






导读
我们提出了一种简单而有效的数据集裁剪方法,该方法通过探索预测的不确定性以及训练的动力学特性。广泛的实验结果表明,我们的方法超越了现有技术,并在ImageNet-1K和ImageNet-21K上实现了75%的无损压缩比。

摘要
许多学习任务的最先进水平,例如图像分类,都是通过收集更大的数据集并在此基础上训练更大的模型来提升的。然而,随之而来的计算成本增加正变得难以承受。在本文中,我们研究了如何对大规模数据集进行裁剪,从而产生一个信息量丰富的小子集,用于训练复杂的深度模型,同时性能下降可以忽略不计。我们提出了一种简单而有效的数据集裁剪方法,该方法通过探索预测的不确定性以及训练的动力学特性。据我们所知,这是首次针对大规模数据集(如ImageNet-1K和ImageNet-21K)以及高级模型(如Swin Transformer和ConvNeXt)进行数据集裁剪的研究。广泛的实验结果表明,我们的方法超越了现有技术,并在ImageNet-1K和ImageNet-21K上实现了75%的无损压缩比。代码和裁剪后的数据集可在https://github.com/BAAI-DCAI/Dataset-Pruning 获取。
1 介绍
新兴的大规模模型,比如计算机视觉中的视觉Transformer,当有大规模训练数据,如ImageNet-21K和JFT-300M可用时,能够显著优于传统的神经网络,例如ResNet。然而,存储大规模数据集并在其上进行训练既昂贵又可能超出某些人的负担能力。这种计算成本阻止了资源有限的个人或机构超越现有技术水平。如何提高深度学习方法的数据效率,并以较低的训练成本获得良好的性能,一直是个长期存在的问题。
已知大规模数据集中有许多冗余且简单的样本,这些样本对模型训练的贡献很小。数据集裁剪(或核心集选择)旨在移除那些信息量较少的训练样本,保留原始数据集中的信息量较大的样本,使得在剩余子集上训练的模型能够达到可比较的性能。然而,如何找到这个信息量大的子集是一个具有挑战性的问题,尤其是对于大规模的数据集和模型而言,因为样本选择是一个组合优化问题。
现有的数据集裁剪工作基于几何/分布、预测不确定性、训练误差/梯度等选择重要样本。但是,这些方法主要集中在小规模数据集,例如包含只有50K个分辨率为32×32的训练图像的CIFAR-10/100,以及传统的卷积模型,如ResNet。这些方法扩展到大规模数据集和模型存在三个主要困难。首先,许多裁剪方法具有较高的计算复杂度,例如O(n²),这不适合数百万样本的数据集。其次,一些方法对架构和超参数敏感。调整超参数需要大量的计算。最后,不同的数据集具有不同数据分布和冗余属性。实际上已经证实,许多数据集裁剪方法仅略好于随机选择基线,有时甚至更差。
