








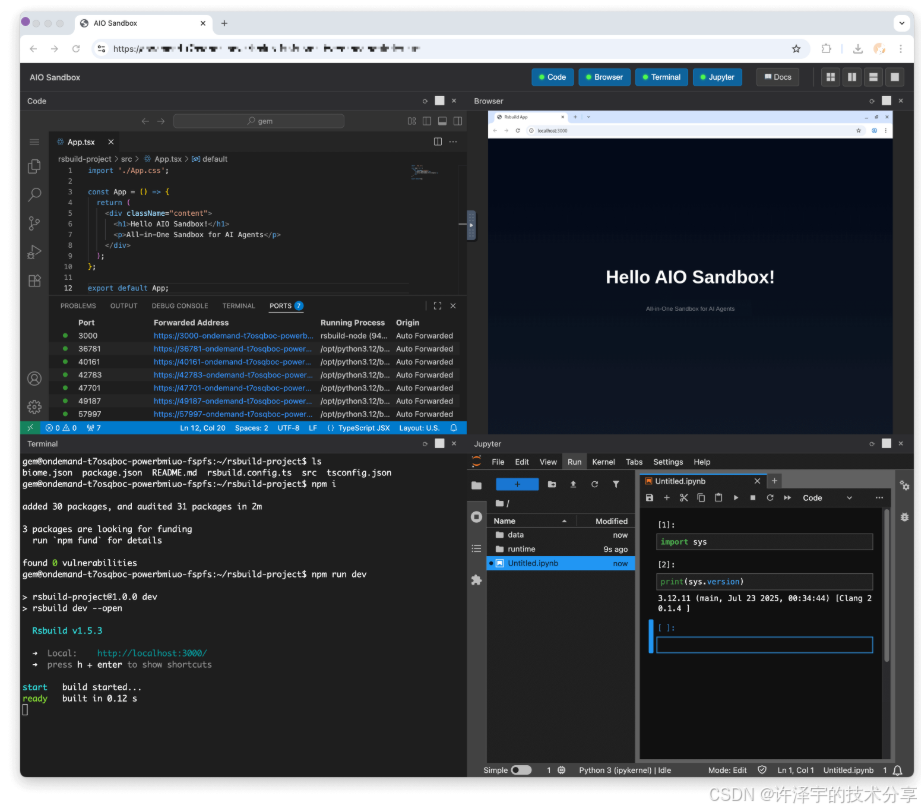
当你的AI Agent需要同时浏览网页、执行代码、操作文件时,你是否曾为环境隔离、数据共享而焦头烂额?今天,让我们聊聊一个可能彻底改变你开发方式的开源项目。
一、从一个真实场景说起
想象这样一个场景:你正在开发一个智能数据分析Agent,它需要从网页抓取数据,在Jupyter中进行数据清洗,最后生成可视化报告并保存到文件系统。听起来很简单?但实际开发中,你可能需要:
-
启动一个Selenium容器用于浏览器自动化
-
配置一个独立的Jupyter环境用于数据处理
-
搭建文件服务器用于存储中间结果
-
在这三个独立环境间传递数据——天啊,这才是真正的噩梦
数据在不同容器间的传递需要网络调用或共享卷,环境配置复杂且容易出错,排查问题时要在多个容器日志间来回跳转。这种分裂的架构让本该专注于Agent逻辑的开发者,把大量时间浪费在了基础设施的维护上。
这就是为什么AIO Sandbox(All-in-One Sandbox)的诞生显得如此重要——它用一个优雅的解决方案,回答了一个核心问题:为什么AI Agent的执行环境一定要是割裂的?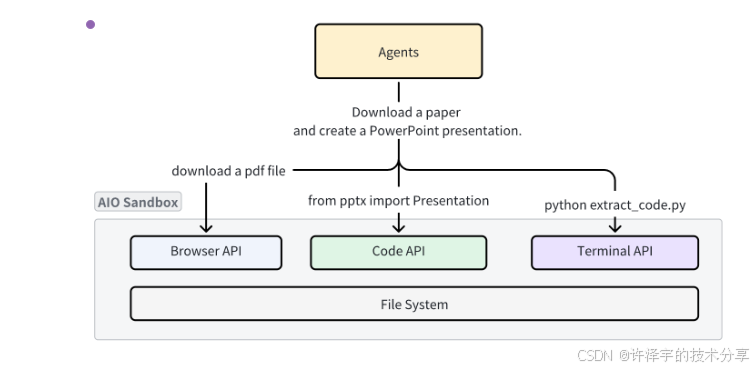
二、AIO Sandbox的技术哲学:大道至简
2.1 架构设计的深层思考
在传统的微服务思维定式下,我们习惯性地将每个功能拆分成独立服务。但AIO Sandbox的设计团队反其道而行——他们发现,对于AI Agent这种需要频繁跨功能协作的场景,统一环境才是真正的效率之源。
让我们看看AIO Sandbox的核心架构:
┌─────────────────────────────────────────────────────────────┐
│ 🌐 Browser + VNC │
│ (基于Chromium + noVNC远程桌面) │
├─────────────────────────────────────────────────────────────┤
│ 💻 VSCode Server │ 🐚 Shell Terminal │ 📁 File Ops │
│ (code-server) │ (WebSocket TTY) │ (REST API) │
├─────────────────────────────────────────────────────────────┤
│ 🔗 MCP Hub + 🔒 Sandbox Fusion │
│ (Model Context Protocol 服务编排层) │
├─────────────────────────────────────────────────────────────┤
│ 🚀 Preview Proxy + 📊 Service Monitoring │
│ (智能端口转发 + 健康检查) │
└─────────────────────────────────────────────────────────────┘
↑
共享文件系统 (Unified Filesystem)
