






导读
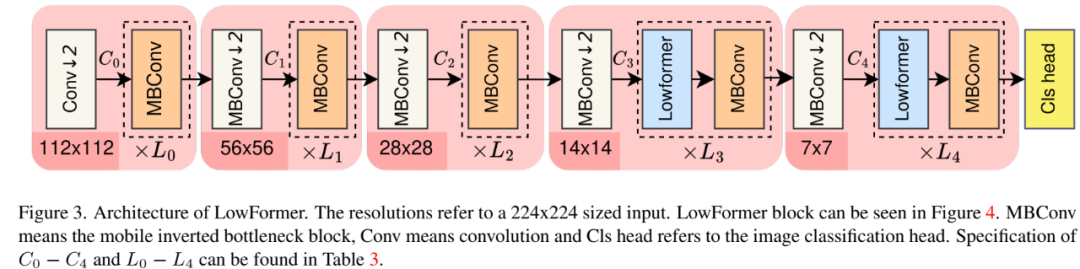
我们将宏观设计与微观设计相结合,创建了一种新的硬件高效骨干网络家族,称为LowFormer。LowFormer在吞吐量和延迟方面实现了显著的速度提升,同时达到了与当前最先进的高效骨干网络相似或更好的精度。
摘要
高效视觉骨干网络的研究正在演进为卷积与Transformer模块的混合模型。从架构和组件层面智能地结合这两种方法对于在速度与精度之间取得平衡至关重要。大多数研究集中在最大化精度,并使用MACs(乘积累加操作)作为效率指标。然而,由于内存访问成本和平行度等因素,MACs并不能准确反映模型的实际运行速度。我们分析了骨干网络中的常见模块和架构设计选择,不是基于MACs,而是基于实际吞吐量和延迟,因为这两者的结合更能代表模型在实际应用中的效率。我们将分析得出的结论应用于创建提高硬件效率的设计方案。此外,我们引入了一个简化版的多头自注意力(MultiHead Self-Attention)模块,该模块与我们的分析结果一致。我们将宏观设计与微观设计相结合,创建了一种新的硬件高效骨干网络家族,称为LowFormer。LowFormer在吞吐量和延迟方面实现了显著的速度提升,同时达到了与当前最先进的高效骨干网络相似或更好的精度。为了证明我们的硬件高效设计的通用性,我们在GPU、移动GPU和ARM CPU上评估了我们的方法。我们进一步展示了下游任务——目标检测和语义分割从我们的硬件高效架构中受益。代码和模型可在以下网址获取:https://github.com/altair199797/LowFormer。
1 介绍
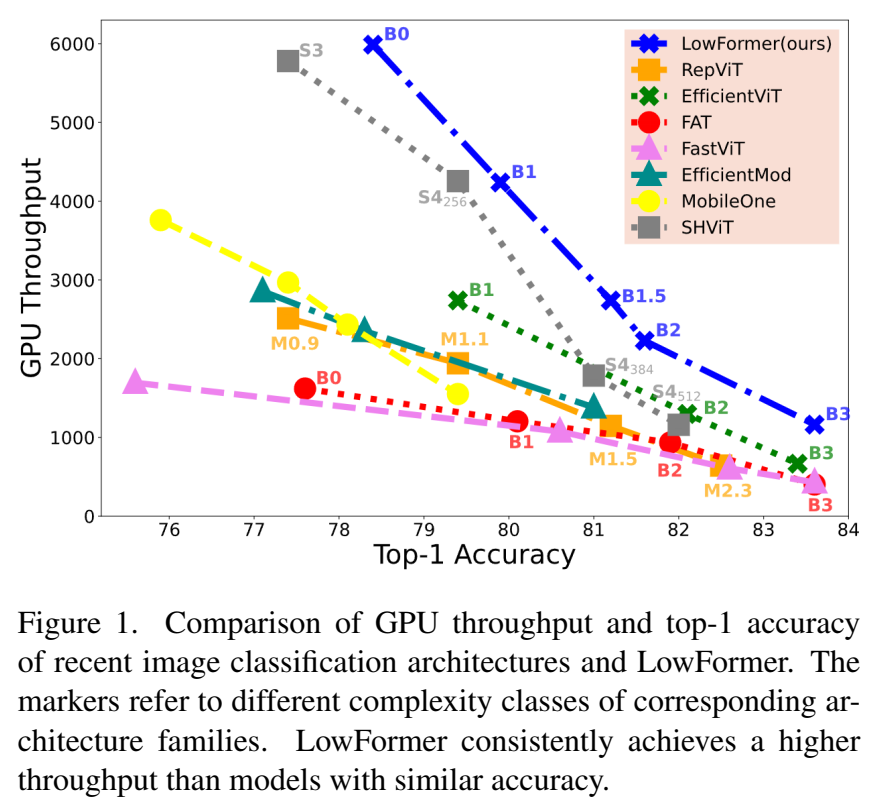
最近关于高效视觉骨干网络的研究集中于将注意力机制与卷积层结合。局部信息提取(通过卷积)与全局推理(通过注意力)的混合已被证明优于单一类型的模型。研究的主要目标是在速度与精度之间找到最佳平衡点,从而提高如目标检测、姿态估计和语义分割等下游任务的效率。在移动和边缘设备上提高这些任务的应用性也要求骨干架构具备更高的效率。
为了衡量深度学习模型的计算效率并进行比较,通常会统计乘积累加操作(MACs)的数量。模型的MAC数量与其精度密切相关。例如,通过宽度、深度或分辨率扩展来增加MAC数量可以提高精度。然而,MAC并非同等重要,它们忽略了内存访问成本和平行度等因素,这些因素对模型执行时间有重大影响。
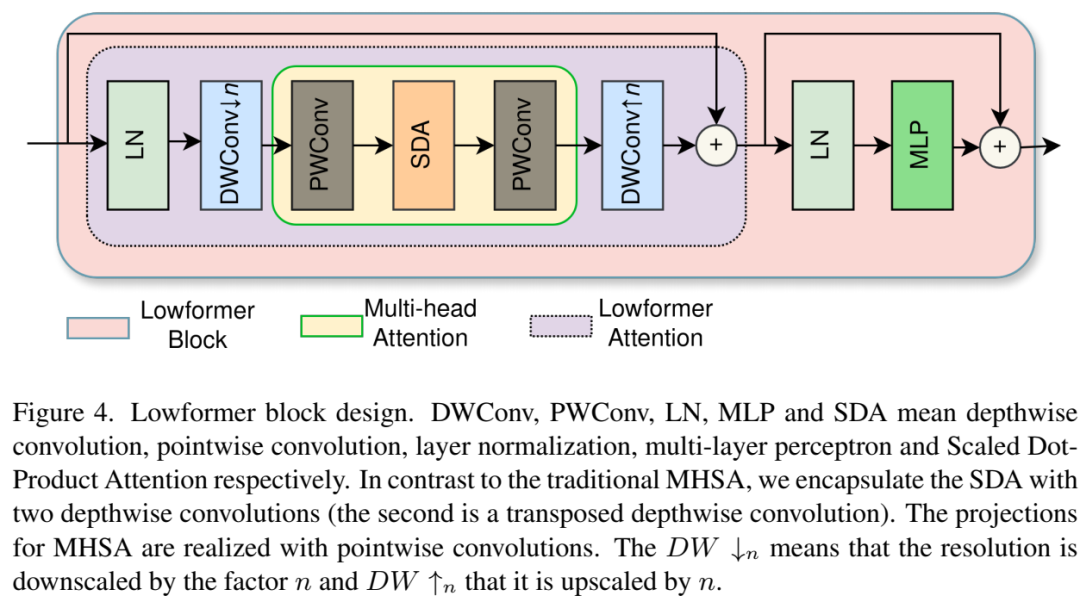