在本文中,我们首次研究了用于训练高级模型的大规模数据集裁剪。我们设计了一个简单而有效且可扩展的数据集裁剪指标。如图1a所示,训练集可以分为易于学习的样本(具有较高的平均预测准确率和较小的偏差)、难以学习的样本(具有较低的平均预测准确率和较小的偏差),以及其余不确定的样本。根据先前的工作,我们设计了一个指标来保留这些不确定的样本,并移除过于简单和过于困难的样本。由于不确定性在整个训练过程中可能会变化,我们将训练动力学引入了该指标,该指标在整个训练周期内通过滑动窗口测量不确定性。我们对所有训练样本的动态不确定性进行排名,并移除值较小的样本。实验验证,我们的方法持续优于最先进的数据集裁剪方法,并在ImageNet-1K和ImageNet-21K上训练Swin Transformer时达到了75%的无损压缩比。我们进一步展示了我们的方法在跨架构和分布外任务中的良好表现。
本文的主要贡献总结如下:
我们首次研究了用于训练高级模型的大规模数据集裁剪。
基于预测不确定性和训练动力学,我们设计了一种简单、有效且可扩展的数据集裁剪方法。
我们的方法优于最先进的数据集裁剪方法,并在ImageNet-1K和ImageNet-21K上实现了75%的无损压缩比。
2 相关工作
2.1 数据集裁剪
数据集裁剪主要源自核心集选择,后者专注于从大型数据集中选取一个小但高度信息丰富的子集来训练模型。数据集裁剪方法通常根据预定义的标准为每个训练样例计算一个标量分数。这些方法可以归类为基于几何的、基于不确定性的、基于错误的、基于双层优化的等。例如,(1) 基于几何的方法在特征空间中使用几何度量来选择保持原始几何特性的样本。代表性方法包括Herding,它逐步选择一个样本,使新子集中心最接近整个数据集中心。K-Center方法最小化任何数据点到所选子集最近中心的最大距离,而Moderate Coreset[41]则针对距离接近中位数的数据点。(2) 基于不确定性的方法识别最具挑战性的样本,这些样本通常被定义为模型置信度最低的实例,或者是那些位于决策边界附近,预测变异性高的样本。例如,通过考虑预测分布的方差来调整分配给训练样本的权重。(3) 基于错误的方法关注对损失贡献最大的样本。GraNd和EL2N方法利用梯度范数和预测概率与独热标签之间的L2距离来识别重要样本。另一种流行的方法是Forgetting,它考虑保留最容易被遗忘的样本。这些样本定义为在整个训练过程中从正确分类翻转为错误分类最频繁的样本。还有一些基于双层优化的方法,它们优化导致在子集上训练的最佳模型的子集选择(权重)。然而,由于复杂的双层优化,这些方法难以扩展到大型数据集。
