






"如果说大语言模型是AI的大脑,那么Agent Framework就是让这些大脑能够思考、决策并行动的神经系统。"
写在前面的话
你有没有想过,为什么ChatGPT能聊天却不能帮你订机票?为什么AI能写代码却无法自动查询你公司的内部文档?答案很简单:它们缺少"手脚"和"工具箱"。
就像一个聪明的大脑如果被关在真空里,再聪明也无济于事。AI Agents(智能体)的出现,正是为了打破这个困境。它们不仅能思考,还能调用工具、检索知识、协同工作——这才是真正的"智能"。
今天,我要带你深入探索的,就是微软推出的Microsoft Agent Framework。这个框架集成了Semantic Kernel和AutoGen的精华,提供了一套完整的、生产级的智能体开发方案。更重要的是,它支持Python和.NET双语言实现,无论你是数据科学家还是企业开发者,都能找到归属感。
在接下来的8000多字里,我会用最接地气的方式,带你从"什么是智能体"聊到"如何编排智能体军团",从简单的旅行规划助手到复杂的多智能体协作系统。我保证,读完这篇文章,你不仅能理解智能体的核心思想,还能动手搭建出自己的第一个AI应用。
准备好了吗?让我们开始这场智能体的冒险之旅。
一、重新认识AI Agents:不只是聊天机器人
1.1 什么是AI Agent?
我们先做个类比。想象一下,你雇了一个助理来帮你规划旅行。
-
传统聊天机器人:你问"巴黎有什么好玩的?",它会滔滔不绝地告诉你埃菲尔铁塔、卢浮宫的历史。但如果你说"帮我订一张去巴黎的机票",它就傻眼了——"抱歉,我只能聊天,不能操作。"
-
AI Agent:同样的问题,它不仅能告诉你景点,还能主动调用航班查询工具、比价工具,给出完整的行程方案,甚至直接帮你完成预订。它有规划能力(分解任务)、执行能力(调用工具)和记忆能力(记住你的偏好)。
这就是Agent和普通LLM的本质区别:Agent是目标驱动的自主系统,而聊天机器人只是被动的问答接口。
用技术语言描述,一个AI Agent由三个核心组件构成:
-
LLM(大语言模型) - 推理引擎,负责理解、规划和决策
-
Tools(工具) - 执行器,可以是API调用、数据库查询、文件操作等
-
Memory(记忆) - 上下文管理,包括短期对话历史和长期知识库
Microsoft Agent Framework把这三个要素优雅地整合在一起,让开发者能够像搭积木一样构建智能体。
1.2 为什么需要Agent Framework?
你可能会想:"我直接调用OpenAI API,自己写代码处理工具调用不行吗?"当然可以,但这就像你用汇编语言写网页——理论上可行,实际上痛苦不堪。
Agent Framework解决的核心问题包括:
-
工具调用的标准化:统一的函数签名、参数验证、错误处理机制
-
状态管理的复杂性:如何在多轮对话中保持上下文?如何管理多个Agent的协作状态?
-
可观测性:当Agent出错时,如何追踪它的"思考过程"和工具调用链路?
-
生产级部署:如何处理并发、如何做性能监控、如何确保安全性?
Microsoft Agent Framework不仅提供了这些能力,还做到了跨平台统一(Python/.NET)、多模型兼容(Azure OpenAI/GitHub Models/本地模型)、企业级安全(身份认证、权限管理)。
二、九大核心能力全景图:从入门到精通的完整路径
Microsoft Agent Framework的学习曲线设计得很巧妙,从最简单的单Agent应用到复杂的多智能体编排,循序渐进。让我们先鸟瞰一下全景:
| 能力模块 | 核心价值 | 典型场景 | 技术难度 |
|---|---|---|---|
| 01. Agent基础 | 理解Agent架构 | 单轮问答、简单助手 | ⭐ |
| 02. 创建首个Agent | 快速上手开发 | 旅行规划助手 | ⭐ |
| 03. 多Provider连接 | 灵活切换模型 | 测试不同模型效果 | ⭐⭐ |
| 04. 工具集成 | 扩展Agent能力 | 视觉分析、代码执行 | ⭐⭐⭐ |
| 05. MCP协议 | 标准化外部连接 | 接入企业知识库 | ⭐⭐⭐ |
| 06. RAG检索增强 | 知识注入 | 文档问答、专业领域助手 | ⭐⭐⭐ |
| 07. Workflow编排 | 流程自动化 | 多步骤业务流程 | ⭐⭐⭐⭐ |
| 08. 多智能体协作 | 复杂任务分解 | 内容创作流水线 | ⭐⭐⭐⭐⭐ |
| 09. 评估与追踪 | 可观测性 | 性能优化、问题定位 | ⭐⭐⭐ |
接下来,我会逐一深入每个模块,不仅讲"是什么"和"怎么做",更会解释"为什么这样设计"以及"在实际项目中如何应用"。
三、动手实战:从Hello World到生产应用
3.1 第一课:搭建你的AI旅行助手(Agent基础)
场景设定
假如现在是周五晚上,你突然想来一场说走就走的周末旅行,但不知道去哪儿。这时候,一个能够随机推荐目的地并生成详细行程的AI助手就派上用场了。
核心思路
我们要给Agent配备一个"随机目的地生成器"工具,然后让它:
-
调用工具获取一个随机城市
-
基于这个城市生成一日游行程
这个简单的例子涵盖了Agent开发的三个核心环节:定义工具 → 创建Agent → 执行任务。
Python实现(5分钟上手)
import os
from random import randint
from dotenv import load_dotenv
from agent_framework import ChatAgent
from agent_framework.openai import OpenAIChatClient
# 第一步:加载配置(使用GitHub Models)
load_dotenv()
# 第二步:定义工具 - 随机目的地生成器
def get_random_destination() -> str:
"""从全球热门旅行目的地中随机选择一个"""
destinations = [
"巴黎, 法国", "东京, 日本", "纽约, 美国",
"悉尼, 澳大利亚", "罗马, 意大利", "巴塞罗那, 西班牙",
"开普敦, 南非", "里约热内卢, 巴西",
"曼谷, 泰国", "温哥华, 加拿大"
]
return destinations[randint(0, len(destinations) - 1)]
# 第三步:创建AI Client和Agent
openai_chat_client = OpenAIChatClient(
base_url=os.environ.get("GITHUB_ENDPOINT"),
api_key=os.environ.get("GITHUB_TOKEN"),
ai_model_id=os.environ.get("GITHUB_MODEL_ID")
)
agent = ChatAgent(
chat_client=openai_chat_client,
instructions="""你是一个专业的旅行规划助手。
当用户请求旅行建议时,先使用get_random_destination工具选择目的地,
然后生成包含早中晚行程、美食推荐和注意事项的详细攻略。""",
tools=[get_random_destination] # 注册工具
)
# 第四步:运行Agent
response = await agent.run("给我规划一个一日游吧!")
