






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Marina Vinyes
编译:ronghuaiyang
包括计算机视觉,自然语言处理,图计算,可扩展性,对抗学习,学习表征和元学习。
ICLR 2019在新奥尔良举行,以多样性的演讲开场。该组织确保在项目团队、受邀演讲者和会议主席中实现100%的性别平等。社区面临的主要挑战是性别、种族、地理多样性以及对LGBT+的支持。为支持地理多样性,ICLR 2020将在埃塞俄比亚首都Addis Abeba举行。这将是非洲第一次大型机器学习会议。

在海报和演讲中,主题广泛,下面是一个(非详尽的)列表。

计算机视觉
计算机视觉仍然是深度学习的主要课题之一,在ICLR中得到了很好的体现。另一个非常重要的话题是图像生成。它有很多用途:艺术、生成数据集来学习另一个任务或对抗样本。
要克服的主要困难是生成的多样性(不仅仅是复制输入数据集)和一致性(正确的腿数,保持对称性,……)
生成图像的方法有几种,其中最流行的一种是GAN。Large Scale GAN Training for High Fidelity Natural Image Synthesis介绍了大规模GAN生成高维图像的方法。GANs的训练既困难又昂贵,因此本文解释了怎样的调优工作能有效果:使用大量资源(500 TPU)、调整ResNet体系结构(更多的层和更少的参数)、改变采样分布(Bernoulli和ReLU而不是N(0,1))、对解码器进行正则化。结果真的是很好看:

另一种生成图像的方法是自回归网络。Generating High Fidelity Images with Subscale Pixel Networks and Multidimensional Upscaling是一个自回归网络,引入了一些新的数据变换:尺寸的子尺度、深度的子尺度、切片。它背后的直觉是,生成小图像比生成大图像更容易。它在CelebAHQ上进行了评估,并产生了最先进的结果:

计算机视觉的主要基准仍然是ImageNet上的物体分类。 ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness证明了所有CNN架构都偏向于纹理。CNN通常的解释是,前几层识别小的形状,然后后面的层开始识别图像中最大的形状,如眼睛、嘴巴和腿,等等。
作者使用style transfer (style GAN模型),将一个类别的纹理放到另一个类别的图像上。该模型将图像标识为其纹理的类别,而不是原始类别。通过绘制这种偏差,作者发现人类偏向于形状,而CNN偏向于纹理。