虽然上述方法在小型数据集和传统(卷积)模型上表现出色,但我们经验性地发现,基于小型数据集的研究在推广到更大数据集和现代大规模模型(如视觉Transformer)方面存在困难。认识到这一限制,我们的工作采取了前所未有的步骤,对高度广泛的特定数据集——即ImageNet-1K和ImageNet-21K——进行裁剪,并使用像Swin Transformer和ConvNeXt这样的最新大型模型进行评估。这一进展标志着该领域的一个关键里程碑,解决了对能够处理非常大数据集和前沿模型的有效数据裁剪方法的需求。
2.2 数据集蒸馏
另一个专注于减少训练数据量的研究主题是数据集蒸馏。不同于选择子集,这些研究学习合成一个高度紧凑但信息丰富的数据集,该数据集可以从头开始用于模型训练。合成过程涉及在模型训练于原始数据集和训练于合成数据集之间对齐多个因素,如性能、梯度、分布、特征图以及训练轨迹。尽管这些技术前景光明,但由于图像合成相关的像素级优化带来的计算负担,目前这些技术无法扩展到大规模数据集和模型。此外,现有的数据集蒸馏方法在合成大量训练样本的实验中相对于子集选择方法显示出的性能提升微乎其微,因为优化越来越多的变量(像素)是极具挑战性的。
3 方法
3.1 符号表示
给定一个大规模标注数据集T,包含n个训练样本,记作,其中是数据点,是属于C类别的标签。数据集裁剪的目标是从训练样本中移除信息较少的部分,然后输出一个子集,满足,即核心集,它可以用来训练模型,并且达到与整个数据集上训练的模型相当的泛化性能:
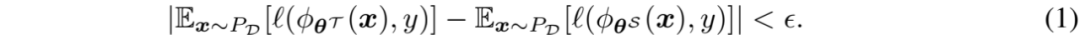
这里表示真实的数据分布。和分别是在T和S上训练的、由参数参数化的模型。是一个小正数。压缩率计算公式为。
3.2 数据集裁剪
通常做法是将训练样本分为三类:简单样本、不确定样本和困难样本。以往的研究表明,在不同的学习任务中选择简单样本、不确定样本或困难样本可能都会表现良好。例如,Herding方法倾向于选择接近类别中心的简单样本。GraNd 和 EL2N则挑选具有大训练梯度或误差的困难样本。与之不同的是,测量训练样本的不确定性并保留那些预测不确定性大的样本。因此,最佳的选择策略由多种因素决定,包括数据集大小、数据分布、模型架构和训练策略。
预测不确定性。我们设计了一种简单而有效的大型数据集裁剪方法,该方法通过同时考虑预测不确定性和训练动态来选择样本。较大的数据集中可能含有更多的可以替代用于模型训练的简单样本,以及由于图像与标签之间的不一致性而无法学习的困难/噪声样本。换句话说,剩余样本上训练的模型可以很好地泛化到这些简单样本,而过度拟合噪声样本并不会提高模型的泛化性能。因此,我们选择保留预测不确定性大的样本,移除其余部分。
给定第k轮迭代时在整个数据集上训练的模型,其对目标标签的预测记为。不确定性定义为在连续 J 次训练轮次中使用模型进行预测的标准差:
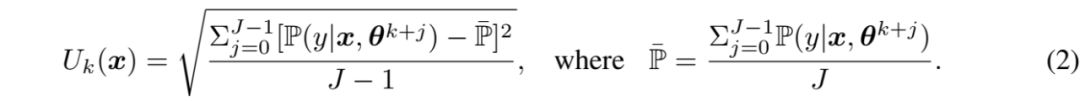