print(response.messages[-1].contents[0].text)
运行结果示例:
好的!我为你选择了目的地:东京, 日本
🌅 **早晨(8:00-11:00)**
- 筑地市场:品尝新鲜的金枪鱼寿司早餐
- 浅草寺:感受江户时代的古朴气息,别忘了在仲见世商店街买伴手礼
🌞 **中午(11:00-14:00)**
- 午餐推荐:一兰拉面或回转寿司
- 明治神宫:在都市中心体验宁静的神社文化
🌆 **下午(14:00-18:00)**
- 原宿竹下通:逛街购物,体验日本年轻人文化
- 涩谷十字路口:打卡全球最繁忙的十字路口
🌃 **晚上(18:00-21:00)**
- 台场海滨公园:观赏东京湾夜景
- 晚餐推荐:居酒屋体验地道日式料理
💡 **旅行贴士:**
- 购买地铁一日券(800日元)
- 下载Google Maps和Suica卡应用
- 备注:很多小店只收现金,记得提前换汇
代码解析:三个关键设计
1. 工具函数的Docstring是关键
def get_random_destination() -> str:
"""从全球热门旅行目的地中随机选择一个""" # ← 这行描述会被AI读取
LLM通过这个docstring理解工具的用途,这就是为什么要写清晰的函数说明。在.NET版本中,对应的是[Description]特性。
2. Agent的instructions是"人格设定"
instructions="""你是一个专业的旅行规划助手。
当用户请求旅行建议时,先使用get_random_destination工具选择目的地,
然后生成包含早中晚行程、美食推荐和注意事项的详细攻略。"""
这段话定义了Agent的:
-
角色定位(旅行规划助手)
-
工作流程(先选目的地,再做规划)
-
输出标准(包含哪些内容)
好的instructions能让Agent表现得更加专业和可控。
3. 异步执行是标配
response = await agent.run("给我规划一个一日游吧!")
为什么用await?因为Agent内部可能会:
-
多次调用LLM(第一次决策调用工具,第二次生成最终答案)
-
执行耗时的工具函数(如网络请求)
异步设计确保应用不会阻塞,这在生产环境中至关重要。
.NET版本对比
如果你更熟悉C#,同样的功能只需几行代码:
// 定义工具(注意[Description]特性)
[Description("从全球热门旅行目的地中随机选择一个")]
static string GetRandomDestination()
{
var destinations = new List<string> {
"巴黎, 法国", "东京, 日本", "纽约, 美国", /* ... */
};
return destinations[new Random().Next(destinations.Count)];
}
// 创建Agent并执行
var openAIClient = new OpenAIClient(
new ApiKeyCredential(github_token),
new OpenAIClientOptions { Endpoint = new Uri(github_endpoint) }
);
AIAgent agent = openAIClient
.GetChatClient(github_model_id)
.CreateAIAgent(
instructions: "你是一个专业的旅行规划助手...",
tools: [AIFunctionFactory.Create((Func<string>)GetRandomDestination)]
);
Console.WriteLine(await agent.RunAsync("给我规划一个一日游吧!"));
Python和.NET的API设计高度一致,这正是Microsoft Agent Framework的优雅之处——Write Once, Think Everywhere。
3.2 第二课:多Provider灵活切换(Provider连接)
为什么需要多Provider支持?
现实世界中,你可能需要:
-
开发阶段:用GitHub Models的免费额度快速测试
-
生产环境:切换到Azure OpenAI保证稳定性和数据隐私
-
本地调试:使用Foundry Local在无网络环境下开发
-
性能对比:同时测试GPT-4和Claude的效果差异
如果每种模型都要重写代码,那就太痛苦了。Agent Framework提供了统一的抽象层,让你只需改几行配置就能切换Provider。
四大Provider对比
| Provider | 适用场景 | 优势 | 配置复杂度 |
|---|---|---|---|
| GitHub Models | 快速原型开发 | 免费、易用、模型更新快 | ⭐ |
| Azure OpenAI | 企业生产环境 | 数据隐私、SLA保障、企业支持 | ⭐⭐⭐ |
| Azure AI Foundry | 托管Agent服务 | 状态管理、工具市场、可视化 | ⭐⭐⭐⭐ |
| Foundry Local | 离线开发/边缘部署 | 无需网络、低延迟、数据不出域 | ⭐⭐ |
实战演练:一键切换Provider
**场景:**你写了一个Agent,想分别用GitHub Models和Azure OpenAI测试效果。
import os
from dotenv import load_dotenv
from agent_framework import ChatAgent, ChatMessage, Role
load_dotenv()
# ========== Provider 1: GitHub Models ==========
from agent_framework.openai import OpenAIChatClient
github_client = OpenAIChatClient(
base_url=os.environ.get("GITHUB_ENDPOINT"),
api_key=os.environ.get("GITHUB_TOKEN"),
ai_model_id="gpt-4o-mini"
)
agent_github = ChatAgent(
chat_client=github_client,
instructions="你是一个有趣的AI助手,用幽默的方式回答问题"
)
# ========== Provider 2: Azure OpenAI ==========
from azure.identity import AzureCliCredential
from agent_framework.azure import AzureOpenAIChatClient
azure_client = AzureOpenAIChatClient(
credential=AzureCliCredential() # 自动使用Azure CLI凭证
)
agent_azure = azure_client.create_agent(
instructions="你是一个有趣的AI助手,用幽默的方式回答问题"
)
# 测试对比
query = "用一句话解释什么是Agent Framework"
print("GitHub Models回答:")
result1 = await agent_github.run(query)
print(result1.messages[-1].contents[0].text)
print("\nAzure OpenAI回答:")
result2 = await agent_azure.run(query)
print(result2)
运行结果对比:
GitHub Models回答:
Agent Framework就是给AI装上"瑞士军刀"的工具箱,让它不仅能聊天,还能干活儿——查资料、调API、做决策,简直是AI界的全能管家!
Azure OpenAI回答:
Agent Framework相当于给大语言模型配了一套"装备系统",让原本只会纸上谈兵的AI学会了真刀真枪地办事!
关键设计:统一的Agent接口
无论你用哪个Provider,核心的agent.run()方法都是一样的。这背后是面向接口编程的设计哲学:
# 所有Provider的Agent都实现相同的接口
class ChatAgent(Protocol):
async def run(self, message) -> AgentRunResponse: ...
async def run_stream(self, message) -> AsyncIterator[Event]: ...
