









一、Abstract
提出一种新的autoencoder —- SWWAE(stacked what-where auto-encoders),更准确的说是一种 convolutional autoencoder,因为在CNN中的pooling处才有 “what-where。SWWAE呢,是一种整合了supervised,semi-supervised and unsupervised learning 的model(暂时不理解这是什么意思,感觉好厉害的样子## 标题 ##,先记着)。what-where最根本的作用是在decode中uppooling时,把value放到指定位置(encode时对应的pool层所记录的位置,即where),看图吧,一图胜千言
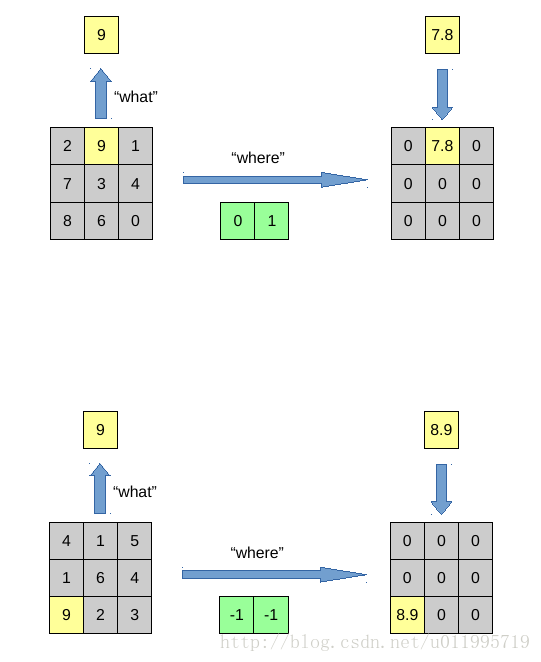
第一幅图说明了pooling 和unpooling的一一对应关系,以及what-where
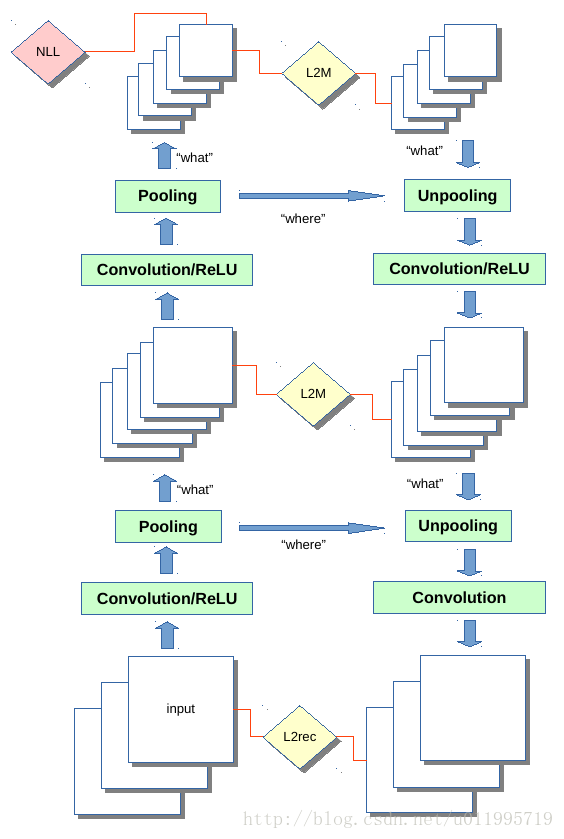
第二幅图就是整个SWWAE的示意图
添加what-where的好处就是
SWWAE适用于 大量无标签数据+小量标签数据的情况
二、Key words:
SWWAE; reconstruction;encoder;decoder
三、Motivation
1.想整合平衡(leverage)labeled and unlabeled data 来学习更好的feature(representation)
四、main contributions
1.提供了一种可以 unified supervised,semi-supervised and unsupervised learning的model
2.提供一个当无标签样本多,有标签样本少时的一种训练模型(1 )
3.unsupervised learning 会学习一些 trivial representation ,加入 supervised loss 可以避免(3.2)
五、inspired by
- Yann LeCun, L ́ eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Matthew D Zeiler, Dilip Krishnan, Graham W Taylor, and Robert Fergus. Deconvolutional networks. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pp. 2528–2535. IEEE, 2010.
- Tom Le Paine, Pooya Khorrami, Wei Han, and Thomas S Huang. An analysis of unsupervised pre-training in light of recent advances. arXiv preprint arXiv:1412.6597, 2014.
key word:CNN; Deconvolutional network;regularization effect !
六、文献具体实验及结果
4.1 对比 upsampling(what but no where) andunpooling(what-where),实验证明 在 reconstruction过程中,“where”是很重要的七、 自己的感悟
4.2 实验没看明白,搞不懂 invariance and equivariance是什么鬼,留着以后看
4.3提高分类性能,说提高了MNIST,SVHN的分类性能
七、 自己的感悟
loss function = classification loss + reconstructions loss + middle reconstruction loss
总共三部分loss,第一部分loss就是我们平时supervised learning中常见的。而后面两个reconstruction loss 其实就是重构误差,即decode 与 code 之间的误差,这两部分loss相当于一个regularizer,对encoder阶段中的weights做了regularization,迫使weights可以使得提出的特征能通过decoder还原成原信号(图片)针对reconstruction 可以看作一个 regularizer,
2010年 Erhan就提到,但是证明不足以让人信服;
2014年 Paine分析regularization effect,可以追一追,看看是什么结构(e.g deconvnet?)提供了一个loss,这个loss对weights的更新起到某种限制,从而使得提取出的feature更好,这个可以作为一个研究方向按道理作者提出 where,应该开门见山就说 有了where的模型会怎么怎么样才对啊,但是从头一直找啊找,直到实验4.1,丢出图,给出结论,where 对reconstruction很重要,会更清晰。。。这种做法感觉怪怪的
可以追的paper 2014 Paine分析 regularization effect ;
deconvnet 及其 loss 方面,Matthew D Zeiler 大神的系列文章,一开始认识他是2013反卷积 Iamgenet2013冠军!














 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









