物体检测的研究很少。
在物体检测中,通常使用水平边界框来表示物体的位置。然而,这种表示方法存在以下问题:首先,当物体具有方向性或形状不规则时,可能会导致框内包含冗余背景或其他物体的部分,如图1(a)所示。其次,当多个方向性物体密集出现时,使用水平边界框会导致较大的重叠率,如图1(b)所示。细长物体具有较大的纵横比,因此我们认为上述问题对细长物体的检测性能有很大影响。

为了解决上述问题,最先进的检测器主要从标签分配的角度提出改进方案。OTA将标签分配问题视为最优传输问题,计算所有真实框(gts)与预测框之间的传输成本,并通过找到最优映射来获得最低的传输成本。与其他方法相比,OTA考虑了所有gts的全局信息,可以找到全局最优的标签分配方案。SimOTA简化了OTA中使用的Sinkhorn-Knopp迭代解法,将其变为动态k估计策略,能够在不牺牲性能的情况下减少25%的训练时间。所有这些标签分配方法都采用中心先验策略,即限制正样本距离物体中心一定距离r内。然而,我们期望细长物体的正样本沿其中心轴分布,因此中心先验策略不适用于细长物体。
此外,我们发现数据集中细长物体的比例通常较小,且细长物体的位置回归精度低于常规物体,因此动态k估计算法估计的正训练样本数量少于常规物体。这导致细长物体与常规物体之间正样本数量的不平衡,从而进一步降低了细长物体的检测性能。
针对上述问题,我们提出了一种自适应标签分配方案以提升细长物体的检测性能。首先,将预测框替换为旋转框以减少冗余背景和重叠。然后,提出自适应中心轴先验策略,使最终选定的正训练样本的位置分布更加合理。最后,为了缓解细长物体与常规物体之间正样本数量的不平衡问题,我们建议增加细长物体的正样本数量以进一步提升其性能。
2 方法
2.1 细长物体的定义

为了便于评估和分析,需要确定物体的细长度测量方法。在物体检测中,通常使用水平边界框,可以通过水平边界框的宽度w 和高度h近似计算细长度为 。然而,这一定义不适用于方向性细长物体。如图2所示, slenderness 无法真正反映滑板的细长特征。更精确的方法是使用覆盖物体最小面积的旋转边界框。这样,细长度可以定义为:

其中 h 和 w 分别是最小面积矩形边界框的高度和宽度。
为了便于比较,我们将细长度 slenderness 小于1/5的物体称为极细长XS,细长度 slenderness 在1/5 到 1/3 之间的物体称为细长S,细长度 slenderness 大于 1/3的物体称为常规R。
2.2 旋转目标检测头
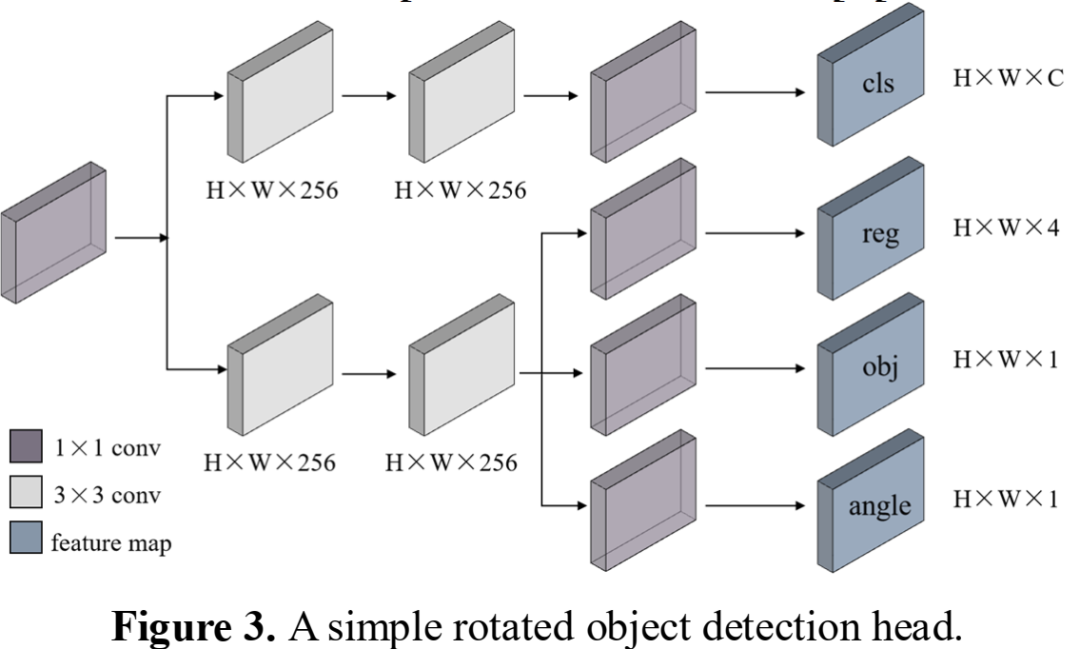
当前通用的目标检测器只能预测水平边界框。为了精确预测目标的最小面积边界框,目标检测器需要能够预测目标的旋转角度。最直观和简单的方法之一是在检测头中添加一个角度回归分支,从而使改进后的检测器具有边界框的角度预测能力。以YOLOX的解耦检测头为例,添加角度回归分支的方式如图3所示。定义旋转框的角度 θ 有三种常见方法。在本文中,我们采用OpenCV的定义,其中 θ∈[0,π/2]。
2.3. 动态标签分配
SimOTA 简介。为了减少不规则形状和高遮挡对性能的影响,近期的目标检测器主要设计了更先进的动态标签分配算法。目前广泛使用的标签分配方法是 SimOTA,它是 OTA 的改进版本。
SimOTA 主要包含以下几个步骤。首先,需要确定正样本的候选区域,取目标中心点周围 3×3 方框范围内的锚点作为候选正样本。然后,计算所有锚点与真实值gts 之间的成本或匹配度,成本是分类损失和回归损失的加权和,如公式 (2) 所示,这也被称为损失感知。最后,使用动态 k 估计算法来预测每个真实值需要分配的正样本数量,并将成本值最小的前 k 个锚点分配为每个真实值的正样本。
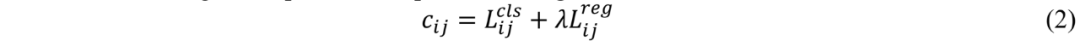
中心轴先验。为了使训练过程稳定并提高收敛速度,YOLOX 等无锚框目标检测器需要确定正样本的候选区域,然后从先验区域内动态地确定正样本。通常认为靠近物体中心的锚点可以更好地表征物体,因此一般使用距离物体中心一定范围内方形区域作为候选区域,这被称为中心先验,如图 4 中的水平边界框所示。然而,这种方法并不适用于细长物体,我们认为位于物体中心轴附近的锚点所学习到的特征具有更丰富的语义信息,能够更好地表征物体,有利于后续的分类和定位。因此,本文提出了中心轴先验,主要将正样本的候选区域扩展到沿物体长轴方向的旋转矩形,如图 4 中的定向边界框所示。不同物体的先验区域大小如公式 (3) 所示自适应地确定。
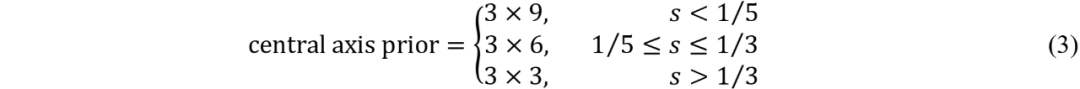