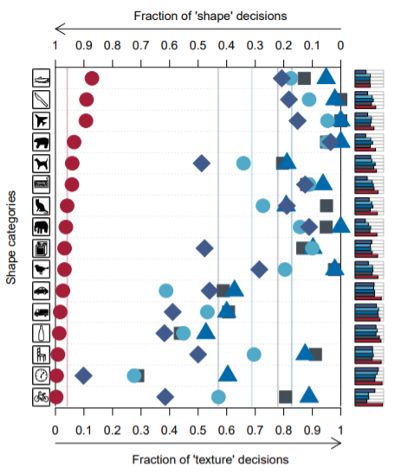
为了消除纹理偏差,他们在一个风格化的图像网络(带有随机纹理)上训练CNN。基本消除了纹理偏置,提高了整体效果。
自然语言处理
NLP的一个重要任务是语义解析:从文本转换到语义语言(SQL、逻辑形式……)。受邀演讲者Mirella Lapata在Learning Natural Language Interfaces with Neural Models第四天的第一次演讲中谈到了这一点。她引入了一个模型,可以将自然语言转换成任何语义语言。为此,我们结合了几个想法:一个seq2tree架构来处理语义语言的树结构,一个2阶段架构先转换为语义草图,然后在目标语言和训练中对问题进行释义,以提高覆盖率。结果是有希望的,达到了许多任务的最先进水平。端到端可训练方法非常有意思,因为它避免了NLP中常见的错误在多个模块中积累的问题。
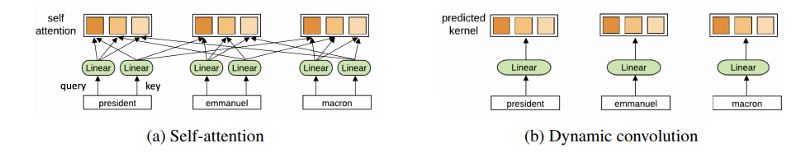
那天的第二个话题是关于将成功的CNN架构应用于NLP:它通常不能达到最先进的水平,因为它不能处理像RNN这样的语言结构,而基于注意力的方法可以。 Pay Less Attention with Lightweight and Dynamic Convolutions介绍了一种CNN的变体,它可以达到最先进的性能:动态卷积。通过对4个不同数据集的测试,证明了该思想可以应用于各种问题。他们还证明,对于自注意力模型,减小上下文的大小并不会显著降低性能,但是会减少计算时间,这就是动态卷积的直觉:更少的注意力就足够了。
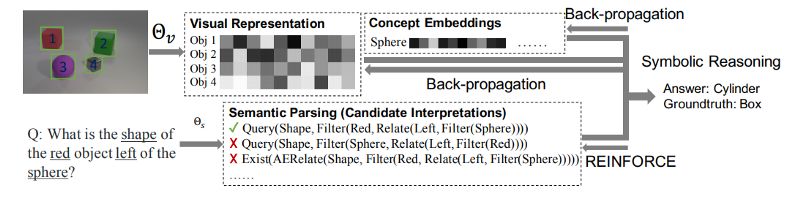
除了改进传统的NLP任务和新的体系结构外,一些新的任务得到了更广泛的应用,其中包括需要与计算机视觉交互的任务。 The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision提出了一种从图像和文本中自动学习概念的模型。介绍了一种结合语义分析、可视化分析和符号推理的体系结构(NSCL)。它发现,使用生成的概念可以更容易地解析新句子:用更少的训练数据就可以达到最先进的水平。视觉答题(即对图像的答题)是本模型评价的任务之一。
图计算
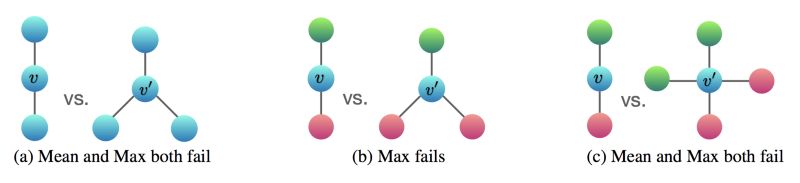
图神经网络(GNN)主要用于解决节点分类或图分类等任务。在理论论文How Powerful are Graph Neural Networks?中,作者识别出了不能被流行的GNN变体所区分的图结构,比如GCN和GraphSAGE。他们表明,最强大的GNN与Weisfeiler-Lehman图同构检验(Weisfeiler and Lehman, 1968)一样强大,并提出了一个达到上界的架构。其思想是,当使用的聚合函数是单射函数时(单射函数的一个例子是SUM—而不是MEAN或MAX),就可以达到上限。
在另一个的工作,有一个有趣的论文Learning the Structure of Large Graphs。使用近似最近邻法,对于样本数量为n的时候,他们的计算代价为O(nlog(n)),在实验中,他们让节点数量扩大到了100(使用Matlab实现)。
对抗学习
Ian Goodfellow在 Adversarial Machine Learning上发表了演讲。GAN生成的图像质量从2014年开始有了非常快的提高,但是得到的图像分辨率较低,需要进一步的超尺度,到了2019年,图像的分辨率开始变得非常高。近年来,出现了一些新技术,比如风格转换,它可以生成在有监督的上下文中不可能生成的图像。

通过消除一种偏见,对抗样本有助于改进机器学习模型。GANs的用途之一是能够在模拟环境中使用看起来像真实世界的数据来训练增强学习算法。
自我对弈也是对抗性学习的一部分:它可以让AlphaGo这样的算法通过与自己对弈40天,从头开始学习围棋。
学习表征
这是今年的热门话题。受邀的演讲者Leon Bottou谈到了使用因果不变性学习表征以及他和他的团队一直在研究的新想法。因果关系是机器学习中的一个重要挑战,因为算法擅长发现相关性,但很难找到因果关系。问题是,算法可能会学习我们不希望在未来用例中存在的伪相关性。消除虚假关联的一种方法是使用多个上下文特定的数据集,而不是一个大的合并数据集。