J是计算偏差的范围。
训练动态。先前的工作设计了各种不确定性度量,这些度量通常是在特定的训练轮次中测量的,例如,在最后一个训练轮次。然而,对于处于不同训练轮次的模型,不确定性度量可能会有所不同。因此,我们通过引入训练动态来增强不确定性度量。具体来说,我们在长度为J的滑动窗口内测量不确定性,然后在整个训练过程中平均不确定性:

其中 ( K ) 是训练轮次。
训练算法如算法1所示。给定一个数据集T,我们训练模型以计算每个样本的动态不确定性。在每次训练迭代中,对每个样本都会计算预测值和损失值。请注意,这些计算可以通过GPU并行处理。一批次上的平均损失用于更新模型参数。同时,我们基于过去J轮次的预测来计算每个样本的不确定性,使用公式2。经过K 轮训练后,使用公式3计算动态不确定性。然后,我们将所有样本按照动态不确定性从高到低排序,并输出前个样本作为裁剪后的数据集 S,其中 r 是裁剪比例。

3.3 裁剪数据的分析
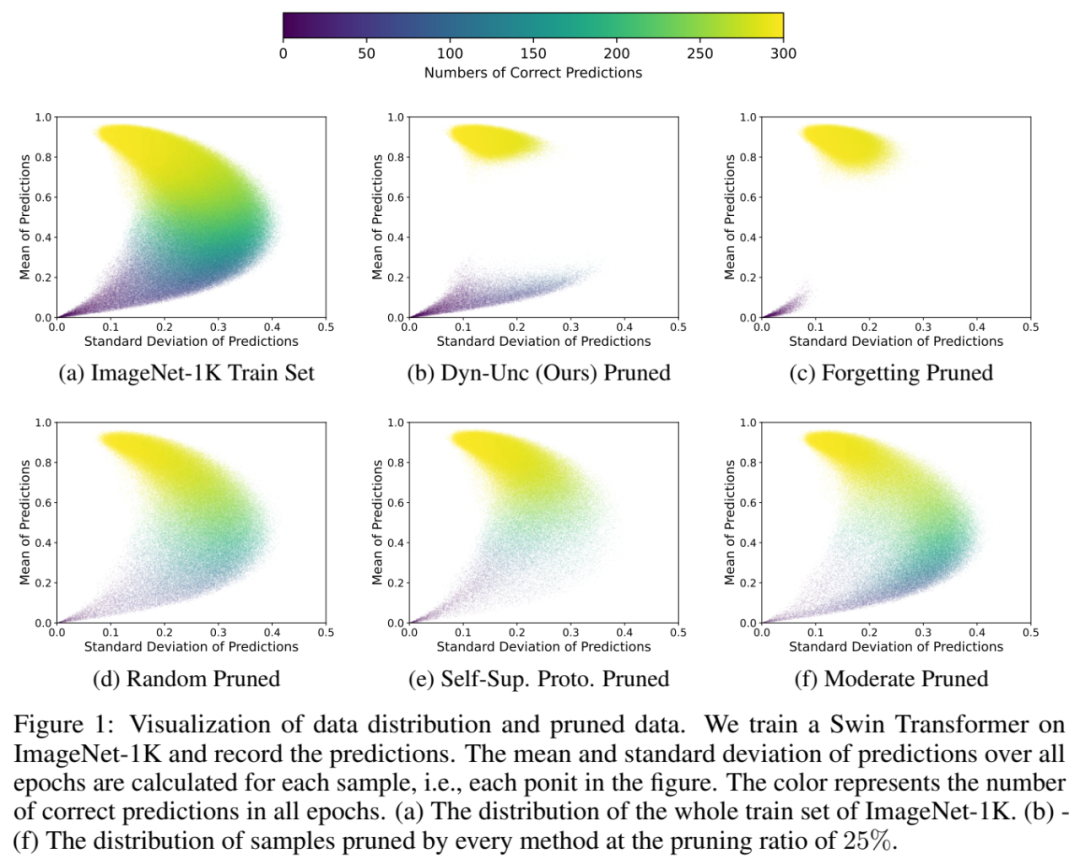
我们从预测准确性和方差的角度分析训练数据。我们在ImageNet-1K上训练了一个Swin Transformer,并记录了整个训练过程中每个训练样本的预测值。需要注意的是,这里的预测值是一个与真实标签相对应的概率标量。随后,对于每个训练样本,我们计算其在整个训练过程中的预测值的均值和标准差,它们分别构成了y轴和x轴。颜色反映了整个训练过程中正确预测的数量。如图1所示,训练集可以大致分为三组:1)容易样本,具有较高的平均准确率和较低的偏差;2)困难样本,具有较低的平均准确率和较低的偏差;3)不确定样本,即其余部分。关于样本选择的先前工作,特别是主动学习,建议采用不确定性采样来最小化模型预测的不确定性。大多数这些度量都是统计性的,即仅在一个预测/变量集上计算一个偏差/方差。相比之下,提出的度量是在整个训练过程中的一系列偏差上的平均值。我们在图1中可视化了通过三种最先进的方法以及我们的方法裁剪的数据(25%)。我们的方法去除了很大比例的容易样本,这些样本具有高平均准确率和低偏差,以及许多同时具有低平均准确率和低偏差的困难样本。请注意,我们的方法不同于使用统计度量(例如,使用y轴,即平均准确率)的简单裁剪。遗忘方法去除了更多的容易样本而较少的困难样本,因为在模型训练期间,一些困难样本可能会导致连续的翻转,即较大的遗忘性。然而,这样的样本可能对模型训练的信息量较小,同时也会减慢收敛速度。温和法和自监督原型法都去除了许多容易样本。对于遗忘法和我们的方法而言,不确定样本很少被去除,因为这两种方法都考虑了训练动力学。与遗忘法和我们的方法不同,其余两种方法(自监督原型法和温和法)去除了许多不确定样本,因为它们只考虑了特征分布。图2展示了一些由我们的方法保留或去除的困难样本。显然,被我们的方法去除的这些困难样本可能是错误标注的。例如,“牛仔靴”被错误地标记为“扣环”。而被我们的方法保留下来的困难样本仍然是可识别的,尽管它们包含一些变异性。例如,“黑天鹅”中有“白天鹅”,“扫帚”的图片中有一个拿着“扫帚”的人。