这意味着你可以轻松实现:
-
多Provider A/B测试:同时调用两个模型,对比结果
-
智能降级:主Provider失败时自动切换到备用Provider
-
成本优化:简单问题用便宜的模型,复杂问题用强模型
3.3 第三课:工具集成的艺术(Tools能力扩展)
Agent的"技能树"系统
如果说LLM是Agent的大脑,那么工具就是它的各种技能。Microsoft Agent Framework提供了四大类内置工具:
-
Vision(视觉) - 让Agent能"看懂"图片
-
Code Interpreter(代码执行) - 让Agent能写代码并运行
-
Bing Grounding(网络搜索) - 让Agent能实时获取互联网信息
-
File Search(文件检索) - 让Agent能在文档库中查找答案
实战案例:家具销售顾问Agent
**场景:**用户上传一张客厅照片,Agent需要:
-
识别照片中的家具
-
给出每件家具的参考价格
-
提供购买建议
这个任务需要Vision工具。
from agent_framework.azure import AzureAIAgentClient
from agent_framework import ChatMessage, DataContent, TextContent, Role
from azure.identity.aio import AzureCliCredential
import base64
# 读取图片并转换为base64
with open("living_room.png", "rb") as image_file:
image_b64 = base64.b64encode(image_file.read()).decode()
image_uri = f"data:image/png;base64,{image_b64}"
async with (
AzureCliCredential() as credential,
AzureAIAgentClient(async_credential=credential) as client,
):
# 创建支持视觉的Agent(使用gpt-4o模型)
agent = client.create_agent(
name="家具销售顾问",
instructions="""你是一位专业的家具销售顾问。
当用户上传客厅图片时,你需要:
1. 识别图中所有家具(沙发、茶几、电视柜等)
2. 估算每件家具的参考价格(列出低/中/高三档)
3. 根据整体风格给出搭配建议
"""
)
# 构造包含图片的消息
message = ChatMessage(
role=Role.USER,
contents=[
TextContent(text="请帮我分析这个客厅,给出家具清单和报价"),
DataContent(uri=image_uri, media_type="image/png")
]
)
result = await agent.run(message)
print(result.text)
输出示例:
根据您上传的客厅照片,我识别到以下家具:
📋 **家具清单及报价**
1. **L型布艺沙发**(灰色,约3.5米)
- 经济型: ¥3,500-5,000
- 中档: ¥8,000-12,000
- 高端: ¥15,000-25,000
2. **大理石茶几**(圆形,直径约1.2米)
- 经济型: ¥1,200-2,000
- 中档: ¥3,500-6,000
- 高端: ¥8,000-15,000
3. **电视柜**(白色烤漆,约2米长)
- 经济型: ¥800-1,500
- 中档: ¥2,500-4,000
- 高端: ¥5,000-8,000
4. **落地灯**(金属支架+布艺灯罩)
- 经济型: ¥200-400
- 中档: ¥600-1,200
- 高端: ¥1,500-3,000
💡 **搭配建议:**
您的客厅整体风格偏现代简约,色调以灰白为主。建议:
- 增加一些暖色调抱枕(橙色/黄色)增加温馨感
- 墙面可以挂一幅抽象装饰画呼应茶几的现代感
- 考虑增加一个边柜用于收纳,保持空间整洁
💰 **预算参考:**
- 经济型全套: ¥5,700-8,900
- 中档全套: ¥14,600-23,200
- 高端全套: ¥29,500-51,000
工具的自动路由:Agent怎么知道该用哪个工具?
你可能好奇:我们没有显式告诉Agent"遇到图片就用Vision工具",它是怎么知道的?
答案是:Function Calling机制。当你给Agent注册工具时,实际上发生了这些事:
-
工具描述注册:每个工具都有schema描述(参数类型、功能说明)
-
智能路由:Agent把用户请求和所有工具描述一起发给LLM
-
决策过程:LLM分析后返回"我需要调用Vision工具,参数是这张图片"
-
执行反馈:Framework执行工具,把结果再交给LLM生成最终答案
这个过程是自动化的,你只需要提供好的instructions帮助Agent理解何时使用工具。
Code Interpreter:让Agent变身程序员
再看一个更炫酷的工具——让Agent写代码并执行。
**场景:**用户想知道斐波那契数列中小于101的所有数字。
from agent_framework import HostedCodeInterpreterTool
agent = client.create_agent(
name="数学助手",
instructions="你是一个数学计算助手,擅长用Python解决数学问题",
tools=HostedCodeInterpreterTool(), # 启用代码执行能力
)
result = await agent.run(
"用代码计算斐波那契数列中小于101的所有值"
)
print(result.text)
Agent的执行过程(内部自动完成):
1. [Agent思考] 这是一个编程问题,我需要写Python代码
2. [调用工具] 执行以下代码:
```python
def fibonacci(limit):
fib = [0, 1]
while fib[-1] + fib[-2] < limit:
fib.append(fib[-1] + fib[-2])
return fib
result = fibonacci(101)
print(result)
-
[工具返回] [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
-
[Agent响应] 斐波那契数列中小于101的数字有: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89
这个能力在数据分析、科学计算场景下特别实用——你可以用自然语言描述需求,Agent自动生成和运行代码,无需你手写一行代码!
---
### 3.4 第四课:知识检索的魔法(RAG能力)
#### RAG是什么?为什么需要它?
想象你要开发一个企业内部的技术支持Agent,它需要回答关于公司产品的问题。但问题来了:
- GPT-4的训练数据截止到2023年,不知道你2024年发布的新产品
- 即使知道,它也不了解你公司的内部文档、配置手册、故障排查流程
这时候就需要**RAG(Retrieval-Augmented Generation,检索增强生成)**:
1. 把公司文档导入向量数据库
2. 用户提问时,先从文档库检索相关片段
3. 把检索到的内容和问题一起给LLM
4. LLM基于真实文档生成答案
**关键优势:**
- ✅ 知识实时更新(改文档就行,不用重新训练模型)
- ✅ 答案可溯源(能告诉用户"这段话来自XX文档第X页")
- ✅ 降低幻觉(有明确依据,不会胡编乱造)
#### 实战:搭建一个GraphRAG知识问答Agent
**场景:**你有一份关于GraphRAG技术的内部文档`demo.md`,想让Agent基于这份文档回答问题。
```python
from azure.ai.agents.models import FilePurpose, VectorStore, FileSearchTool
from agent_framework.azure import AzureAIAgentClient
from azure.identity.aio import AzureCliCredential
# 第一步:创建向量存储并上传文档
async def create_knowledge_base(client: AzureAIAgentClient):
# 上传文件
file = await client.project_client.agents.files.upload_and_poll(
file_path='demo.md',
purpose=FilePurpose.AGENTS
)
print(f"文件已上传,ID: {file.id}")
# 创建向量存储(自动切分文档+向量化)
vector_store = await client.project_client.agents.vector_stores.create_and_poll(
file_ids=[file.id],
name="graphrag_knowledge_base"
)
print(f"向量库已创建,ID: {vector_store.id}")
return vector_store
# 第二步:创建RAG Agent
async with (
AzureCliCredential() as credential,
AzureAIAgentClient(async_credential=credential) as client,
):
vector_store = await create_knowledge_base(client)
# 配置File Search工具
file_search_tool = FileSearchTool(vector_store_ids=[vector_store.id])
agent = client.create_agent(
name="GraphRAG专家",
instructions="""你是一个GraphRAG技术专家。
回答问题时:
1. 必须使用File Search工具在知识库中查找相关内容
2. 回答必须基于查找到的文档,不要自己编造
3. 如果文档中没有相关信息,明确告诉用户"文档中未提及"
4. 引用信息时注明来源
""",
tools=file_search_tool.definitions,
tool_resources=file_search_tool.resources,
)
# 第三步:提问
query = "什么是GraphRAG?它的主要优势是什么?"
result = await agent.run(query)
print(result)
输出示例:
GraphRAG是一种AI驱动的内容解析和检索技术,主要特点包括:
📖 **核心概念**
GraphRAG利用大型语言模型(LLM)解析数据并创建知识图谱。它能够连接大量数据中的信息,回答跨越多个文档或需要主题理解的复杂问题。【来源:demo.md】
🎯 **主要优势**
1. **跨文档推理**:传统关键词搜索只能找到提到特定词的文档,而GraphRAG能理解概念之间的关联
2. **主题式问答**:可以回答"这个领域的主要趋势是什么"这类宏观问题
3. **噪音容忍**:即使数据分散、有噪音或存在错误信息,依然能提取有价值的结论
4. **可解释性**:答案有明确的知识图谱支撑,可以追溯推理路径【来源:demo.md】
⚠️ **使用限制**
需要注意的是,GraphRAG的输出需要由训练有素的领域专家验证和解释,不应在无人监督的情况下直接使用。它更适合处理专业数据集和复杂查询【来源:demo.md】
幕后原理:向量检索的秘密
当用户问"什么是GraphRAG"时,系统实际上做了这些事:
1. [向量化查询]
"什么是GraphRAG" → [0.2, -0.5, 0.8, ..., 0.3] (768维向量)
2. [相似度搜索]
在向量库中找出最相似的文档片段(Top-K检索)
最相关片段(相似度0.92):
"GraphRAG是一种AI驱动的内容解析和检索技术..."