这个架构的巧妙之处在于分层而不分离:
-
展示层:多种交互方式(VNC、VSCode、Terminal)满足不同场景
-
编排层:MCP Hub统一管理各种能力的调用
-
基础层:所有服务共享同一个文件系统和进程空间
这种设计带来的最大好处是:零成本的数据共享。浏览器下载的文件,Shell脚本可以直接读取;Jupyter生成的图表,文件API可以立即访问。不需要任何中间传输环节。
2.2 技术栈拆解:每一个选择都有深意
容器化的艺术:轻量但不简单
AIO Sandbox基于Docker构建,但它不是简单的"服务打包"。让我们看看Dockerfile背后的设计智慧:
-
基础镜像选择:采用Ubuntu而非Alpine,确保足够的软件包生态支持
-
安全配置:使用
--security-opt seccomp=unconfined平衡安全与功能(某些浏览器特性需要更多系统调用权限) -
资源优化:默认2GB共享内存(
shm_size: "2gb"),专门为Chromium的渲染进程优化
浏览器自动化:CDP协议的深度应用
区别于传统的Selenium WebDriver,AIO Sandbox选择了更底层的CDP(Chrome DevTools Protocol):
# 传统Selenium方式(需要额外的WebDriver进程)
from selenium import webdriver
driver = webdriver.Chrome()
# AIO Sandbox的CDP方式(直连浏览器进程)
from playwright.async_api import async_playwright
browser_info = client.browser.get_info().data
page = await (await p.chromium.connect_over_cdp(browser_info.cdp_url)).new_page()
CDP的优势在于:
-
更低延迟:直接通过WebSocket与浏览器通信,无中间代理
-
更强控制:可以拦截网络请求、修改响应、注入脚本
-
更好稳定性:少一层抽象就少一层出错可能
MCP集成:面向未来的AI协议
Model Context Protocol(MCP)是Anthropic提出的AI Agent工具调用标准。AIO Sandbox预置了四个MCP服务器:
-
Browser MCP:Web自动化与数据抓取
-
File MCP:文件系统操作
-
Shell MCP:命令执行
-
Markitdown MCP:文档格式转换
这意味着什么?你的Agent可以用统一的工具调用接口,无缝切换任务:
from langchain_mcp_adapters.client import MultiServerMCPClient
mcp_client = MultiServerMCPClient({
"sandbox": {
"url": "http://localhost:8080/mcp/",
"transport": "streamable_http"
}
})