4 实验
4.1 数据集和设置
数据集和架构。我们在ImageNet-1K和ImageNet-21K上评估了我们的方法,这两个数据集分别有130万和1400万个训练样本。我们在实验中主要使用Swin Transformer,同时也测试了ConvNeXt和ResNet。我们将输入尺寸设为224 × 224。
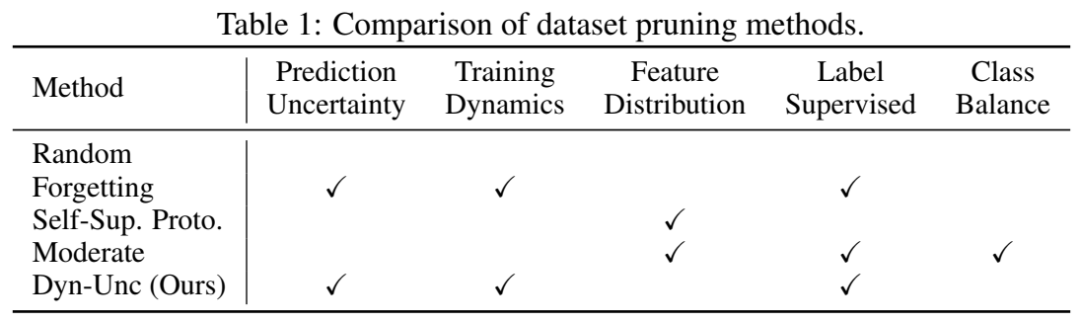
对比方法。我们与多种代表性和最先进数据集裁剪方法进行了比较,包括随机(Random)、遗忘(Forgetting)、自监督原型(Self-Supervised Prototypes)和温和法(Moderate)。随机基线以均匀概率从整个数据集中随机选取样本。先前的研究表明,随机是一种在多个数据集裁剪任务中的强大基线。遗忘法移除那些模型现在分类错误但在上次迭代中分类正确的样本,这些样本发生的遗忘事件较少。遗忘法能够反映不确定性和训练动态,因为不确定样本可能在整个训练过程中持续翻转。自监督原型法和温和法都是基于使用训练良好的深度模型的特征分布实现裁剪。自监督原型法移除那些在自监督预训练后经过k-means聚类,其表示与最近的聚类中心(称为原型)具有较大余弦相似度的样本,而不考虑标签。温和法则使用某一类别中所有样本的平均特征作为该类别的中心。然后,在每个类别中,温和法基于欧几里得距离移除那些表示与中心过于接近或远离的样本。表1总结了这些方法的特点。
值得注意的是,还有许多其他的数据集裁剪方法,这些方法难以扩展到大型数据集和模型。例如,利用影响函数来计算样本对网络参数产生的影响,并通过带有约束的离散优化来裁剪数据集。然而,影响函数的计算基于海森矩阵,对于大型模型来说计算成本巨大。即使采取随机估计来加速计算,它仍然需要O(np)的时间复杂度,其中n和p分别是训练样本数量和网络参数数量。对于拥有数百万样本的ImageNet-1K和拥有数亿参数的视觉变换器,这种方法实际上是不可行的。在NLP任务上进行了实验,显示训练模糊数据可以获得相当好的同分布和异分布性能。我们的初步实验证明这种方法在ImageNet上表现不佳。
实现细节。所有实验都在NVIDIA A100 GPU上使用PyTorch进行。为了加速数据加载和预处理,我们使用了NVIDIA数据加载库(DALI)。对于我们的方法,我们使用J=10作为窗口长度。所有实验都在ImageNet-1K和ImageNet-ReaL的验证集上进行评估。ImageNet-ReaL重新评估了ImageNet-1K-val的标签,并大幅修正了原始标签中的错误,强化了一个更好的基准。报告了两个验证集上的Top-1准确率。