次相关片段(相似度0.85):
"GraphRAG的主要优势包括跨文档推理能力..."
3. [构造增强Prompt]
原始问题 + 检索片段 → 一起发给LLM
"基于以下文档内容回答问题:
[文档片段1]...
[文档片段2]...
问题:什么是GraphRAG?"
4. [生成答案]
LLM基于上下文生成答案,并标注来源
这就是为什么RAG能让Agent具备"阅读理解"能力——它先读文档,再回答。
3.5 第五课:MCP协议的威力(Provider扩展)
MCP是什么?为什么需要它?
前面我们讲的工具(Vision、Code Interpreter)都是Agent Framework内置的。但如果你想让Agent:
-
查询你公司的CRM系统
-
调用你们自研的风控API
-
访问第三方的天气服务
怎么办?难道要为每个外部服务写一个专门的适配器?
MCP(Model Context Protocol,模型上下文协议)就是为了解决这个问题而生的。它定义了一套标准接口,让任何外部服务都能以统一的方式被Agent调用。
类比一下:
-
传统方式:每个电器有不同的插头,你需要各种转换器
-
MCP方式:所有电器都用统一的USB-C接口,一根线走天下
实战:接入Microsoft Learn文档查询
**场景:**你想让Agent能够查询Microsoft Learn上的官方文档来回答问题。
from agent_framework import ChatAgent, MCPStreamableHTTPTool
from agent_framework.azure import AzureAIAgentClient
from azure.identity.aio import AzureCliCredential
# 方式1:临时使用MCP工具
async with (
AzureCliCredential() as credential,
MCPStreamableHTTPTool(
name="Microsoft Learn文档",
url="https://learn.microsoft.com/api/mcp", # MCP服务端点
) as mcp_server,
ChatAgent(
chat_client=AzureAIAgentClient(async_credential=credential),
name="技术文档助手",
instructions="你是微软技术栈专家,善于查找和解释官方文档",
) as agent,
):
query = "什么是Microsoft Semantic Kernel?"
result = await agent.run(query, tools=mcp_server) # 动态传入工具
print(result)
输出示例:
Microsoft Semantic Kernel是一个开源的SDK,旨在帮助开发者将大型语言模型(LLM)集成到他们的应用程序中。根据官方文档:
🧩 **核心功能**
1. **AI编排**:提供统一的接口来调用不同的AI服务(OpenAI、Azure OpenAI、Hugging Face等)
2. **插件系统**:通过插件扩展AI能力,如网络搜索、数据库查询、文件操作
3. **提示工程**:内置提示词模板管理和优化工具
4. **记忆系统**:支持短期和长期记忆,实现有状态的对话
🔗 **与Agent Framework的关系**
Semantic Kernel是Agent Framework的前身之一。Agent Framework整合了SK和AutoGen的优秀特性,提供了更完整的企业级解决方案。
📚 **参考资源**
- 官方文档: https://learn.microsoft.com/semantic-kernel
- GitHub仓库: https://github.com/microsoft/semantic-kernel
**关键点:**注意Agent的回答中引用了官方文档的内容,这是因为MCP工具在后台自动调用了Microsoft Learn的搜索API并返回了结果。
MCP vs 普通工具:有什么不同?
| 特性 | 普通Python函数工具 | MCP工具 |
|---|---|---|
| 定义方式 | 手写函数+Docstring | MCP服务器自动暴露 |
| 发现机制 | 静态注册 | 动态发现(列出所有可用工具) |
| 标准化 | 无统一标准 | 遵循MCP协议规范 |
| 跨语言 | 仅限当前语言 | 可跨语言调用 |
| 适用场景 | 简单内部逻辑 | 企业级外部服务集成 |
.NET版本:企业级应用示例
using ModelContextProtocol.Client;
using Azure.AI.Agents.Persistent;
using Microsoft.Agents.AI;
// 连接到MCP服务器
IMcpClient mcpClient = await McpClientFactory.CreateAsync(
new SseClientTransport(new SseClientTransportOptions {
Endpoint = new Uri("https://learn.microsoft.com/api/mcp")
})
);
// 列出可用工具
IList<McpClientTool> tools = await mcpClient.ListToolsAsync();
Console.WriteLine("可用工具:");
foreach (var tool in tools)
{
Console.WriteLine($" - {tool.Name}: {tool.Description}");
}
// 创建Agent并注册MCP工具
var persistentAgentsClient = new PersistentAgentsClient(
azure_foundry_endpoint,
new AzureCliCredential()
);
MCPToolDefinition mcpTool = new("mslearnmcp", "https://learn.microsoft.com/api/mcp");
mcpTool.AllowedTools.Add("searchmslearn"); // 只允许使用搜索工具
var agent = await persistentAgentsClient.Administration.CreateAgentAsync(
model: "gpt-4o",
name: "MSLearnAgent",
instructions: "你是微软技术栈专家,善于查找和解释官方文档",
tools: [mcpTool]
);
3.6 第六课:Workflow编排的艺术(流程自动化)
从单Agent到多Agent协作
前面的例子都是"单打独斗"——一个Agent完成所有任务。但现实世界的复杂流程往往需要多个专家协作,比如:
-
内容创作流水线:作家Agent写初稿 → 编辑Agent审核 → 排版Agent美化 → 发布Agent上线
-
客户服务流程:接待Agent收集信息 → 技术Agent诊断问题 → 财务Agent处理退款
这就需要Workflow编排能力。Microsoft Agent Framework提供了强大的WorkflowBuilder,支持三种核心模式:
-
Sequential(顺序):任务依次执行,流水线模式
-
Concurrent(并发):任务同时执行,结果汇总
-
Conditional(条件):根据结果选择不同路径
模式1:顺序工作流 - 家具报价流水线
**场景:**用户上传客厅照片,需要生成正式的家具采购报价单。
流程设计:
用户上传图片
↓
[Sales-Agent] 识别家具并生成清单
↓
[Price-Agent] 为每件家具标注价格
↓
[Quote-Agent] 生成正式的Markdown报价单