# 获取所有MCP工具(浏览器、文件、终端...)
tools = await mcp_client.get_tools()
这种标准化带来的好处是即插即用:今天你用OpenAI的Assistant,明天切换到Claude或LangGraph,工具层完全不需要改动。
三、核心实现:从SDK到应用的全链路解析
3.1 SDK设计的工程美学
AIO Sandbox提供了Python、TypeScript和Go三种SDK,我们以Python为例,看看其设计的精妙之处。
懒加载的客户端模式
class Sandbox:
def __init__(self, *, base_url: str, ...):
self._client_wrapper = SyncClientWrapper(base_url=base_url, ...)
# 注意:这些客户端初始化为None
self._shell: typing.Optional[ShellClient] = None
self._file: typing.Optional[FileClient] = None
self._browser: typing.Optional[BrowserClient] = None
@property
def shell(self):
if self._shell is None:
from .shell.client import ShellClient
self._shell = ShellClient(client_wrapper=self._client_wrapper)
return self._shell
这种设计的好处是:
-
按需加载:只有真正使用某个模块时才会导入,减少启动开销
-
共享连接:所有子客户端复用同一个HTTP连接池(
client_wrapper) -
独立扩展:每个子模块可以独立开发和测试
同步与异步的双重支持
SDK同时提供Sandbox和AsyncSandbox两个类,这不是简单的API包装:
# 同步方式:适合脚本式调用
client = Sandbox(base_url="http://localhost:8080")
result = client.shell.exec_command(command="ls -la")
# 异步方式:适合高并发场景
async def batch_process():
client = AsyncSandbox(base_url="http://localhost:8080")
tasks = [client.shell.exec_command(command=cmd) for cmd in commands]
results = await asyncio.gather(*tasks)
在底层,异步版本使用httpx.AsyncClient,充分利用了事件循环的优势。这意味着在处理大量并发任务时(比如批量网页爬取),性能可以提升数倍。
3.2 实战案例:网页转Markdown的背后逻辑
让我们深入分析官方示例site-to-markdown的实现,它展示了AIO Sandbox的核心价值。
第一步:浏览器自动化获取内容
async with async_playwright() as p:
browser_info = c.browser.get_info().data
page = await (await p.chromium.connect_over_cdp(browser_info.cdp_url)).new_page(
viewport={"width": browser_info.viewport.width, "height": browser_info.viewport.height}
)
await page.goto("https://sandbox.agent-infra.com/", wait_until="networkidle")
html = await page.content()
screenshot_b64 = base64.b64encode(await page.screenshot(full_page=False)).decode('utf-8')
关键技术点:
-
使用
connect_over_cdp而非启动新浏览器,复用容器内已运行的浏览器进程 -
wait_until="networkidle"确保页面完全加载(包括异步资源) -
同时获取HTML和截图,一次访问获取多份数据
第二步:沙盒内执行代码转换
c.jupyter.execute_code(code=f"""
from markdownify import markdownify
html = '''{html}'''
screenshot_b64 = "{screenshot_b64}"
md = f"{{markdownify(html)}}\\n\\n"
with open('{home_dir}/site.md', 'w') as f:
f.write(md)
print("Done!")