改进表示的一个关键贡献是Deep InfoMax,该原则在会议的其他一些文件中也得到了应用。其思想是通过最小化深度神经网络编码器的输入和输出之间的相互信息来学习良好的表示。为了做到这一点,他们在联合分布(即(特征、表示)这样的一对数据)的正样本和边际积分布(不和特征对应的(特征、表示)对数据)的负样本上训练一个判别器。
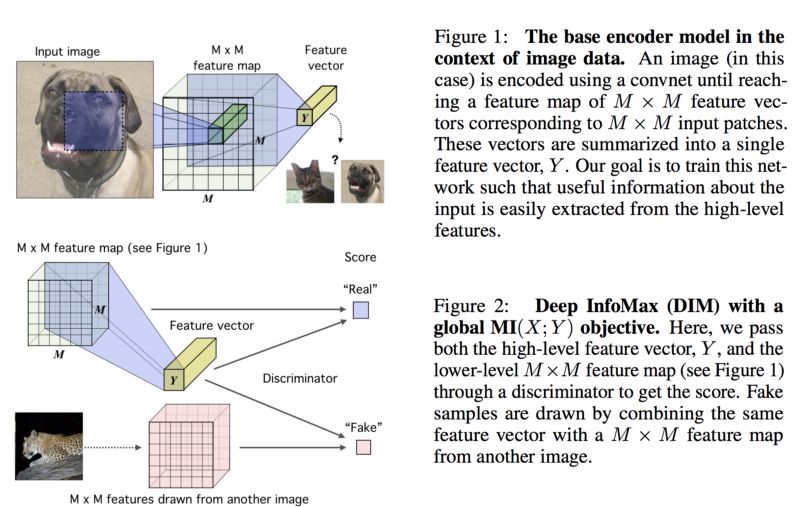
一篇有趣的论文是Smoothing the Geometry of Probabilistic BoxEmbeddings,这篇文章达到了学习能够捕获层次结构和部分排序的受几何启发的嵌入的最新水平。
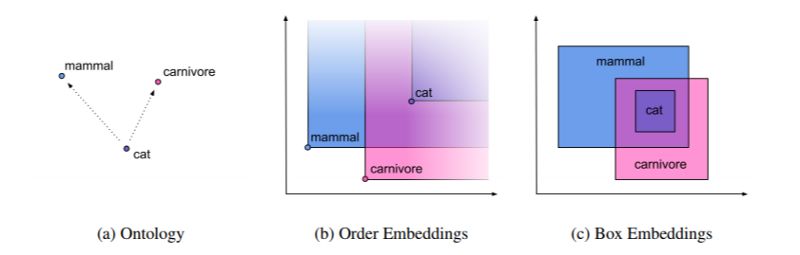
本文背后的直觉是,标准框嵌入的“硬边”导致了不必要的梯度稀疏性。这个想法是使用一个平滑的指标函数的盒子作为松弛的“硬边”。
元学习
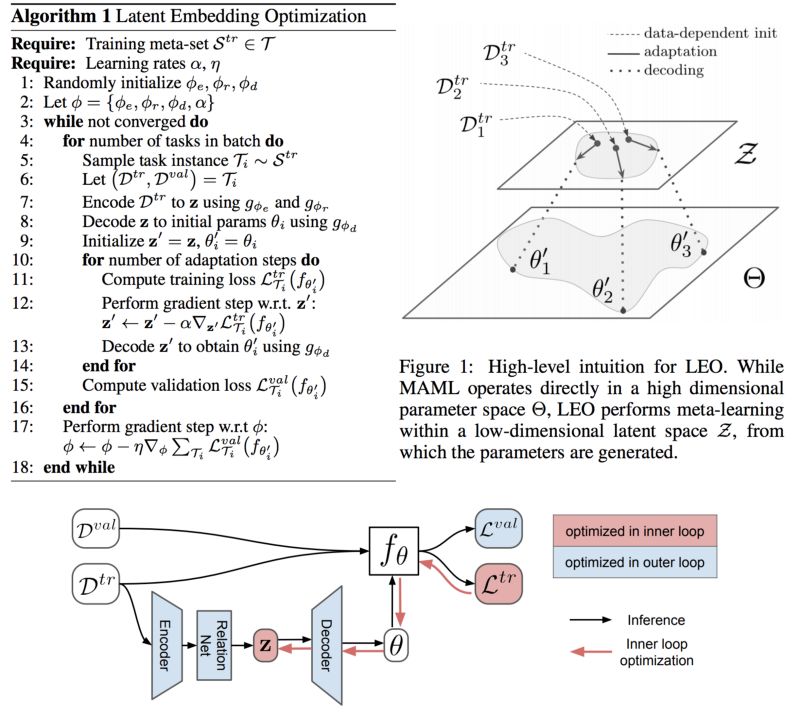
元学习也叫做learning to learn,学习的理念就是学习的过程。关于这个主题的一篇很好的论文是Meta-Learning With potential Optimization,与MAML(该领域的参考论文)相比,作者在分层ImageNet和微型ImageNet数据集上都取得了很好的实验结果。其主要思想是将模型参数映射到低维空间(即已学习的空间)中,然后在该空间上执行元学习。
 —
END—
—
END—
英文原文:https://medium.com/criteo-labs/highlights-of-iclr-2019-c7538cd3585f

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()














 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