在主要实验中,我们比较了所有五种方法在ImageNet-1K和Swin-T下的25%、30%、40%和50%的裁剪比例。对于自监督原型(Self-Sup. Proto.),我们使用了一个在ImageNet-1K上使用SimMIM预训练和微调过的Swin-B作为特征提取器。为了实现其他的数据集裁剪方法,我们训练了一个Swin-T。我们采用了AdamW优化器,并使用余弦退火学习率调度器和20个epoch的线性预热来训练模型300个epoch。批处理大小为1024。初始学习率为0.001,权重衰减为0.05。我们应用了在NVIDIA DALI中实现的AutoAugment、标签平滑、随机路径丢弃和梯度裁剪。
我们还在ImageNet-21K上实施了实验,以展示我们方法的良好泛化能力和可扩展性。首先,我们在ImageNet-21K(2011年秋季版本)上预训练Swin-T 90个epoch,其中包括5个epoch的预热。然后,我们使用余弦退火学习率调度器、1024的批处理大小、的初始学习率和的权重衰减,在ImageNet-1K上对模型进行30个epoch的微调,同样包含5个epoch的预热。
4.2 裁剪ImageNet-1K
表2展示了五种方法在不同裁剪率下的性能。显然,我们的方法Dyn-Unc在所有设置中都达到了最佳性能。具体来说,当裁剪25%的训练样本时,我们的方法在ImageNet-1K-val和ImageNet-1K-ReaL上分别获得了79.54%和84.88%的top-1准确率,这与不进行裁剪情况下的上限性能79.58%和84.93%相当。这些结果表明,我们的方法可以实现75%的无损数据集压缩比。
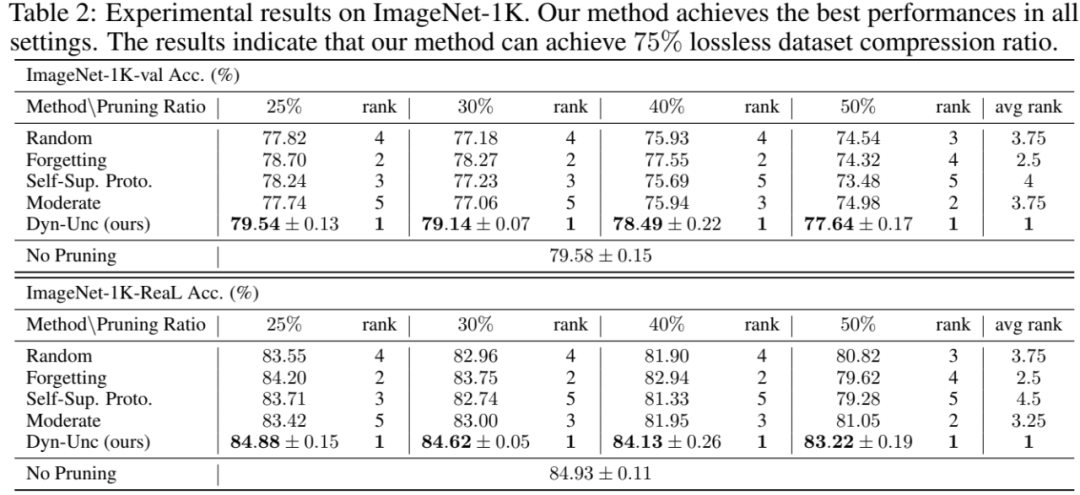
无论是在原始验证集还是ReaL上,方法的排名都是一致的。我们的方法与其他方法之间的性能差距显著。随着更多的训练数据被移除,这种差距在更具挑战性的设置中变得更加明显。例如,在裁剪25%、30%、40%和50%的样本时,我们的方法分别比“遗忘”方法高出0.84%、0.87%、0.94%和3.32%,考虑到标准差大约为0.2%。
当裁剪少于40%的训练数据时,“遗忘”方法总是位居第二。这一现象强调了基于预测不确定性与训练动态的方法的重要性。然而,“遗忘”方法从裁剪40%到50%的样本时经历了较大的性能下降。我们在图4中比较了我们方法和“遗忘”方法所裁剪的样本。可能的原因是“遗忘”方法抛弃了更多的简单样本,这使得模型训练变得不稳定。