""")
这里有个精彩的设计:代码在容器内执行,而不是在调用者环境。
这意味着:
-
依赖管理简单:
markdownify库已预装在容器内,无需调用者安装 -
安全隔离:即使转换代码有问题,也不会影响宿主机
-
性能优化:大文件处理在容器内完成,不需要网络传输原始数据
第三步:统一文件系统的便利
# Shell查看生成的文件
list_result = c.shell.exec_command(command=f"ls -lh {home_dir}")
# 文件API读取内容
content = c.file.read_file(file=f"{home_dir}/site.md").data.content
注意这里的妙处:浏览器下载的内容、Jupyter生成的文件、Shell操作的对象,都是同一个文件系统中的数据。不需要任何"导出-导入"步骤。
3.3 企业级集成:以OpenAI为例
在生产环境中,我们往往需要将Sandbox能力封装成AI工具。看看OpenAI Function Calling的集成方式:
sandbox = Sandbox(base_url="http://localhost:8080")
def run_code(code, lang="python"):
if lang == "python":
return sandbox.jupyter.execute_code(code=code).data
return sandbox.nodejs.execute_code(code=code).data
# 定义为OpenAI工具
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "calculate 1+1"}],
tools=[{
"type": "function",
"function": {
"name": "run_code",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string"},
"lang": {"type": "string"}
}
}
}
}]
)
# GPT会自动调用run_code工具
if response.choices[0].message.tool_calls:
args = json.loads(response.choices[0].message.tool_calls[0].function.arguments)
result = run_code(**args)
print(result.outputs[0].text)
这个模式的精髓在于能力抽象:对于GPT来说,它只需要知道"我可以执行代码",而不需要关心底层是Jupyter还是REPL,是本地还是远程。这种抽象让Agent的能力可以无缝升级和替换。
四、应用场景:从研究到生产的全覆盖
4.1 数据科学工作流自动化
传统的数据科学流程是高度手工的:Jupyter Notebook里跑代码,生成的图表手动保存,数据清洗脚本单独维护。AIO Sandbox可以将整个流程Agent化:
async def auto_data_analysis(url: str, query: str):
# 1. 爬取数据
page = await browser.new_page()
await page.goto(url)
data = await page.evaluate("() => document.querySelector('table').innerText")
# 2. 在沙盒中分析
analysis_code = f"""
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('/tmp/data.csv')
result = df.query('{query}')
plt.plot(result)
plt.savefig('/tmp/result.png')
print(result.describe())
"""
output = client.jupyter.execute_code(code=analysis_code)
# 3. 读取结果
plot = client.file.download_file(file="/tmp/result.png")
return output, plot
这个流程完全自动化,且每一步都有清晰的状态追踪。
4.2 自动化测试平台
想象一个Web应用的端到端测试场景:
# 启动被测应用(在沙盒容器内)
client.shell.exec_command(command="cd /app && npm run dev", session="test-app")
# 等待服务启动
await asyncio.sleep(5)
# 在同一容器内访问应用(无需暴露端口)
browser_info = client.browser.get_info().data
page = await playwright.chromium.connect_over_cdp(browser_info.cdp_url).new_page()
await page.goto("http://localhost:3000")
# 执行测试
await page.fill("#username", "test")
await page.click("#login")
assert await page.locator("#dashboard").is_visible()
因为应用和浏览器在同一容器内,测试环境非常稳定,不受网络波动影响。
4.3 智能运维Agent
结合MCP和Shell能力,可以构建自主决策的运维Agent:
from langchain_mcp_adapters.client import MultiServerMCPClient
from deepagents import create_deep_agent
mcp_client = MultiServerMCPClient({
"sandbox": {"url": "http://localhost:8080/mcp/", "transport": "streamable_http"}
})
agent = create_deep_agent(
tools=await mcp_client.get_tools(),
system_prompt="""你是一个运维专家Agent。可以:
1. 使用shell工具检查系统状态
2. 使用file工具读取日志
3. 使用browser工具访问监控面板
4. 根据情况执行修复命令
""",
model=ChatOpenAI(model="gpt-4")
)