我们的目标是在提高精度的同时,通过研究MAC执行的最佳时机来改进高效骨干架构的吞吐量和延迟。基于此发现,我们总结出一套高效的架构设计方案。在第3节中,我们进行了多项实验,对比了宏观设计决策的执行时间和MAC数量。利用高效的MAC执行所带来的优势,我们设计了一种新的骨干网络家族,称为LowFormer。得益于其宏观设计,LowFormer比之前提出的模型更快且更精确(见图1)。根据我们的研究结果,我们在传统注意力机制的基础上进行了简化,通过下采样和上采样围绕缩放点积注意力(SDA)的操作,使得SDA在更低分辨率的输入上运行,因此命名为LowFormer。
我们通过测量GPU吞吐量、GPU延迟、移动GPU延迟以及ARM CPU延迟来验证LowFormer硬件效率的通用性。我们通过广泛的消融研究来支持我们的设计决策。所提出的架构具有简单的微观和宏观设计,允许我们从低复杂度(LowFormer-B0)到高复杂度(LowFormer-B3)进行扩展。总共包括五个模型(B0、B1、B1.5、B2、B3),在ImageNet-1K上的Top-1精度范围从78.4%到83.64%。例如,与MobileOne-S2相比,LowFormer-B0在GPU上的吞吐量是其两倍,延迟减少了15%,同时Top-1精度提高了1%。而最高复杂度的模型LowFormer-B3几乎拥有FAT-B3三倍的GPU吞吐量,且只有其55%的GPU延迟。
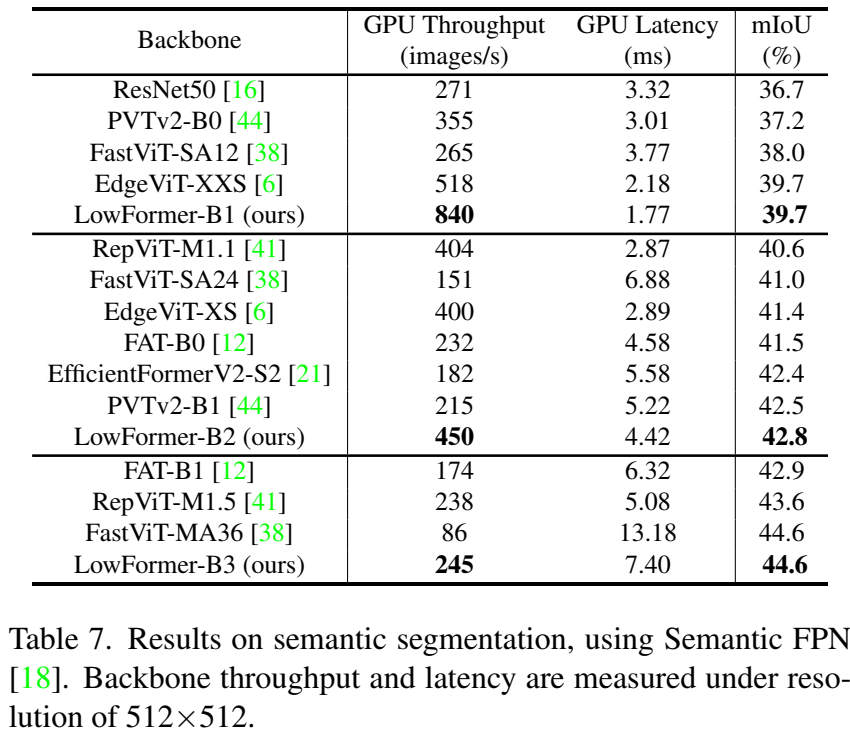
此外,我们将LowFormer集成到Semantic FPN和RetinaNet中,以改善语义分割和目标检测模型的效果。例如,在第一个框架中,我们的LowFormer-B1骨干网络在mIoU上比FastViT-SA12高出1.7%,同时在GPU上的吞吐量是其三倍,延迟减少了30%。
总结来说,我们的贡献如下:
我们提出了一种具有硬件高效宏观设计及轻量级注意力机制的新骨干架构家族。与具有类似精度的模型相比,我们的模型在吞吐量和延迟方面表现更佳。
我们在多种计算设备上对不同配置下的卷积进行了详尽的速度分析,对比了MAC操作数量与实际执行时间的关系。我们展示了LowFormer不仅在语义分割和目标检测任务中表现出良好的泛化能力,而且在移动GPU和ARM CPU等多种硬件上保持其速度优势。
2 相关工作
高效硬件模型设计
追求最高精度而不计计算成本的做法早已不再是深度学习领域唯一的目标。越来越多的研究致力于创建最高效的架构,并在此基础上实现最佳的速度与精度权衡。早期的方法主要将速度等同于最小的MAC数量,而近期的研究则更多地通过桌面GPU和CPU上的吞吐量或延迟来评估模型性能,同时也关注移动GPU或一般边缘设备的表现。