from agent_framework import WorkflowBuilder, WorkflowEvent
from agent_framework.openai import OpenAIChatClient
# 创建三个专业Agent
sales_agent = chat_client.create_agent(
name="家具销售",
instructions="""你是家具识别专家。
收到图片后,列出所有家具项目(名称、材质、尺寸)。
输出格式: - 家具名称 | 材质 | 尺寸"""
)
price_agent = chat_client.create_agent(
name="价格分析师",
instructions="""你是价格评估专家。
收到家具清单后,为每项标注市场价格(低/中/高三档)。
参考电商平台的真实行情。"""
)
quote_agent = chat_client.create_agent(
name="报价文档生成器",
instructions="""你是商务文档专家。
收到带价格的清单后,生成正式的Markdown格式报价单,包括:
- 封面(客户名称、日期)
- 项目明细表
- 总价汇总
- 服务条款"""
)
# 构建顺序工作流
workflow = (
WorkflowBuilder()
.set_start_executor(sales_agent) # 起点
.add_edge(sales_agent, price_agent) # sales → price
.add_edge(price_agent, quote_agent) # price → quote
.build()
)
# 执行工作流
image_message = ChatMessage(
role=Role.USER,
contents=[
TextContent(text="请为这个客厅生成采购报价单"),
DataContent(uri=image_uri, media_type="image/png")
]
)
result = ''
async for event in workflow.run_stream(image_message):
if isinstance(event, WorkflowEvent):
result += str(event.data)
print(result)
最终输出(Markdown报价单):
# 家具采购报价单
**客户:** 李先生
**日期:** 2024-10-23
**有效期:** 30天
---
## 项目明细
| 序号 | 家具名称 | 材质 | 尺寸 | 经济型 | 中档 | 高端 |
|-----|---------|------|-----|--------|-----|-----|
| 1 | L型布艺沙发 | 棉麻混纺 | 3.5m | ¥3,500 | ¥8,000 | ¥15,000 |
| 2 | 大理石茶几 | 天然大理石 | Φ1.2m | ¥1,200 | ¥3,500 | ¥8,000 |
| 3 | 电视柜 | 白色烤漆 | 2.0m | ¥800 | ¥2,500 | ¥5,000 |
| 4 | 落地灯 | 金属+布艺 | H1.6m | ¥200 | ¥600 | ¥1,500 |
## 价格汇总
- **经济型套餐:** ¥5,700
- **中档套餐:** ¥14,600
- **高端套餐:** ¥29,500
## 服务条款
1. 免费上门测量及安装
2. 质保期:2年
3. 支持7天无理由退换
4. 分期付款:支持3/6/12期免息
---
*本报价单由AI智能生成,最终价格以实物为准*
模式2:并发工作流 - 旅行规划加速器
**场景:**用户想去西雅图旅行,需要同时获取攻略研究和行程规划,而不是等一个做完再做另一个。
流程设计:
用户请求
/ \
[Researcher] [Planner]
(研究攻略) (制定行程)
\ /
结果汇总
from agent_framework import ConcurrentBuilder
research_agent = chat_client.create_agent(
name="旅行研究员",
instructions="""你是旅行信息研究专家。
研究目的地的:
- 天气情况(最适合的季节)
- 热门景点及特色
- 美食推荐
- 注意事项(签证、安全、禁忌)"""
)
plan_agent = chat_client.create_agent(
name="行程规划师",
instructions="""你是行程规划专家。
制定详细的7日游计划:
- 每日行程安排(景点+餐饮)
- 交通方案
- 预算估算"""
)
# 构建并发工作流(框架自动处理fan-out/fan-in)
workflow = ConcurrentBuilder().participants([
research_agent,
plan_agent
]).build()
# 同时启动两个Agent
events = await workflow.run("计划12月去西雅图旅行7天")
执行时间对比:
-
顺序执行:研究(30秒) + 规划(40秒) = 70秒
-
并发执行:max(30秒, 40秒) = 40秒 ✅ 提速43%
输出格式:
========== 旅行研究报告 ==========
[Researcher-Agent输出]
西雅图12月旅行指南:
- 🌧️ 天气:冬季多雨,温度4-10°C,需备雨具
- 🎄 特色:圣诞市集、新年活动丰富
- 🦞 美食:派克市场海鲜、星巴克烘焙工坊
- ⚠️ 注意:需ESTA签证,注意室外活动防寒
========== 7日行程计划 ==========
[Plan-Agent输出]
Day 1: 抵达西雅图 → 市区酒店 → Pike Place Market
Day 2: Space Needle → Chihuly Garden → Seattle Center
Day 3: Boeing Factory Tour → 航空博物馆
...
模式3:条件工作流 - 内容审核发布系统
**场景:**自动化博客发布流程,包含审核环节。
流程设计:
[Writer-Agent] 写初稿
↓
[Reviewer-Agent] 审核
↓
[条件判断]
/ \
审核通过 审核失败
↓ ↓
[Publisher] [返回修改意见]
from agent_framework import WorkflowBuilder
# 定义三个Agent
writer_agent = chat_client.create_agent(
name="技术写作者",
instructions="根据提纲撰写技术教程,确保通俗易懂"
)
reviewer_agent = chat_client.create_agent(
name="内容审核员",
instructions="""审核文章质量:
- 字数是否超过200字
- 内容是否准确无误
- 格式是否规范
返回JSON: {"approved": true/false, "reason": "原因"}"""
)
publisher_agent = chat_client.create_agent(
name="发布者",
instructions="将审核通过的文章保存为Markdown文件"
)
# 条件选择函数
def select_next_step(review_result, target_ids):
publish_id, reject_id = target_ids
if review_result["approved"]:
return [publish_id] # 通过→发布
else:
return [reject_id] # 失败→返回修改意见
# 构建条件工作流
workflow = (
WorkflowBuilder()
.set_start_executor(writer_agent)