# Agent自主分析和处理
async for chunk in agent.astream(
{"messages": [{"role": "user", "content": "服务器负载异常,请排查"}]},
stream_mode="values"
):
print(chunk["messages"][-1])
Agent会自主调用shell检查CPU/内存,读取/var/log分析错误,甚至重启服务——所有操作都在隔离的沙盒中,安全可控。
4.4 内容创作辅助工具
自动化生成技术文档的场景:
async def generate_api_doc(repo_url: str):
# 1. Clone代码
client.shell.exec_command(f"git clone {repo_url} /tmp/repo")
# 2. 分析代码结构
files = client.file.list_files(path="/tmp/repo", recursive=True)
# 3. 使用GPT生成文档
for file in files:
if file.endswith('.py'):
code = client.file.read_file(file=file).data.content
doc = await gpt_generate_doc(code)
# 4. 保存Markdown
doc_path = file.replace('.py', '.md')
client.file.write_file(file=doc_path, content=doc)
# 5. 生成目录页面
index = generate_index(files)
client.file.write_file(file="/tmp/repo/docs/index.html", content=index)
整个流程中,代码克隆、分析、文档生成都在沙盒内完成,本地环境保持干净。
五、云端部署:从本地到生产的演进
5.1 Docker Compose部署
对于中小型团队,Docker Compose是最快的上手方式:
version: '3.8'
services:
sandbox:
container_name: aio-sandbox
image: ghcr.io/agent-infra/sandbox:latest
volumes:
- ./workspace:/home/gem/workspace # 持久化工作区
security_opt:
- seccomp:unconfined
restart: unless-stopped
shm_size: "2gb"
ports:
- "8080:8080"
environment:
PROXY_SERVER: host.docker.internal:7890 # 代理配置
WORKSPACE: "/home/gem/workspace"
TZ: "Asia/Shanghai"
生产级配置建议:
-
shm_size:Chromium渲染大页面需要足够共享内存,推荐2GB+ -
security_opt:某些浏览器特性需要更多系统调用权限 -
volumes:持久化工作区,容器重启不丢失数据
5.2 Kubernetes部署
对于高并发场景,Kubernetes提供更好的弹性伸缩:
apiVersion: apps/v1
kind: Deployment
metadata:
name: aio-sandbox
spec:
replicas: 3 # 多副本支持并发
template:
spec:
containers:
- name: aio-sandbox
image: ghcr.io/agent-infra/sandbox:latest
ports:
- containerPort: 8080
resources:
limits:
memory: "2Gi"
cpu: "1000m"
requests:
memory: "1Gi"
cpu: "500m"
livenessProbe: # 健康检查
httpGet:
path: /v1/docs
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
生产环境优化:
-
使用StatefulSet而非Deployment,确保会话粘性
-
配置HPA自动伸缩,根据CPU/内存动态调整副本数
-
使用PVC持久化每个实例的工作区
5.3 云服务商集成:火山引擎示例
AIO Sandbox提供了云服务商SDK,以火山引擎(Volcengine)为例:
from agent_sandbox.providers import VolcengineProvider
provider = VolcengineProvider(
access_key=os.getenv("VOLC_ACCESSKEY"),
secret_key=os.getenv("VOLC_SECRETKEY"),
region="cn-beijing"
)
# 创建沙盒实例
sandbox_id = provider.create_sandbox(function_id="your_function_id", timeout=30)
# 获取访问地址
sandbox_info = provider.get_sandbox(function_id="your_function_id", sandbox_id=sandbox_id)
domains = sandbox_info["domains"]
# 使用SDK连接
client = Sandbox(base_url=f"https://{domains[0]['domain']}")
这种集成的好处是:
-
按需创建:用时启动,用完销毁,节省成本
-
动态伸缩:云端自动管理资源,无需运维
-
全球部署:不同地区的用户连接到最近的节点
六、深度对比:AIO Sandbox vs 传统方案
6.1 与多容器方案的对比
| 维度 | 传统多容器 | AIO Sandbox |
|---|---|---|
| 数据共享 | 需要网络调用或卷挂载 | 统一文件系统,零拷贝 |
| 资源占用 | 每个服务独立占用内存 | 共享基础镜像和运行时 |
| 启动速度 | 需要启动多个容器(数十秒) | 单容器启动(3-5秒) |
| 网络延迟 | 容器间网络调用(5-20ms) | 本地调用(<1ms) |
| 配置复杂度 | 需要编排工具(Docker Compose/K8s) | 单容器部署 |
真实性能测试(100次文件读写操作):
-
多容器方案(文件通过API传输):~2.3秒
-
AIO Sandbox(本地文件系统):~0.15秒
性能提升超过15倍!