内存访问成本和平行度已成为高效模型设计的重要因素。例如,EfficientViT指出,Transformer块中的多头自注意力(MHSA)比前馈网络(FFN)引入了更高的内存访问成本。因此,他们在架构中增加了FFN的比例,同时尽量减少了精度损失。另一方面,MobileOne的作者分析了激活函数和多分支架构对移动端延迟的影响。ShuffleNetV2和FasterNet都指出,由于高内存访问成本,当前硬件上分组卷积的执行效率较低。我们遵循了他们的见解,但没有采用部分取消分组卷积的做法,也没有引入新的微架构设计,而是研究了深度可分离卷积和逐点卷积融合如何影响执行时间。此外,我们还分析了分辨率对硬件效率的影响,并将这两项研究的结果应用于我们的宏观设计中。
高效注意力机制
目前存在多种试图替代传统注意力操作的不同类型注意力机制。许多方法通过线性注意力变体去除了其二次特性,这些变体基于Wang等人提出的方法。然而,Yu等人表明,注意力本身并没有我们想象的那么重要,甚至可以用简单的池化操作代替。Li等人进一步发展了这一想法,在前三个阶段使用高效的池化操作,而在最后两个阶段使用传统注意力。其他方法则在注意力操作之前对键(K)和值(V)进行下采样,使用卷积或池化。Si等人则对查询(Q)也进行了下采样,因此完全在较低分辨率上运行。这与我们的注意力方法相似,但我们使用卷积而不是池化来进行下采样,并且没有整合他们的Inception Token Mixer,后者将通道分为多个路径,其中一条路径是在较低分辨率上进行注意力操作。另外,与我们不同的是,Si等人在所有阶段应用了他们的InceptionFormer块,并且还缺少我们将在第4.1节中描述的其他优化措施。
我们对多头自注意力(MHSA)的调整简单且接近传统的注意力机制,避免了对已建立概念的过度复杂化处理。据我们所知,还没有人提出过这种对原始多头自注意力的调整。
3 执行时间分析
接下来我们将研究不同配置下卷积的硬件效率。例如,如果一个卷积或一组卷积具有更多的乘法累加(MAC)操作,但至少具有相似的速度,则认为它比另一个更具有硬件效率。我们将在桌面GPU和CPU上评估速度。
在第4.2节中,我们将描述如何应用从以下实验中获得的见解。
3.1 深度可分离卷积
当模型的重点在于效率和移动友好设计时,深度可分离卷积是标准卷积的一个显著替代方案。标准卷积是不分组的卷积(groups=1),而深度可分离卷积是具有与输入通道相同数量组的分组卷积。尽管深度可分离卷积在MAC操作方面是高效的,但它们并不能完全转化为常见的硬件效率。在架构设计中仅通过MAC操作来评估模型会自动导致尽可能多地插入深度可分离卷积,而不考虑实际的加速效果。为了具体说明执行时间和MAC作为效率衡量标准之间的脱节,我们使用简化的小型架构进行了一项实验。我们考察了使用深度可分离卷积对GPU吞吐量、GPU延迟和CPU延迟的影响(见表1)。我们创建了三个只有深度可分离卷积的模型(#2、#4、#6)和三个只有标准卷积的模型(#1、#3、#5)。尽管表1中的模型#1和#2具有相似的GPU吞吐量和延迟,但#1(不分组)的MAC数量是#2的4倍。同样,对于模型#3和#4也是如此。模型#5(不分组)的MAC数量甚至是#6的6倍,同时具有略高的吞吐量。然而,就GPU延迟而言,带有不分组卷积的模型(#1、#3和#5)略慢一些。