.add_edge(writer_agent, reviewer_agent)
.add_multi_selection_edge_group(
reviewer_agent,
[publisher_agent, handle_rejection], # 两条路径
selection_func=select_next_step # 条件函数
)
.build()
)
这种模式在审批流程、质量检测、智能路由场景下特别有用。
3.7 第七课:多智能体协作的终极形态
超越单Agent的思维局限
想象你要写一本技术书籍,如果一个人既要负责内容撰写、又要做技术审核、还要处理排版出版,效率会极其低下。更好的方式是:专业的人做专业的事。
多智能体系统的核心理念正是如此:
-
专业化分工:每个Agent只负责自己擅长的领域
-
高效协作:通过Workflow编排实现无缝衔接
-
容错机制:某个Agent失败不会导致整个流程崩溃
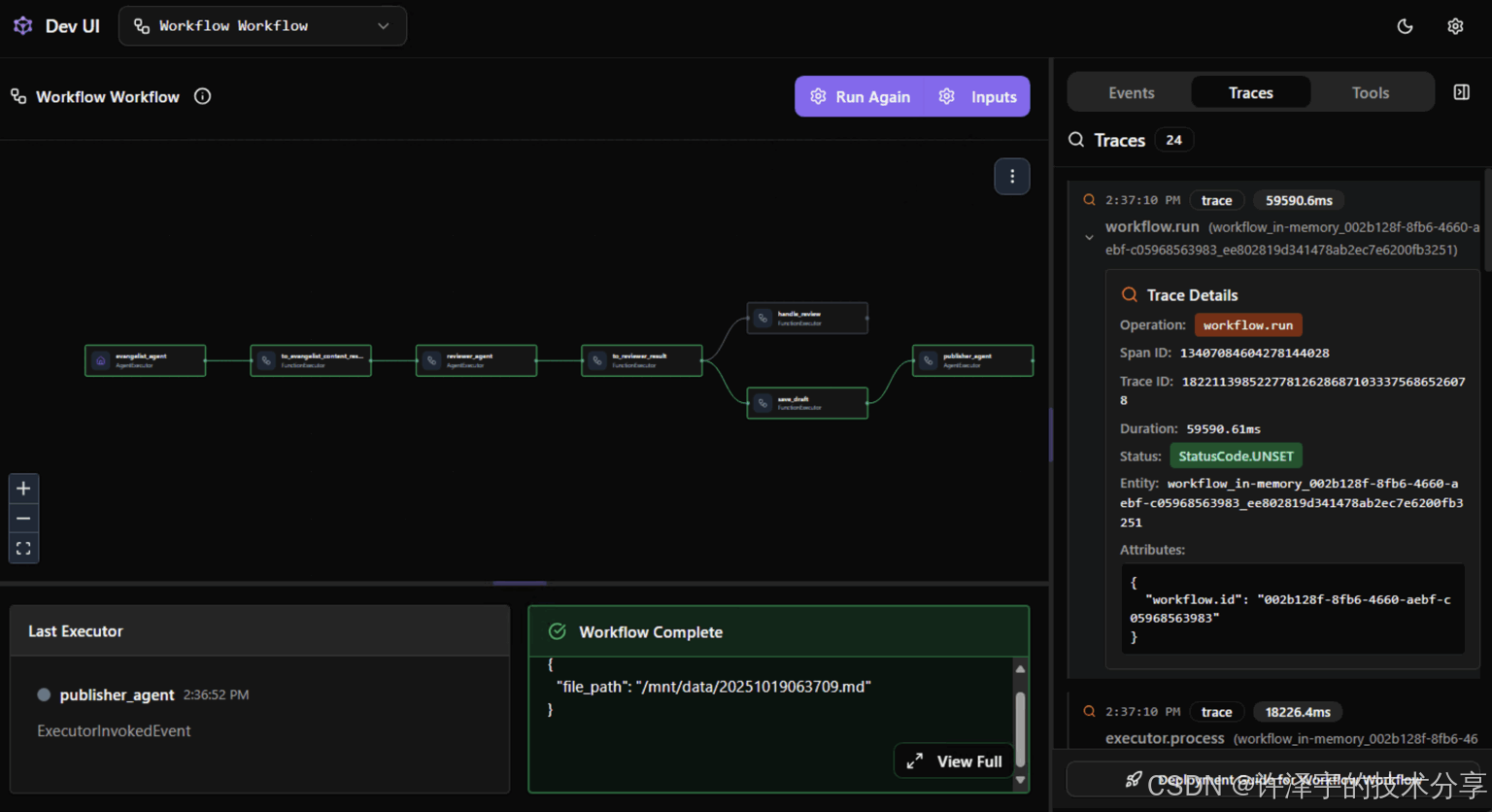
实战案例:全自动技术博客生成系统
系统架构:
用户输入主题
↓
[Evangelist-Agent] 搜集资料并撰写初稿
↓
[ContentReviewer-Agent] 质量审核(字数、准确性、格式)
↓
[条件分支]
├─ 通过 → [Publisher-Agent] 发布到CSDN
└─ 失败 → [NotificationAgent] 通知作者修改
完整代码实现:
from agent_framework import WorkflowBuilder
from agent_framework.azure import AzureAIAgentClient
from pydantic import BaseModel
import json
# 定义审核结果的数据结构
class ReviewResult(BaseModel):
approved: bool # 是否通过
word_count: int # 字数统计
reason: str # 审核意见
# Agent 1: 内容创作者
evangelist_agent = client.create_agent(
name="技术布道师",
instructions="""你是一位资深技术作家。
任务:根据用户提供的主题和参考资料,撰写一篇技术博客。
要求:
- 字数不少于300字
- 包含代码示例
- 结构清晰,有引言、正文、总结
- 语言通俗易懂"""
)
# Agent 2: 内容审核员
reviewer_agent = client.create_agent(
name="内容审核员",
instructions="""你是严格的质量审核员。
任务:评估文章质量,返回JSON格式的审核结果。
审核标准:
- 字数必须≥200字(关键指标)
- 内容准确性
- 格式规范性
返回格式:
{
"approved": true或false,
"word_count": 实际字数,
"reason": "审核意见"
}"""
)
# Agent 3: 发布者
publisher_agent = client.create_agent(
name="内容发布者",
instructions="""你是发布管理员。
任务:将审核通过的文章保存为Markdown文件。
文件名格式: article_YYYYMMDD_HHMMSS.md"""
)
# 自定义Executor:解析审核结果
class ReviewResultParser:
async def handle(self, message, context):
# 从Agent的JSON响应中提取审核结果
text = message.contents[0].text
json_data = json.loads(text)
review = ReviewResult(**json_data)
await context.send_message(review)
# 条件路由函数
def route_by_review(review: ReviewResult, target_ids: list[str]) -> list[str]:
publish_id, reject_id = target_ids
if review.approved:
print(f"✅ 审核通过!字数:{review.word_count}")
return [publish_id]
else:
print(f"❌ 审核失败:{review.reason}")
return [reject_id]
# 构建工作流
workflow = (
WorkflowBuilder()
.set_start_executor(evangelist_agent)
.add_edge(evangelist_agent, reviewer_agent)
.add_edge(reviewer_agent, ReviewResultParser()) # 解析JSON
.add_multi_selection_edge_group(
ReviewResultParser(),
[publisher_agent, handle_rejection],
selection_func=route_by_review
)
.build()
)
# 执行任务
topic = "Python装饰器的实战应用"
resources = [
"https://docs.python.org/3/glossary.html#term-decorator",
"https://realpython.com/primer-on-python-decorators/"
]
result = await workflow.run(f"""
主题:{topic}
参考资料:{', '.join(resources)}
请撰写一篇适合中级开发者阅读的技术博客。
""")
执行日志:
[Evangelist-Agent] 开始撰写...
[Evangelist-Agent] 初稿完成(预计字数:450字)
[ContentReviewer-Agent] 开始审核...
[ContentReviewer-Agent] 审核结果:
{
"approved": true,
"word_count": 452,
"reason": "文章质量优秀,代码示例清晰,结构合理"
}
✅ 审核通过!字数:452
[Publisher-Agent] 正在发布...
[Publisher-Agent] 文章已保存: article_20241023_153042.md
关键设计点解析
1. 类型安全的消息传递
class ReviewResult(BaseModel):
approved: bool
word_count: int
reason: str
使用Pydantic定义数据结构,确保Agent之间传递的数据格式正确,避免运行时错误。
2. 自定义Executor的必要性
为什么需要ReviewResultParser?因为Agent返回的是自然语言格式的JSON字符串,我们需要:
-
解析JSON
-
验证数据格式
-
转换为Python对象
这样后续的route_by_review函数才能正确处理。
3. 错误处理机制
def route_by_review(review: ReviewResult, target_ids: list[str]) -> list[str]:
if review.approved:
return [publish_id] # 进入发布流程
else:
return [reject_id] # 进入错误处理流程
失败时不会让整个系统崩溃,而是优雅地进入备用流程(如通知人工介入)。
3.8 第八课:可观测性 - 让Agent的思考过程"可视化"
为什么需要可观测性?
你的Agent突然给出了一个奇怪的答案,或者卡住不动了。这时候你肯定想知道:
-
它的推理过程是什么?
-
调用了哪些工具?
-
哪一步出现了问题?