6.2 与云IDE平台的对比
类似GitHub Codespaces或Cloud9的云IDE平台,也提供了浏览器+终端+IDE的组合,但它们的定位是"人类开发者",而AIO Sandbox是"AI Agent":
| 特性 | 云IDE平台 | AIO Sandbox |
|---|---|---|
| 交互方式 | Web界面为主 | API/SDK为主 |
| 浏览器自动化 | 不支持或有限支持 | 完整CDP协议支持 |
| MCP集成 | 无 | 原生支持 |
| 可编程性 | 有限(通过插件) | 完全可编程 |
| 会话管理 | 基于用户账号 | 基于API Token |
AIO Sandbox的核心优势在于API优先设计——所有功能都可以通过代码调用,而不是手动点击。
6.3 与Serverless函数的对比
AWS Lambda或阿里云函数计算可以执行代码,但它们是"无状态"的:
| 维度 | Serverless函数 | AIO Sandbox |
|---|---|---|
| 状态保持 | 无状态,每次调用独立 | 有状态,会话内共享 |
| 浏览器支持 | 不支持(无GUI) | 完整浏览器环境 |
| 执行时长 | 通常限制15分钟内 | 可长期运行 |
| 调试体验 | 只能看日志 | 可VNC连接查看实时状态 |
对于需要多步骤协作的AI Agent任务(比如爬取数据→分析→生成报告),有状态的Sandbox明显更合适。
七、实践中的坑与优化建议
7.1 内存管理
浏览器是"内存杀手",尤其是打开多个标签页或处理大型页面时。推荐实践:
# ❌ 不好的做法:复用同一个page对象
page = await browser.new_page()
for url in urls:
await page.goto(url) # 内存累积
# ✅ 好的做法:每个任务使用独立上下文
for url in urls:
context = await browser.new_context()
page = await context.new_page()
await page.goto(url)
# 处理...
await context.close() # 释放内存
7.2 并发控制
虽然Sandbox内可以运行多个任务,但要避免资源争抢:
# 使用信号量控制并发数
semaphore = asyncio.Semaphore(3) # 最多3个并发任务
async def controlled_task(url):
async with semaphore:
return await process_url(url)
# 批量处理时限制并发
tasks = [controlled_task(url) for url in urls]
results = await asyncio.gather(*tasks)
7.3 网络代理配置
在企业环境中,容器可能需要通过代理访问外网:
environment:
HTTP_PROXY: "http://proxy.company.com:8080"
HTTPS_PROXY: "http://proxy.company.com:8080"
NO_PROXY: "localhost,127.0.0.1,.internal.domain"
同时在代码中也要配置:
# 浏览器使用代理
context = await browser.new_context(
proxy={"server": "http://proxy.company.com:8080"}
)
7.4 文件清理策略
长时间运行的Sandbox会积累大量临时文件,需要定期清理:
# 定时清理任务
import schedule
def cleanup_temp_files():
client.shell.exec_command("find /tmp -type f -mtime +1 -delete")
schedule.every().day.at("02:00").do(cleanup_temp_files)
八、未来趋势与展望
8.1 AI原生开发范式的转变
AIO Sandbox代表的是一种新的开发范式:Infrastructure as AI Tool(基础设施即AI工具)。传统上,我们为人类开发者构建IDE、终端、调试器;而在AI时代,这些工具需要API化、标准化、可编排。
未来我们可能会看到:
-
Multi-Agent协作:多个Agent共享同一个Sandbox环境,分工协作完成复杂任务
-
自适应资源分配:根据Agent任务类型,动态调整容器资源(CPU密集型任务增加核心数,内存密集型任务扩容内存)
-
跨云编排:一个任务在AWS的Sandbox中抓取数据,在Azure的Sandbox中训练模型,在阿里云的Sandbox中部署应用
8.2 安全与隔离的演进
当前的Sandbox主要通过Docker容器提供隔离,但未来可能会有更多安全增强:
沙盒内沙盒(Nested Sandboxing)
# 为不可信代码提供额外隔离层
result = client.code.execute_untrusted(
code=user_submitted_code,