总体而言,基于特征分布的方法Self-Sup. Proto.和Moderate表现不佳。当裁剪50%的训练数据时,随机基线在两个验证集上的表现均超过了“遗忘”和Self-Sup. Proto.。平均排名显示,Self-Sup. Proto.在ImageNet-1K裁剪任务中的表现最差。可能的原因可能是该方法缺乏来自标签的监督。我们也通过图3展示了这些结果,以便更容易地进行视觉比较。
此外,我们还在ConvNeXt上测试了我们的方法。当裁剪25%的训练数据时,Dyn-Unc在ImageNet-1K-val和ImageNet-1K-ReaL上分别达到了78.77%和84.13%的准确率,而未裁剪的结果分别为78.79%和84.05%,这表明我们的方法可以推广到不同的模型。我们将在第4.4节进一步研究我们的方法在跨架构上的泛化能力。
4.3 裁剪ImageNet-21K
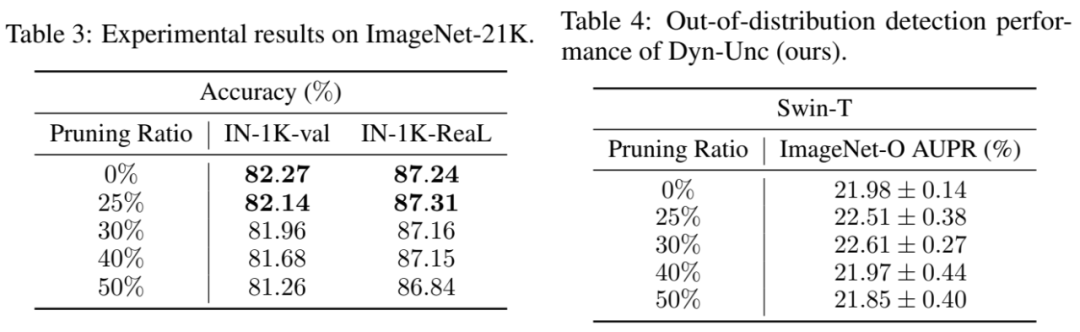
在本文中,我们首次在包含1400万张图像的ImageNet-21K上测试数据集裁剪算法。高昂的计算成本阻止了先前的研究对这一数据集进行研究。如表3所示,我们以不同的比例裁剪ImageNet-21K,然后在ImageNet-1K-val和ImageNet-1K-ReaL上进行测试。当裁剪25%的训练数据时,使用我们裁剪后的数据集训练的Swin-T模型在ImageNet-1K-val和ImageNet-1K-ReaL上分别达到了82.14%和87.31%的准确率。前者有0.13%的性能下降,而后者则有0.07%的性能提升。考虑到偏差,这些结果表明,我们的方法能够在ImageNet-21K上实现75%的无损压缩比。
4.4 跨架构泛化
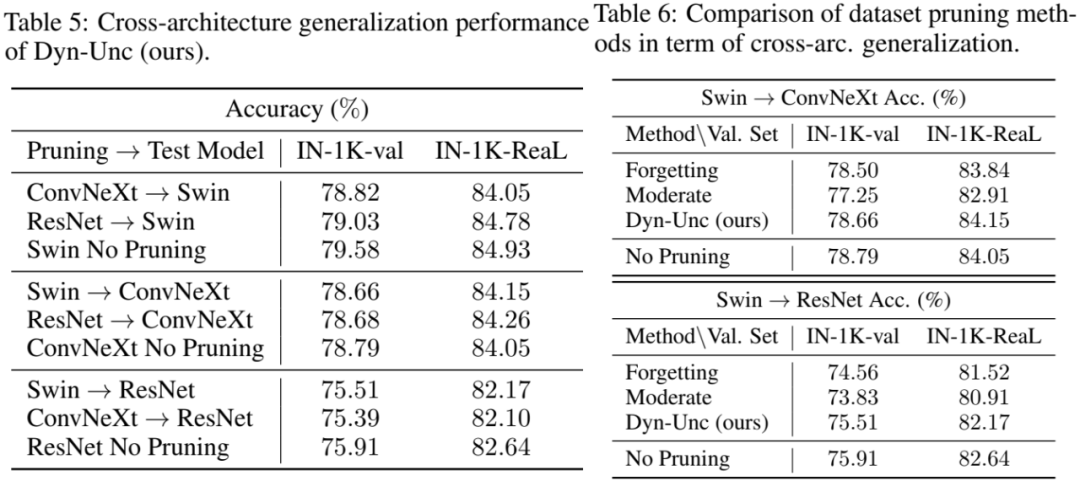
尽管跨架构泛化的性能对于实际应用非常重要(因为新的架构将会被训练),但很少有研究测试裁剪后数据集的这种泛化能力。我们进行了实验,以验证裁剪后的数据集是否能够很好地泛化到那些在数据集裁剪过程中无法访问的未见过的架构。这里考虑了具有代表性的架构,即Swin-T、ConvNeXt-T和ResNet-50。由一种架构裁剪的数据集用于训练其他架构。我们在25%的裁剪比例下进行实验。我们使用批次大小为2048、初始学习率为0.002来训练ConvNeXt-T。其余超参数与训练Swin-T时相同。对于训练ResNet-50,我们采用SGD优化器进行90个epoch的训练,使用步长衰减策略,批次大小为2048,初始学习率为0.8,权重衰减为。