增加细长物体的正样本数量。SimOTA 中提出了动态 k 估计方法,用于自适应地为每个gt估计合适的正样本数量。具体来说,计算所有预测框与gt之间的 IoU(交并比),然后对每个gt积累前 q 大的 IoU 值,并将四舍五入的结果作为正样本的数量。我们观察到,由于细长物体的位置预测相对不准确,其预测框与地面实况之间的 IoU 通常较小,导致细长物体的正样本数量显著少于常规物体。此外,细长物体在训练数据集中所占比例较小。这两个因素导致了细长物体检测中正样本数量的不平衡,使得模型偏向于常规物体。因此,本文改进了动态 k 估计算法,通过增加细长物体的正样本数量(如公式 (4) 所示),缓解了正样本数量的不平衡,使细长物体的训练更加充分。
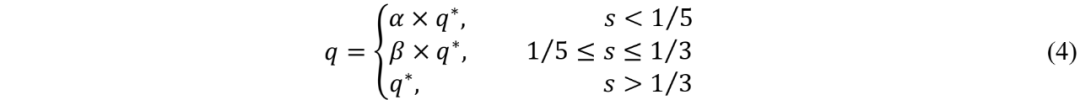
3 结果和讨论

实验在包含约 118,000 张训练集图像和 20,000 张测试集图像的 MS COCO 2017 数据集上进行。遵循常见做法,我们在训练集上训练检测器并在测试集上比较性能。使用经过 ImageNet 预训练的修改版 CSPNet 作为 YOLOX-M 模型的基本框架。我们使用权重衰减为 5e-4 和动量为 0.9 的随机梯度下降(SGD)作为优化器。采用余弦学习率调度,基础学习率为 0.01,总迭代次数为 300 轮。在训练过程中,我们采用了多尺度策略,输入尺寸从 416 到 768,步长为 32,而在测试时输入尺寸为 640x640。公式 (4) 中使用的 分别为 1.5、1.2 和 10。除了常用的目标检测指标 AP 外,我们还报告了针对额外细长、细长和常规物体的 APXS、APS 和 APR,这些类似于常用的 APS、APM 和 APL。
如表 1 所示,YOLOX-M 基线模型实现了 47.2% 的 AP。然而,APXS 和 APS 分别仅为 22.9% 和 36.5%,远低于 52.8% 的 APR,因此我们得出结论,细长物体的检测性能低于常规物体。将表示方式从边界框改为旋转边界框可以减少冗余背景和重叠,因此我们可以看到额外细长物体和细长物体的性能分别提高到 23.4% 和 36.9%,而常规物体的性能也从 52.8% 提高到 53.0%。应用中心轴先验后,细长物体的性能有所提升,APXS 和 APS 分别增加了 2.8% 和 1.7%。常规物体的性能保持不变,AP 从 47.4% 提高到 47.6%。当我们继续增加细长物体的正样本数量时,APXS 从 26.2% 提高到 27.3%,APS 从 38.6% 提高到 39.1%。受此影响,APR 略微下降了 0.1%,AP 保持不变。当同时使用上述三种策略时,APXS、APS 和 APR 分别提高了 4.4%、2.6% 和 0.1%,AP 总体提高了 0.4%。
我们在图 5 中可视化了一些标签分配结果,并且为了更好地展示,仅显示了正训练样本数量最多的 FPN 层。在预测水平边界框并采用中心先验的情况下,细长物体的正样本被分配到了物体中心附近的区域,有时它们会落入背景或重叠区域。采用旋转边界框和中心轴先验后,正样本可以沿着物体的中心轴分布,并且几乎没有样本落入重叠区域,因此位置分布更加合理。改进动态 k-估计算法之后,可以为细长物体分配更多的正训练样本。

4. 结论
在本研究中,我们提出了一种适用于细长物体检测的自适应标签分配策略。我们指出,水平边界框并不适合细长物体。采用旋转边界框可以更好地对齐细长物体,从而实现更准确的识别。接着,我们建议将正训练样本的候选区域从通常使用的中心改为中心轴,这有助于网络训练时选择更适合的正样本。此外,我们发现相比于常规物体,细长物体在数据集中的比例较低且定位精度较低,导致正样本不平衡的问题。因此,我们建议通过改进动态 k 估计算法来进一步增加细长物体的正样本数量。在 MS COCO 数据集上进行的实验验证了所提出方法的有效性。

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