isolation_level="strict", # 限制文件系统、网络访问
timeout=30, # 强制超时
resource_limits={"memory": "256MB", "cpu": "0.5"}
)
审计与回溯
所有操作都被记录,支持事后分析:
# 查询某个会话的所有操作
audit_log = client.util.get_audit_log(session_id="abc123")
for entry in audit_log:
print(f"{entry.timestamp}: {entry.action} - {entry.resource}")
细粒度权限控制
基于JWT的权限系统,不同Token有不同权限:
# Admin Token:完整权限
admin_client = Sandbox(base_url="...", token=admin_token)
# Read-only Token:只能读取文件和浏览器截图
readonly_client = Sandbox(base_url="...", token=readonly_token)
8.3 与大语言模型的深度融合
未来的Sandbox可能内置LLM能力,形成"自省式沙盒":
# Sandbox自动检测异常并给出建议
result = client.shell.exec_command(command="rm -rf /")
if result.status == "error":
suggestion = result.ai_suggestion # 内置AI分析错误原因
print(suggestion) # "检测到危险命令,已阻止执行。您可能想要..."
或者支持自然语言操作:
# 不写代码,用自然语言描述需求
client.execute_intent(
"访问example.com,抓取所有产品价格,保存为CSV文件"
)
8.4 边缘计算场景
随着5G和边缘计算的普及,Sandbox可以部署在边缘节点:
-
IoT设备管理:在边缘服务器上运行Sandbox,通过浏览器自动化监控设备Web界面
-
本地数据处理:敏感数据不出边缘节点,在本地Sandbox中完成分析
-
离线AI应用:即使断网,Sandbox内置的能力依然可用
九、开发者建议与最佳实践总结
9.1 快速上手的三步走
如果你是第一次接触AIO Sandbox,建议按照这个路径学习:
第一步:本地试玩(30分钟)
# 启动容器
docker run --security-opt seccomp=unconfined --rm -it -p 8080:8080 \
ghcr.io/agent-infra/sandbox:latest
# 在浏览器访问
open http://localhost:8080/vnc/index.html?autoconnect=true
先通过VNC界面直观感受Sandbox的能力,点点鼠标,开开浏览器,熟悉环境。
第二步:SDK实验(1小时)
pip install agent-sandbox
from agent_sandbox import Sandbox
client = Sandbox(base_url="http://localhost:8080")
# 依次试验每个模块
print(client.shell.exec_command(command="pwd").data.output)
print(client.file.read_file(file="/etc/hostname").data.content)
print(client.browser.screenshot())
通过简单的API调用,理解每个模块的功能和返回格式。
第三步:真实项目(半天)
选一个实际需求,比如"自动化生成周报":
-
用浏览器从项目管理系统抓取本周任务
-
用Jupyter分析任务完成率
-
用文件API生成Markdown报告
经历完整流程后,你就真正掌握了AIO Sandbox。
9.2 性能优化的黄金法则
-
能在容器内做的,就不要拉到外面
# ❌ 不好:数据在网络上传输 html = client.file.read_file(file="/tmp/data.html").data.content markdown = markdownify(html) # 在本地转换 # ✅ 好:转换在容器内完成 client.jupyter.execute_code(code=""" from markdownify import markdownify html = open('/tmp/data.html').read() md = markdownify(html) open('/tmp/data.md', 'w').write(md) """) -
异步优于同步
# 处理100个URL时 # 同步方式:100 * 2秒 = 200秒 # 异步方式:max(2秒) ≈ 5秒(并发处理) -
会话复用降低开销
# ✅ 好:复用HTTP连接 client = Sandbox(base_url="...") for i in range(1000): client.shell.exec_command(...) # 连接池复用
9.3 调试技巧