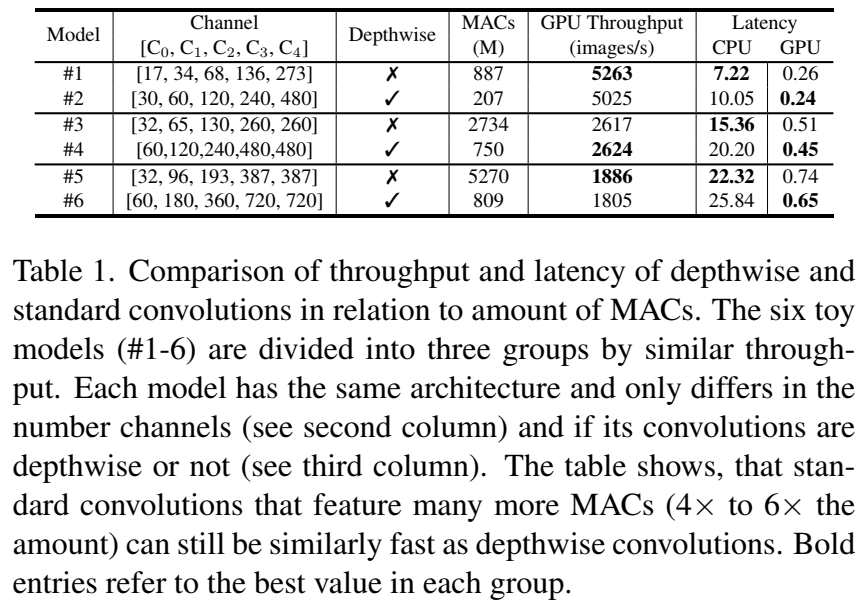
总的来说,深度可分离卷积并不像标准卷积那样具有硬件效率。它们并没有带来预期的加速效果,尽管它们的MAC数量较少。
3.2. 融合与非融合 MBConv
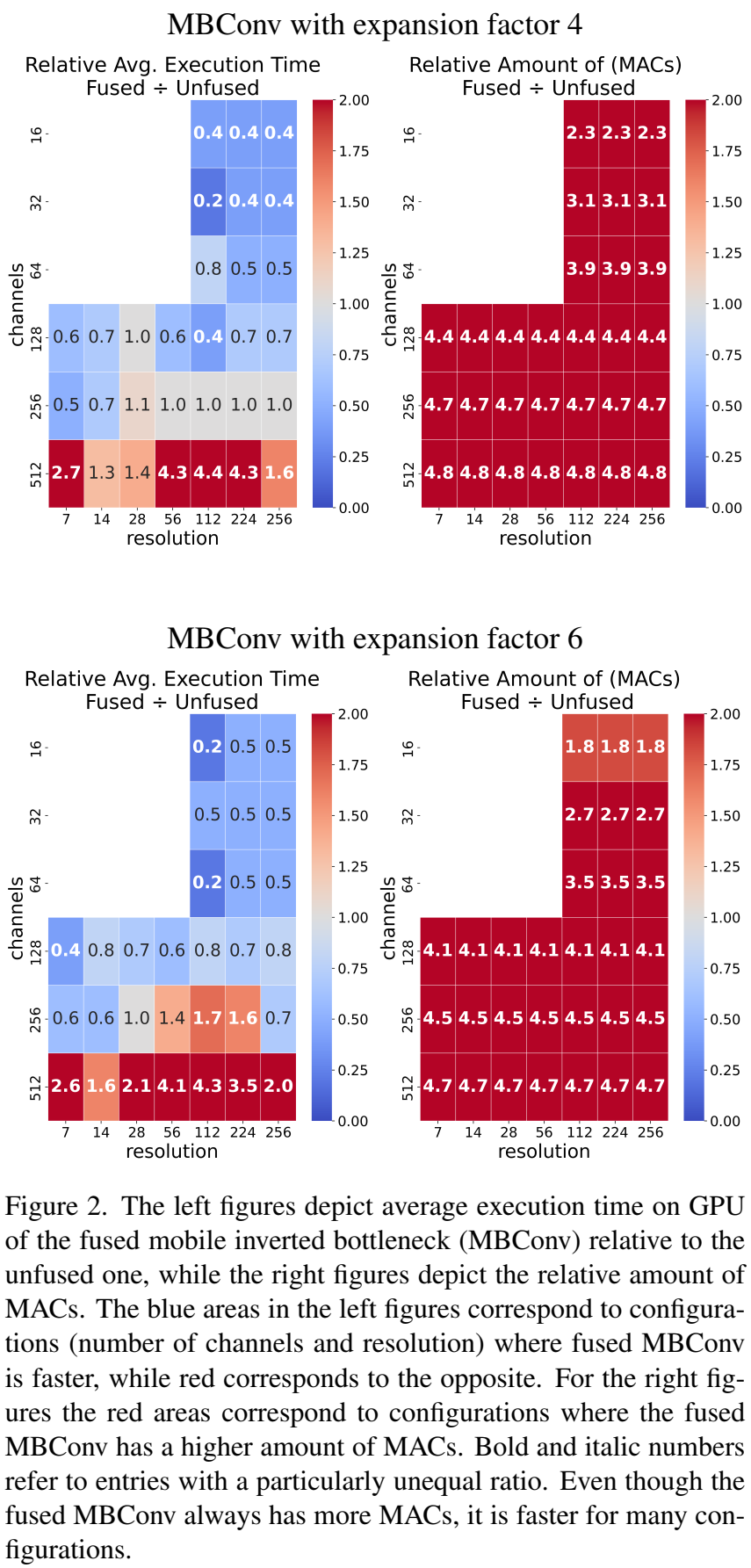
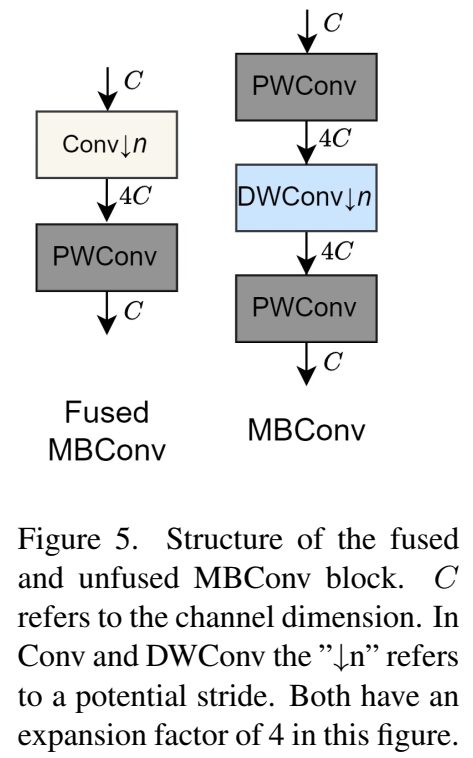
移动倒置瓶颈块(MBConv)在高效骨干网络中有着悠久且成功的历史,并且仍然被许多新方法所采用。它由两个逐点卷积(PWConv)和一个深度卷积(DWConv)组成(见图5)。逐点卷积通过给定的扩展因子增加和减少通道维度。然而,正如我们在第3.1节得出的结论,深度卷积并不是特别硬件高效。为了提高硬件效率,我们因此移除了深度卷积,转而使用融合MBConv,该方法将第一个逐点卷积与深度卷积融合为标准卷积。尽管融合MBConv更具有硬件效率(因为它没有深度卷积),但它也有显著更高的MAC数量,尽管它的层数更少。随着高通道维度,深度卷积有更好的可扩展性,因为其计算量与通道维度呈线性关系。因此,我们将比较两种模块在不同配置下的执行时间。
在图2中,我们比较了扩展因子分别为四和六的融合与非融合MBConv(第一行和第二行)。我们省略了通道数从16到64以及分辨率从7到28的情况,因为这些情况对于骨干网络架构并不相关,并且GPU利用率太低以至于结果没有意义。在这两幅图中,我们展示了融合MBConv与非融合MBConv在GPU上的平均执行时间(左侧)及其MAC数量(右侧)。我们对不同的分辨率和输入通道维度配置进行了比较。我们测量平均执行时间时使用的批量大小为200,并运行100次迭代,这与我们在第5.1节测量吞吐量的方式相同。如图2所示,分辨率和通道维度对相对执行时间有很大影响,尽管融合MBConv始终有更多的MAC(值大于一),但在许多情况下更快(左侧部分的值小于一)。只有当通道数量较高(超过512)时,相对执行时间变差,并接近相对MAC的数量。我们还在补充材料中评估了GPU延迟。此外,我们在第5.3节中通过我们的模型LowFormer-B1进一步展示了这种影响。
3.3. 高分辨率与高通道数