这就是**可观测性(Observability)**要解决的问题。Microsoft Agent Framework提供了两大利器:
-
DevUI - 实时可视化调试界面
-
Tracing - 结构化日志追踪
DevUI:Agent的"浏览器开发者工具"
DevUI提供了一个Web界面,让你能像调试前端代码一样调试Agent:
启动方式:
# 在项目目录下运行
agent-framework-devui
# 输出:
# DevUI server started at http://localhost:3000
# Connect your agent to start debugging
功能展示:
┌─────────────────────────────────────────────┐
│ Agent Session Timeline │
├─────────────────────────────────────────────┤
│ 🧑 User: "帮我规划去巴黎的旅行" │
│ ↓ │
│ 🤖 Agent: [Thinking] 需要调用工具获取信息 │
│ ↓ │
│ 🔧 Tool Call: get_destination_info() │
│ Parameters: {"city": "Paris"} │
│ Result: {weather: "15°C", ...} │
│ ↓ │
│ 🤖 Agent: [Generating] 基于查询结果生成答案│
│ ↓ │
│ 💬 Response: "巴黎的天气..." │
└─────────────────────────────────────────────┘
实际应用示例:
# 在代码中启用DevUI追踪
from agent_framework.devui import enable_devui_tracing
enable_devui_tracing() # 自动连接到DevUI服务器
agent = ChatAgent(...)
result = await agent.run("你的问题")
# 此时打开 http://localhost:3000 就能看到完整的执行过程
Tracing:结构化日志追踪
对于生产环境,DevUI不太实用(需要开Web服务)。这时候可以用日志追踪:
import logging
from agent_framework import setup_agent_logging
# 配置日志输出
setup_agent_logging(
level=logging.DEBUG,
output_file="agent_trace.log",
format="%(asctime)s [%(levelname)s] %(message)s"
)
# 运行Agent(自动记录所有事件)
agent = ChatAgent(...)
result = await agent.run("计算1+1")
生成的日志文件:
2024-10-23 15:30:42 [INFO] AgentRun started: run_id=abc123
2024-10-23 15:30:42 [DEBUG] User message received: "计算1+1"
2024-10-23 15:30:43 [DEBUG] LLM request: model=gpt-4o, tokens=120
2024-10-23 15:30:44 [DEBUG] LLM response: "答案是2", tokens=5
2024-10-23 15:30:44 [INFO] AgentRun completed: duration=2.3s, cost=$0.0012
通过日志,你可以:
-
统计每次调用的耗时和成本
-
定位性能瓶颈(哪个LLM调用最慢?)
-
回溯错误现场(出错前Agent的状态是什么?)
集成Azure Monitor:企业级监控
对于大规模部署,还可以集成Azure Monitor实现全链路追踪:
from azure.monitor.opentelemetry import configure_azure_monitor
from agent_framework import ChatAgent
# 配置Azure Monitor
configure_azure_monitor(
connection_string="your_app_insights_connection_string"
)
# 之后所有Agent调用都会自动上报到Azure Monitor
agent = ChatAgent(...)
result = await agent.run("测试")
在Azure Portal中,你能看到:
-
请求成功率、P99延迟
-
依赖调用拓扑图(Agent → OpenAI → Database)
-
异常告警和智能诊断
四、架构设计哲学:为什么Microsoft Agent Framework这样设计?
4.1 统一抽象:跨语言、跨Provider的一致性
设计原则
无论你用Python还是.NET,无论连接Azure OpenAI还是GitHub Models,核心API都保持一致:
# Python
agent = chat_client.create_agent(instructions="...", tools=[...])
result = await agent.run("query")
# C#/.NET
AIAgent agent = chatClient.CreateAIAgent(instructions: "...", tools: [...]);
var result = await agent.RunAsync("query");
这种设计让你可以:
-
团队协作:Python数据科学家和.NET后端工程师用同一套概念沟通
-
渐进式迁移:先用免费的GitHub Models测试,确认效果后再切到Azure OpenAI
-
技能迁移:学会Python版本后,切换到.NET只需很短的适应期
对比其他框架
-
LangChain:Python和JavaScript版本API差异大,切换语言=重新学习
-
Semantic Kernel:之前只支持.NET,后来才补充Python版本
-
Microsoft Agent Framework:从设计之初就是跨语言统一架构
4.2 图执行模型:Workflow的底层原理
Pregel启发的设计
Workflow系统采用了类似Google Pregel的图计算模型:
-
图结构表示:Agent和Executor是节点,Edge是有向边
-
超步执行:每次迭代称为一个"superstep",所有节点并行处理消息
-
消息传递:节点通过发送消息到邻居节点进行通信
为什么这样设计?
-
✅ 天然支持并发(多个Agent可以同时工作)
-
✅ 容错性好(节点失败不影响其他节点)
-
✅ 可扩展(增加新Agent只需添加节点和边)
示例:并发Workflow的执行过程
Superstep 1:
Dispatcher → [发送消息] → Researcher
Dispatcher → [发送消息] → Planner
Superstep 2:
Researcher → [处理消息] → 返回研究结果
Planner → [处理消息] → 返回行程计划
Superstep 3:
Aggregator → [接收消息] → 汇总结果
Aggregator → [发送消息] → 输出节点
Superstep 4:
输出节点 → [生成最终响应]
4.3 声明式 vs 命令式:WorkflowBuilder的优雅
声明式API的优势
# 声明式:描述"要什么"
workflow = (
WorkflowBuilder()
.set_start_executor(agent1)
.add_edge(agent1, agent2)
.add_edge(agent2, agent3)
.build()
)
vs
# 命令式:描述"怎么做"
agent1.on_complete(lambda result: agent2.process(result))
agent2.on_complete(lambda result: agent3.process(result))
agent1.execute(user_input)
声明式的优势:
-
可视化:容易画出流程图
-
可组合:Workflow可以嵌套复用
-
易测试:可以模拟某个节点的输出,测试下游逻辑
五、实战技巧与最佳实践
5.1 Instructions设计的黄金法则
好的instructions能让Agent事半功倍。以下是经过大量实践总结的模板:
instructions = """
# 角色定位
你是一个{具体角色},擅长{核心技能}。
# 工作流程
当用户{触发条件}时:
1. 先{第一步操作}
2. 然后{第二步操作}
3. 最后{输出格式}
# 质量标准
- 确保{质量要求1}
- 避免{常见错误}
- 如果遇到{异常情况},则{处理方式}
# 输出格式
{具体的格式要求,最好有示例}
"""
反面教材:
instructions = "你是一个助手" # ❌ 太笼统
正面案例:
instructions = """
你是一个Python代码审查专家,专注于发现性能问题和安全漏洞。
工作流程:
1. 阅读用户提交的代码
2. 使用Code Interpreter工具运行代码并测试边界情况
3. 生成审查报告
审查标准:
- 性能:是否有O(n²)以上的算法可以优化?
- 安全:是否有SQL注入、XSS等风险?
- 可读性:变量命名是否清晰?
输出格式:
## 🔍 审查结果
- ✅ 通过项: ...
- ⚠️ 建议优化: ...
- ❌ 严重问题: ...