当遇到问题时,这些技巧能帮你快速定位:
技巧1:VNC大法
# 程序执行到关键位置时,暂停
client.shell.exec_command(command="sleep 3600") # 保持容器运行
# 然后通过VNC连接查看浏览器状态
# http://localhost:8080/vnc/index.html?autoconnect=true
技巧2:日志追踪
# 开启详细日志
import logging
logging.basicConfig(level=logging.DEBUG)
client = Sandbox(base_url="...", timeout=300) # 增加超时方便调试
技巧3:交互式Shell
# 创建持久会话
session_id = client.shell.create_session().data.session_id
# 多次交互
client.shell.exec_command(command="cd /tmp", session=session_id)
client.shell.exec_command(command="ls", session=session_id)
client.shell.exec_command(command="pwd", session=session_id) # 输出 /tmp
9.4 与其他框架的集成建议
LangChain集成
from langchain.tools import BaseTool
class SandboxShellTool(BaseTool):
name = "shell_execute"
description = "在安全沙盒中执行Shell命令"
def _run(self, command: str) -> str:
client = Sandbox(base_url="http://localhost:8080")
return client.shell.exec_command(command=command).data.output
LlamaIndex集成
from llama_index.tools import FunctionTool
def sandbox_read_file(filepath: str) -> str:
"""从沙盒中读取文件内容"""
client = Sandbox(base_url="http://localhost:8080")
return client.file.read_file(file=filepath).data.content
tool = FunctionTool.from_defaults(fn=sandbox_read_file)
AutoGPT集成
# 将Sandbox能力注册为AutoGPT插件
from autogpt.plugins import PluginBase
class SandboxPlugin(PluginBase):
def execute_command(self, command: str) -> str:
return self.sandbox_client.shell.exec_command(command).data.output
十、写在最后:重新定义AI开发工作流
回到文章开头的问题:为什么AI Agent的执行环境一定要是割裂的?
AIO Sandbox用实践给出了答案——不需要。
当浏览器、终端、文件系统、代码执行环境融为一体时,Agent的能力边界被大大拓展。它不再是"只能调API的聊天机器人",而是真正能够感知环境、操作工具、持续学习的智能体。
核心价值总结
-
降低认知负担:开发者不需要在脑海中维护多个环境的状态模型
-
提升开发效率:数据零拷贝、统一API,让90%的胶水代码消失
-
扩展Agent能力:从纯文本交互到全功能OS交互的跨越
-
生产级可靠性:容器化隔离 + 云端伸缩,兼顾安全与性能
适合人群
-
AI应用开发者:需要为Agent构建执行环境的团队
-
自动化工程师:想要统一的RPA/爬虫/测试平台
-
数据科学家:需要端到端自动化的数据处理流程
-
独立开发者:想要快速验证AI创意的个人
开始你的旅程
# 只需一行命令
docker run --security-opt seccomp=unconfined --rm -it -p 8080:8080 \
ghcr.io/agent-infra/sandbox:latest
# 三分钟后,你就拥有了一个完整的AI Agent实验室
技术的本质是解决问题,而不是制造复杂性。AIO Sandbox的设计哲学——"All-in-One",恰恰体现了这一点。它不追求微服务的"形式美学",而是专注于解决AI Agent开发中的真实痛点。
在这个AI Agent爆发的时代,开发范式正在悄然改变。传统的"人写代码→机器执行"模式,逐渐演变为"人提需求→Agent编排→工具执行"。而AIO Sandbox,正是这个新范式的基础设施层。
工具已就绪,创意由你定义。



















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