层的操作分辨率和通道数对硬件执行效率有重大影响。在表2中,我们通过创建由20个相同的层堆叠组成的模型来比较不同的层配置。表2中列出了七种场景,每种场景都对比了两个MAC数量(精确到小数点后一位)相同但通道维度和操作分辨率不同的层。为了比较这些层的硬件效率,我们测量了GPU延迟和吞吐量。这些模型仅包含标准卷积(非分组)。
表2清楚地表明,较高的分辨率导致较低的硬件执行效率,而较多的通道数则影响较小。例如,在场景#1中,第一个卷积的吞吐量仅为第二个卷积的三分之一,且延迟几乎是其三倍。虽然它处理的分辨率是第二个卷积的八倍,但通道数较少,其MAC数量等于第二个卷积。同样的效果也出现在分辨率差异较小的情况下,如场景#2所示,其中第一个卷积的分辨率是第二个卷积的两倍,但在吞吐量和延迟方面仍未能像第二个卷积那样快速执行其MAC运算。
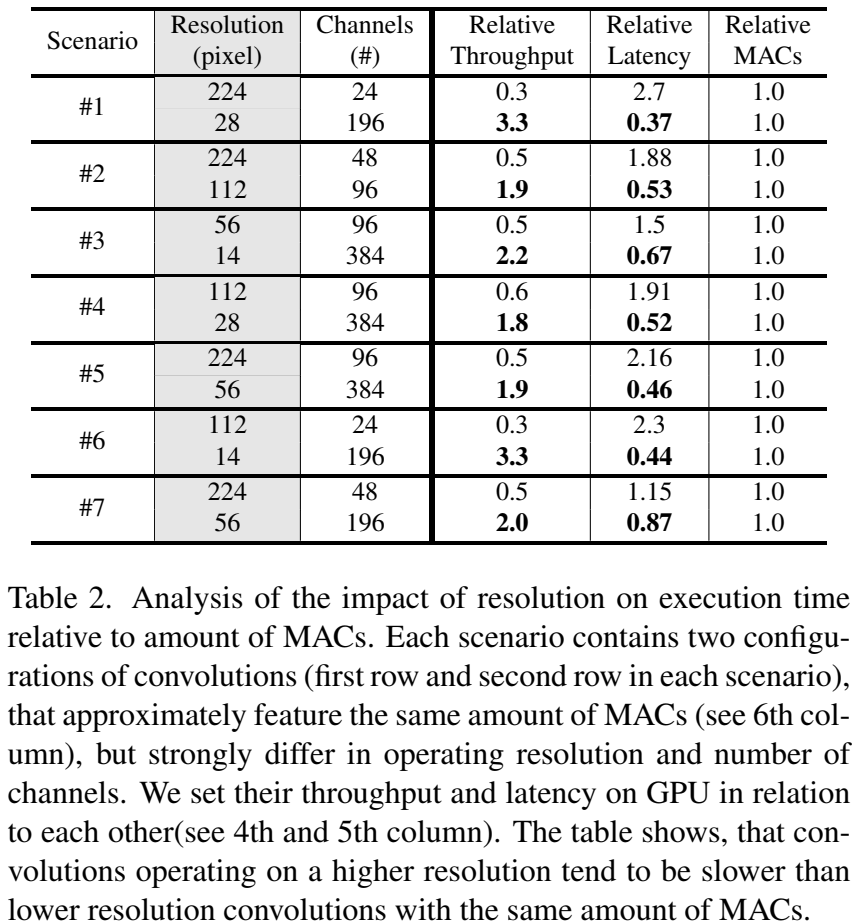
高分辨率操作可能会使模型速度降低的程度超过MAC数量所显示的情况,而减少操作分辨率可以显著提高硬件效率。我们强调,模型缩放应更多地依据实际测量速度,因为MAC数量可能会产生误导,尤其是在通过更高输入分辨率缩放模型时。
4 方法
在以下部分中,我们将描述我们提出的轻量级多头自注意力机制(MHSA)的改进版本及我们的硬件高效宏观设计。此外,我们还将解释这两种方法是如何从第3节中的执行时间分析中获得的洞见中产生的。
4.1 轻量级注意力机制
在最后两个阶段,我们采用了一种轻量级的MHSA改进版本,如图4所示。我们将这种改进命名为LowFormer注意力机制。在我们的改进版本中,缩放点积注意力(SDA)被两个深度卷积和两个逐点卷积所封装,这两个卷积执行查询(Q)、键(K)和值(V)的输入和输出投影。
通道压缩。在输入投影过程中,Q、K 和 V 的通道维度被减半。经过SDA之后,通过输出投影恢复到原始的通道维度。
降低分辨率。根据第3.3节中的分析,高分辨率会不成比例地减慢卷积速度。我们将这一发现应用于注意力机制中,因此在倒数第二阶段,卷积(参见图4)同样降低了SDA前后特征图的分辨率,使得注意力操作在一半的分辨率上执行。在第5.3节中,我们将展示这一措施对吞吐量和延迟有显著影响。
由于这两种改进,输入到SDA的所有维度(通道维度、高度和宽度)都被缩减,因此我们用“轻量级”一词来描述LowFormer注意力机制。
跟随注意力机制的MLP。遵循Vaswani等人的工作,我们在LowFormer注意力机制之后添加了层归一化和多层感知器(MLP)。我们发现这对模型准确性有显著影响,并且Liu等人指出,MLP比注意力操作更具有硬件效率。
4.2 宏观设计
我们的宏观设计基于EfficientViT和MobileViT。该设计包含五个阶段,并主要依据以下两点改进架构,这些改进源自第3节中的执行时间分析。整个架构如图3所示。我们展示了五种不同版本的架构,即B0-B3(B0、B1、B1.5、B2、B3)。具体架构细节列于表3中。以下是具体改进:
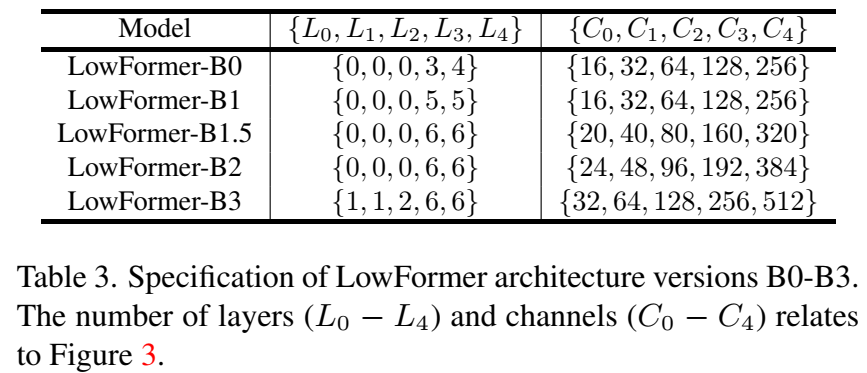
前几阶段的较少层数。根据第3.3节中的分析,我们得出结论:在前几个阶段使用最少层数更加符合硬件效率(见表3)。对于前三个阶段应用这种减少被证明是最优的。因此,大部分计算集中在最后两个阶段,对于输入尺寸为224×224的情况,操作分辨率分别为14×14和7×7。
融合深度卷积和逐点卷积。在第3.1节中,我们表明深度卷积不如标准卷积硬件效率高;而在第3.2节中,我们得出结论,融合的MBConv(见图5)可以比未融合的更快。然而,随着通道数量的增加,这种效果逐渐减弱。因此,在输入通道数最多达到256的情况下,我们在架构中融合了MBConv,除了最后一阶段中的步长为2的MBConv块仍然进行了融合(见图3)。此外,我们在LowFormer注意力机制中SDA之后也融合了深度卷积和逐点卷积(见图4)。我们在第5.3节的消融研究中通过取消LowFormer-B1的MBConv块的融合来验证这种方法的效果。
5 实验
5.1 ImageNet-1K 分类
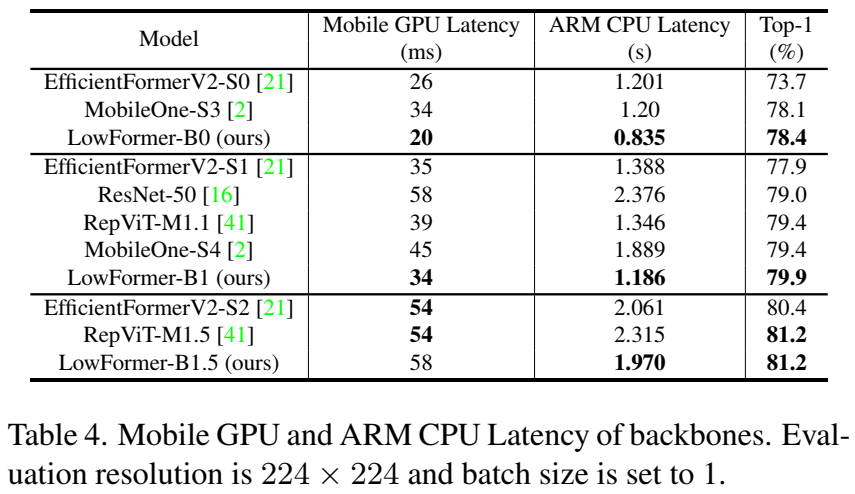
设置。我们在ImageNet-1K 数据集上进行了图像分类实验,该数据集包含1000个类别下的128万训练图像和5万验证图像。所有模型都是从头开始训练的,主要采用与Cai等人相同的设置,并且输入分辨率为224。我们总共训练了320个周期,使用AdamW优化器和的学习率,不过我们使用的批量大小为512。作为学习率调度器,我们采用了余弦衰减并设置了20个线性预热周期。我们也加入了Cai等人提出的多尺度学习方法。我们以批量大小2400和基础学习率训练了LowFormer-B3。对于LowFormer-B2,我们使用批量大小850和基础学习率。
GPU 吞吐量与延迟。在表5中,我们通过GPU吞吐量和延迟来衡量速度。为了测量GPU吞吐量,我们在Nvidia A40显卡上以批量大小200运行100次迭代,并取每个输入图像的中间时间为基准计算总吞吐量。为了测量GPU延迟,我们在Nvidia Titan RTX上以批量大小16运行400次迭代。此外,我们将所有模型编译为TorchScript代码并针对推理进行优化。我们为延迟和吞吐量测量设置了5次预热迭代。