"""
5.2 工具设计的三大原则
原则1:单一职责
❌ 错误示例:
def process_user_request(user_id, action, data):
"""处理用户请求(查询/创建/删除)"""
if action == "query":
return db.query(user_id)
elif action == "create":
return db.insert(data)
elif action == "delete":
return db.delete(user_id)
✅ 正确示例:
def get_user_info(user_id: int) -> dict:
"""根据用户ID查询用户信息"""
return db.query_user(user_id)
def create_user(name: str, email: str) -> int:
"""创建新用户,返回用户ID"""
return db.insert_user(name, email)
def delete_user(user_id: int) -> bool:
"""删除用户,返回是否成功"""
return db.delete_user(user_id)
为什么?因为LLM在选择工具时,会根据工具描述匹配。描述越精确,选择越准确。
原则2:类型标注必不可少
def calculate_price(quantity, discount) -> float: # ❌ 参数类型不明
pass
def calculate_price(quantity: int, discount: float) -> float: # ✅ 清晰
"""计算折后价格
Args:
quantity: 商品数量
discount: 折扣率(0.0-1.0)
Returns:
折后总价
"""
pass
类型标注不仅帮助LLM理解参数,还能在运行时做自动校验。
原则3:优雅的错误处理
def fetch_weather(city: str) -> dict:
"""查询城市天气"""
try:
response = requests.get(f"https://api.weather.com/{city}")
response.raise_for_status()
return response.json()
except requests.RequestException as e:
return {
"error": True,
"message": f"无法获取{city}的天气信息:{str(e)}"
}
返回错误信息而不是抛出异常,让Agent能优雅地处理失败情况。
5.3 成本优化:不要让每次调用都破产
技巧1:选择合适的模型
| 任务复杂度 | 推荐模型 | 成本 |
|---|---|---|
| 简单分类、提取 | gpt-4o-mini | $ |
| 中等推理、写作 | gpt-4o | $$ |
| 复杂分析、编程 | gpt-4-turbo | $$$ |
# 根据任务动态选择模型
if task_complexity == "simple":
client = OpenAIChatClient(ai_model_id="gpt-4o-mini")
else:
client = OpenAIChatClient(ai_model_id="gpt-4o")
技巧2:缓存机制
from functools import lru_cache
@lru_cache(maxsize=100)
def get_city_info(city: str) -> dict:
"""查询城市信息(带缓存)"""
return api.query_city(city)
对于不常变化的数据(如城市信息、产品目录),使用缓存避免重复调用LLM。
技巧3:批量处理
# ❌ 低效:每个问题单独调用
for question in questions:
answer = await agent.run(question)
# ✅ 高效:批量处理
batch_query = "\n".join([f"{i+1}. {q}" for i, q in enumerate(questions)])
answers = await agent.run(f"回答以下{len(questions)}个问题:\n{batch_query}")
六、未来趋势:Agent技术的下一站
6.1 从Agent到Agent OS
当前的Agent更像是"应用程序",而未来会出现"Agent操作系统":
-
统一调度:类似Kubernetes管理容器,Agent OS管理所有Agent实例
-
资源分配:智能分配GPU/内存给不同Agent
-
市场化工具:Agent可以从"工具市场"自动下载和安装新能力
Microsoft Agent Framework正在朝这个方向演进,Azure AI Foundry已经初步具备了Agent管理和工具市场的雏形。
6.2 多模态Agent的崛起
GPT-4o等模型已经支持图片、音频输入,未来的Agent将:
-
视觉理解:不仅看懂图片,还能理解视频内容
-
语音交互:直接语音对话,无需文字中转
-
生成式工具:Agent自己创建图片、视频作为工作成果
# 未来可能的API
agent = MultimodalAgent(
instructions="你是视频编辑助手",
tools=[VideoGenerator(), AudioMixer(), ScriptWriter()]
)
result = await agent.run(
VideoContent("raw_footage.mp4"),
"把这段视频剪辑成60秒的Vlog,配上轻快的背景音乐"
)
# 输出: edited_vlog.mp4
6.3 Self-Improving Agents:能自我进化的Agent
最前沿的研究方向是元学习Agent:
-
自我评估:Agent运行后自动评估效果
-
策略优化:根据反馈调整instructions和工具选择
-
持续进化:在生产环境中不断学习,越用越聪明
想象你的客服Agent,随着处理的案例越来越多,自动学会了处理新类型的问题,而不需要工程师重新训练。
七、总结:从工具到范式的跃迁
回顾九大能力地图
让我们回到文章开头的表格,现在你应该对每个模块都有了深刻理解:
| 模块 | 你学到了什么 |
|---|---|
| Agent基础 | Agent = LLM + Tools + Memory |
| 创建首个Agent | 用100行代码搭建旅行助手 |
| 多Provider连接 | 一套代码,灵活切换模型 |
| 工具集成 | Vision、Code Interpreter等四大内置工具 |
| MCP协议 | 标准化接入外部服务 |
| RAG检索增强 | 让Agent拥有专业知识 |
| Workflow编排 | 顺序/并发/条件三大模式 |
| 多智能体协作 | 专业化分工,高效协作 |
| 评估与追踪 | DevUI可视化调试 + 结构化日志 |
核心观念的转变
传统思维:
问题 → 写代码 → 调API → 拼装结果 → 返回
Agent思维:
问题 → Agent自主规划 → 调用工具链 → 迭代优化 → 返回
这不仅是技术栈的变化,更是编程范式的跃迁:
-
从"命令式编程"到"声明式编排"
-
从"精确控制"到"目标驱动"
-
从"单体应用"到"Agent协作"
行动建议:你的下一步
如果你是初学者:
-
跑通本文的旅行助手示例
-
尝试给Agent增加2-3个自定义工具
-
用DevUI观察Agent的执行过程
如果你是中级开发者:
-
搭建一个RAG系统,接入公司文档
-
实现一个3-Agent的Workflow(如内容创作流水线)
-
集成Azure Monitor做性能监控
如果你是架构师:
-
评估Agent Framework在现有系统中的适用场景
-
设计企业级的Agent治理方案(权限、审计、成本控制)
-
探索Agent与微服务架构的融合
写在最后:AI的未来,由你定义
两年前,ChatGPT横空出世,让我们见识到了LLM的强大。但那只是"对话"——AI只能说,不能做。
今天,Agent技术让AI真正变成了可执行的智能。它们能够理解你的意图、规划行动路径、调用各种工具、协同完成复杂任务。
Microsoft Agent Framework提供的,不仅是一套SDK,更是一个构建智能系统的新范式。它统一了Python和.NET生态,兼容多种AI模型,提供了从开发到生产的全链路支持。
更重要的是,它开启了一扇门:
-
对开发者:你不再需要从零实现Agent逻辑,专注于业务创新即可
-
对企业:AI不再是科研项目,而是可落地的生产力工具
-
对行业:各行各业都能用Agent重塑业务流程
这篇8000字的文章,只是Agent世界的一张导览图。真正的探索,需要你亲自动手:
# 你的Agent之旅,从这行代码开始
agent = ChatAgent(...)
future = await agent.run("改变世界")
愿你在这场智能革命中,找到属于自己的位置。让我们一起,用Agent构建更智能的未来。
参考资源:
-
Microsoft Agent Framework官方文档:https://github.com/microsoft/agent-framework
-
Azure AI Foundry:https://azure.microsoft.com/products/ai-foundry
-
本文配套代码仓库:https://github.com/microsoft/agent-framework-samples




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