表5中的结果显示,通过我们方法裁剪的数据集对未见过的架构具有良好的泛化能力。例如,使用Swin-T裁剪ImageNet-1K,然后训练ConvNeXt-T和ResNet-50,相比分别在完整数据集上训练这两个架构,仅导致在ImageNet-1K-val上的性能下降分别为0.13%和0.4%。值得注意的是,使用Swin-T或ResNet-50裁剪后,当训练的模型在ImageNet-1K-ReaL上进行验证时,其性能超过了整个数据集训练的ConvNeXt-T。这是合理的,因为适当比例的数据集裁剪可以移除噪声和信息较少的数据,从而提高数据集的质量。
我们进一步将我们的方法与“遗忘”(Forgetting)和“适度”(Moderate)方法在使用Swin-T裁剪ImageNet-1K并随后用其他架构测试的跨架构实验中进行了比较。如表6所示,虽然我们的方法略逊于不裁剪的上限,但显著超过了其他方法。特别是,当使用ResNet-50在ImageNet-1K-val上进行测试时,我们的方法分别超过了“遗忘”和“适度”方法0.95%和1.68%。这些有希望的结果表明,我们的方法在未见过的架构上具有良好的泛化能力,并且裁剪后的数据集可以应用于下游任务架构未知的实际场景中。
4.5 异分布检测
为了进一步验证我们方法的鲁棒性和可靠性,我们在ImageNet-O上评估了我们的方法,这是一个设计用于评估在ImageNet上训练模型的异分布检测数据集。ImageNet-O包含了ImageNet-1K中不存在但在ImageNet-21K中存在的类别的图像。ImageNet-O收集了那些可能被在ImageNet-1K上训练的模型高置信度错误分类的图像。因此,该数据集可以用来测试模型的鲁棒性和可靠性。我们使用AUPR(精度-召回曲线下的面积)指标,更高的AUPR意味着更好的OOD检测器。对于ImageNet-O,随机机会水平的AUPR大约为16.67%,而最大值为100%。
基于上述ImageNet-1K实验中训练的模型,我们在表4中报告了OOD检测的结果。有趣的是,我们的数据集裁剪方法可以略微提升OOD检测性能,从21.98%(无裁剪)提高到22.61%(裁剪30%样本)。可能的原因是数据集裁剪防止了模型过度拟合许多简单和噪声样本,从而提高了模型的泛化能力。
5 结论
在本文中,我们首次将数据集裁剪的研究推进到了大型数据集,即ImageNet-1K/21K,以及先进的模型,即Swin Transformer和ConvNeXt。我们提出了一种基于预测不确定性和训练动态的简单而有效的数据集裁剪方法。广泛的实验证明,与现有技术相比,我们的方法在所有设置下均取得了最佳结果。值得注意的是,我们的方法在ImageNet-1K和ImageNet-21K上均实现了75%的无损压缩比。跨架构泛化和异分布检测实验展示了有前景的结果,为实际应用铺平了道路。

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