结果。为了更好地比较各种方法,我们包括了在不同分辨率下评估的LowFormer-B1和LowFormer-B3版本(见表5)。LowFormer的各种变体在相似或更低的GPU吞吐量条件下在top-1准确率方面优于所有其他方法。测试于分辨率256的LowFormer-B1r256比EfficientViT-B1的top-1准确率高出0.8%,并且吞吐量高23%。它同样胜过RepViT-M1.1,但吞吐量高73%,延迟低21%。测试于分辨率224的LowFormer-B1相比SHViT-S4r256准确率仅提高0.44%,吞吐量相当。然而,SHViT架构通过增加输入分辨率的方式提升模型复杂度是无效的(见第3.3节),其最佳模型SHViT-S4r512(测试于分辨率512)在相似吞吐量条件下top-1准确率比LowFormer-B3低1.64%。当比较LowFormer-B3与GhostNetV2x1.0时,我们设计的硬件效率以及MAC数量与执行时间之间不一致的关系变得尤为明显。前者吞吐量是后者的3倍,延迟低20%,MAC数量是其36倍,并且top-1准确率高出8.3%。
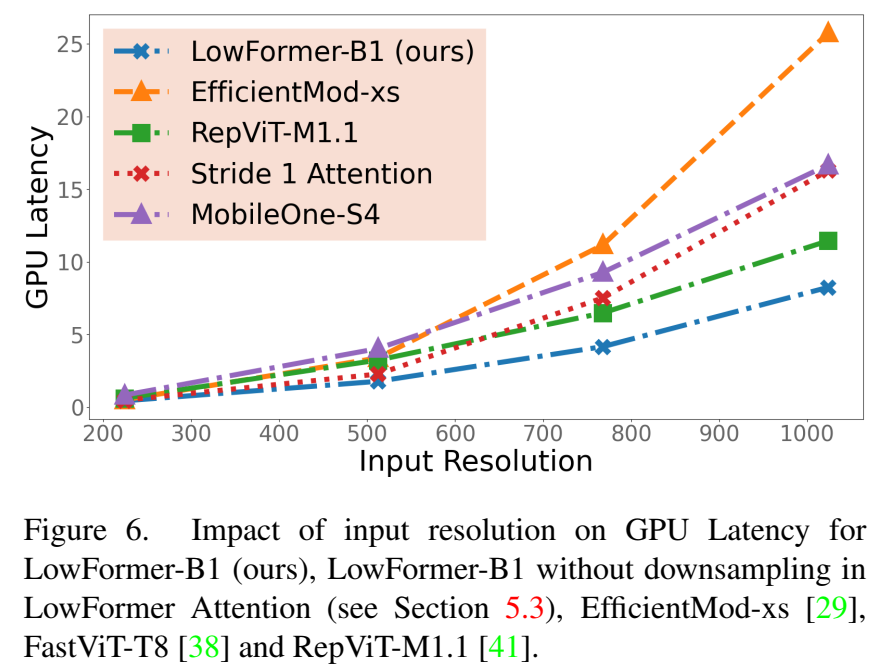
分辨率缩放。在图6中,我们研究了增加输入分辨率对GPU延迟的影响。无论输入分辨率如何,LowFormer-B1在ImageNet-1K上的top-1准确率方面均优于所展示的模型,并且速度显著更快。在补充材料中,我们还使用批量大小200进行了相同评估以估计吞吐量变化。
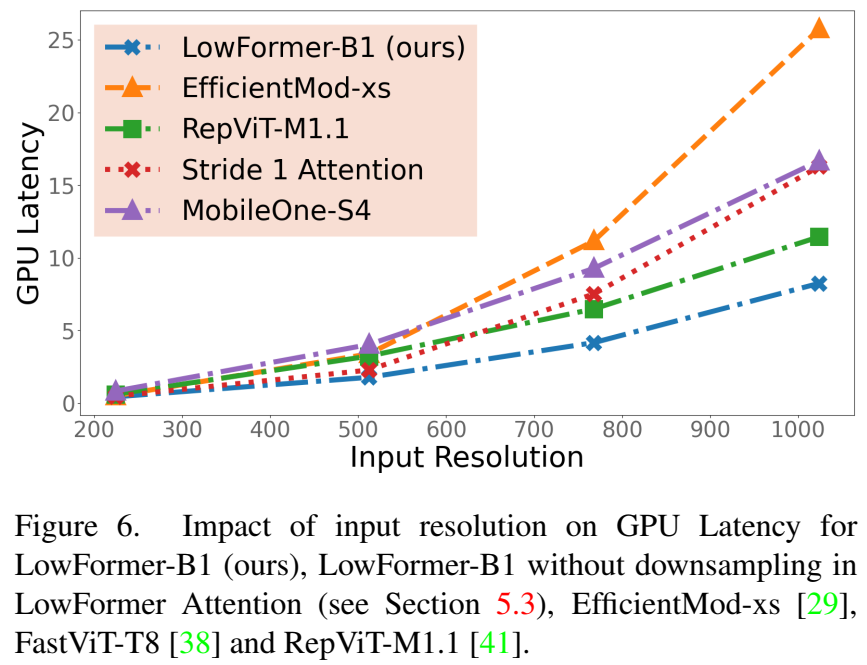
移动GPU和CPU延迟。在表4中,我们也在移动GPU(ARM Mali-G76 MP12)和ARM CPU(ARM Cortex A53)上验证了模型的效率。我们以批量大小1和分辨率224×224运行模型。对于ARM CPU,我们运行了30次迭代;而对于移动GPU,则运行了10000次迭代,其中1000次为预热迭代。尽管我们的架构并非专门为边缘应用而优化,但例如,LowFormer-B1的top-1准确率比MobileOne-S4 高0.5%,而后者移动GPU延迟高32%,ARM CPU延迟高59%。
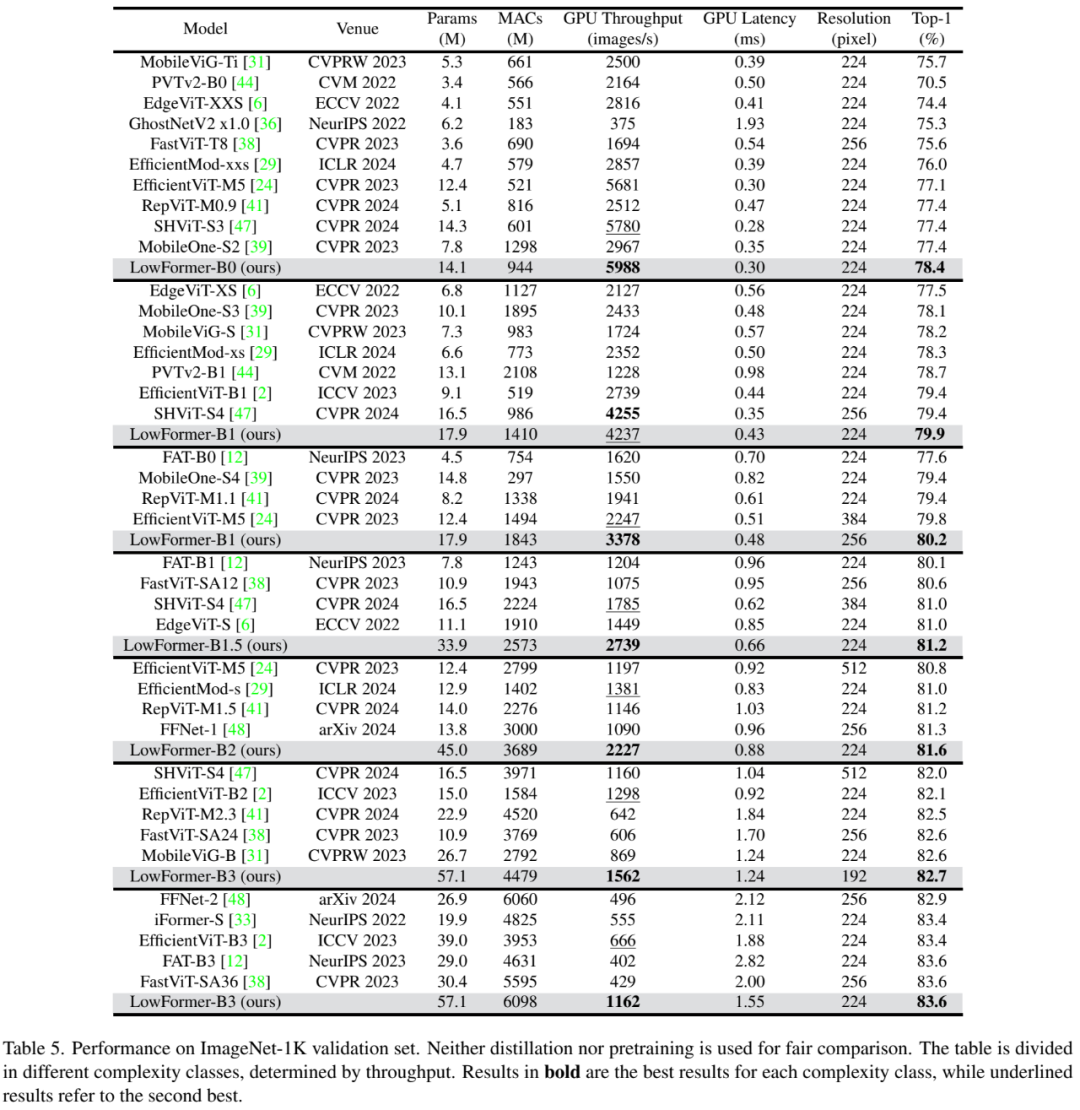
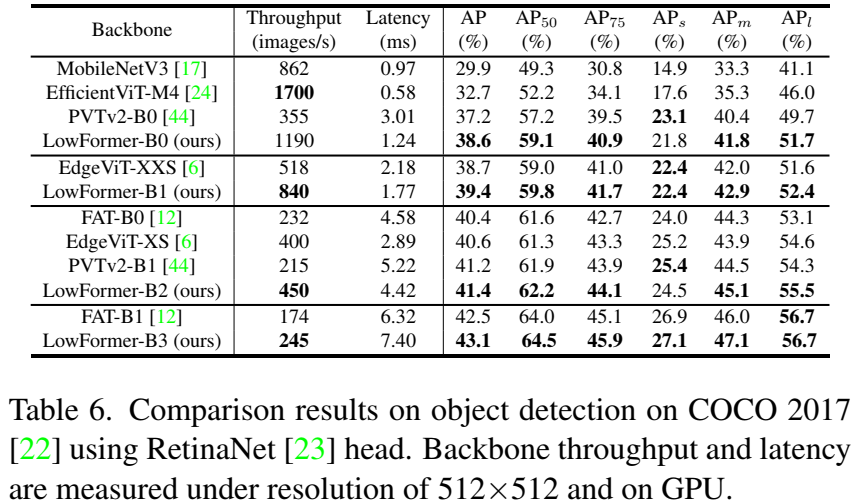
5.2 物体检测与语义分割
利用预训练骨干网络。我们利用预训练的骨干网络应用于物体检测和语义分割任务。我们在COCO 2017 和ADE20K数据集上分别使用mmdetection和mmsegmentation进行训练和评估。对于物体检测任务,我们采用RetinaNet框架;而对于语义分割任务,则将我们的骨干网络嵌入到Semantic FPN中。为了测量骨干网络的GPU吞吐量和延迟,我们遵循第5.1节中的协议,但在输入分辨率为512×512的情况下进行评估。
物体检测。训练模型12个周期(1x调度)。就结果而言,例如,LowFormer-B2相较于FAT-B0在AP值上高出+1.0分,同时在512×512分辨率下具有93%更高的骨干网络吞吐量(见表6)。
语义分割。对于语义分割任务,使用批量大小为32训练模型40000次迭代。我们使用AdamW优化器,学习率采用余弦退火方式调整,基础学习率为,并带有1000步线性增长的预热阶段。例如,LowFormer-B1相较于EfficientFormerV2-S2具有2.4倍的吞吐量和20%的延迟降低,但在嵌入Semantic FPN后实现了+0.4 mIoU的提升(见表7)。
5.3 消融研究
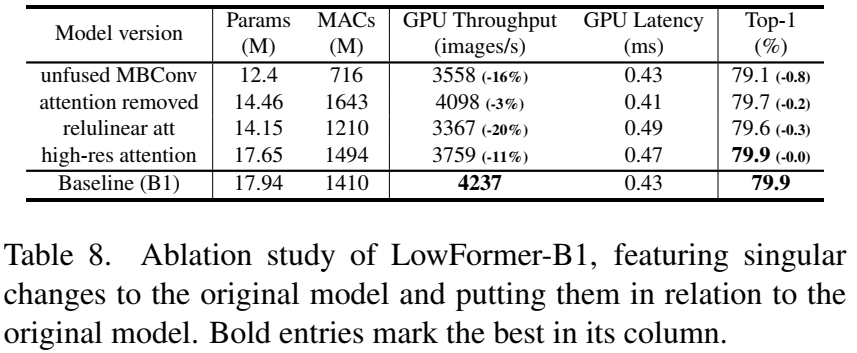
表8中的消融实验展示了我们对模型设计决策的对比分析。我们将LowFormer-B1的一个特定设计恢复至原始状态,以展示该变化对准确度、吞吐量和延迟的影响。具体对比实验包括:
替换所有融合的MBConv块:我们将所有融合的MBConv块替换为非融合版本。
移除LowFormer模块:我们移除LowFormer模块,并在每个阶段添加一个额外的MBConv块,使对比模型具有与基线相同的吞吐量(在表8中称为“移除注意力”)。
替换注意力机制:我们将LowFormer注意力机制替换为Cai等人提出的ReLU线性注意力机制,以比较我们的注意力方法与其他最近的改进方案。
移除特征图降尺度处理:我们取消了LowFormer注意力机制中的特征图降尺度处理。
讨论。将融合的MBConv替换为非融合版本导致Top-1准确度降低了0.8%,且其GPU吞吐量也减少了16%(见表8)。我们可以看到,除了提高吞吐量外,融合MBConv还可以显著提高性能。
另一方面,用卷积层替换每个阶段的LowFormer模块仅导致Top-1准确度的小幅下降。然而,由于增加了额外层,架构深度扩展的潜力减小,因为阶段中的层数越多,它们的效果就越不明显。
当我们移除LowFormer注意力机制中的降尺度处理时,Top-1准确度保持不变,但GPU吞吐量和延迟变差。如图6所示,对于较高的输入分辨率,延迟差异会成倍增加。例如,在输入分辨率为1024×1024时,延迟增加了70%。
6 结论
我们展示了高分辨率和深度卷积如何负面影响硬件效率,并提出了如何在架构中替换深度卷积的方法。我们还提出了一种简单的轻量级注意力机制,并证明使其在较低分辨率下运行不会降低准确度,反而会导致执行速度明显加快,尤其是在模型输入分辨率增加的情况下。我们的硬件高效宏观和微观设计相比以往方法带来了显著的速度提升。此外,我们进一步证明了我们的骨干架构在物体检测和语义分割中的适用性。

—END—
论文链接:https://arxiv.org/pdf/2409.03460v1

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









