






几乎所有异常值检测算法都会建立数据中正常模式的模型,然后根据这些模式的偏差计算给定数据点的异常值。 例如,该数据模型可以是生成模型,例如高斯混合模型,基于回归的模型或基于邻近的模型。 所有这些模型对数据的“正常”行为做出不同的假设。 然后通过评估数据点与模型之间的拟合质量来计算数据点的离群值分数。 在很多情况下,模型可能是算法定义的。 例如,基于最近邻的离群值检测算法根据其最近邻距离的分布对数据点的离群值趋势进行建模。 因此,在这种情况下,假设就是异常值位于距离大部分数据很远的地方。
显然,数据模型的选择至关重要。数据模型的选择不正确可能会导致结果较差。例如,如果数据不适合模型的生成假设,或者没有足够数量的数据点来获取模型的参数,则完全生成模型(如高斯混合模型)可能无法正常工作。同样,如果基础数据是任意聚集的,则基于线性回归的模型可能效果不佳。在这种情况下,数据点可能被错误地报告为异常值,因为对模型的错误假设是不适合的。不幸的是,异常值检测在很大程度上是一个无监督的问题,在这个问题中,异常值的例子不能用于学习特定数据集的最佳模型(以自动方式)。异常值检测的这一方面往往使其比许多其他监督的数据挖掘问题(如标记示例可用的分类)更具挑战性。因此,在实践中,模型的选择常常由分析人员对与应用程序相关的偏差种类的理解所决定。例如,在测量诸如位置特定温度之类的行为属性的空间应用中,假设空间位置中的温度属性的异常偏差是异常的指标是合理的。另一方面,对于高维数据的情况,由于数据的稀疏性,即使数据局部性的定义也可能是不明确的。因此,只有仔细评估该域的相关建模属性后才能构建特定数据域的有效模型。
为了理解模型的重要性,下面研究下Z值在异常值分析中的应用。考虑一组1维定量观测数据,用X1… XN表示,平均值为μ和标准差为σ。数据点Xi的Z值用Zi表示,定义如下:
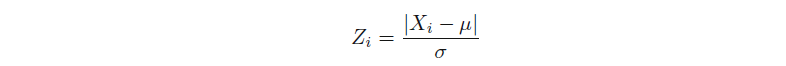
Z值检验计算数据点远离平均值的标准偏差。这为异常值提供了一个很好的参考。一个隐含的假设为数据是服从正态分布,因此,Z值是从标准正态分布中抽取的零均值和方差为1的随机变量。在准确估计分布的均值和标准差的情况下,好的“经验法则”是使用Zi≥3作为异常的代表。然而,在样本数量很少的情况下,分布的均值和标准差不能被有效估计。在这种情况下,Z值测试的结果需要用t分布而不是正态分布进行更仔细的解释。这个问题将在第二章讨论。
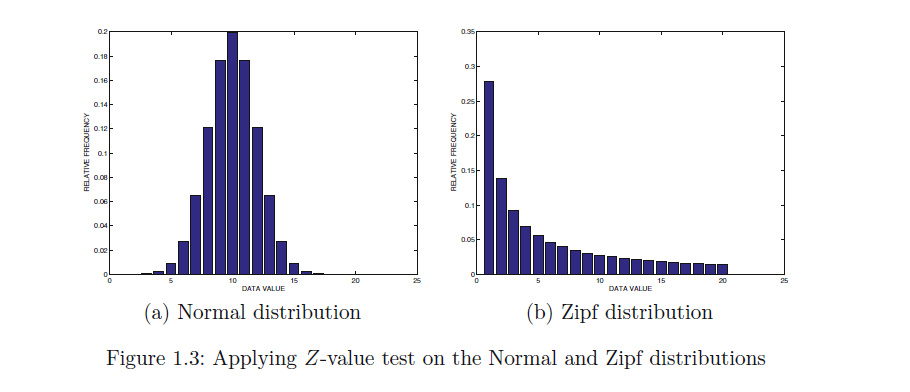
在建模过程中,实践者经常忘记Z值检验隐含的数据服从正态分布这一假设。 当这样的近似值较差时,结果是难以解释的。举个例子,两组数据的频率直方图分别为下图1.3(a)与1.3(b),当数据为1.3(a)时,在第一种情况下,直方图采用(μ,σ)=(10,2)的正态分布进行采样,在第二种情况下,从分布为1 / i函数中采样。很明显,大部分数据处于正态分布的范围[10-2 * 3,10 + 2 * 3]内,并且所有位于该范围之外的数据点都可以被认为是异常的。因此,Z值测试在这种情况下工作得非常好。在第二种情况下,异常情况并不十分清楚,尽管具有非常高的值(例如20)的数据点可能被认为是异常的。在这种情况下,数据的平均值和标准差分别是5.24和5.56。因此,Z值检验不会将任何数据点声明为异常(对于阈值为3),尽管它确实接近。无论如何,至少从概率可解释的角度来看,第二种情况Z值的重要性并不是很有意义。这表明,如果在建模阶段出错,可能会导致对数据的错误理解。这样的测试通常被用作一种启发式方法,即使对于远离正态分布的数据集也能提供异常值分数的粗略概念,仔细解释这些分数是非常重要的。
Z值检验即使作为启发式的方法,也并不是针对所有例子,若Z值检验应用于1.1节的图1.1(a)那个例子中,则A点判断为(非常)正常点,这一判断显然是错误的。因此,模型的有效性取决于所用测试的选择以及如何应用。
模型的最佳选择通常基于特定的数据。这需要在选择模型之前对数据本身有一个很好的理解。 例如,一个基于回归的模型最适合在图1.4的数据分布中找出异常值,其中大部分数据沿线性相关平面分布。 另一方面,聚类模型更适合图1.1(上一节)所示的情况。 给定数据集的模型选择不当可能会导致较差的结果。 因此,发现异常值的核心原则是基于对给定数据集中正常模式结构的假设。 显然,“正常”模型的选择很大程度上取决于分析人员对该特定领域的数据模式的理解。 这意味着分析师对数据表示的语义理解通常是有用的,尽管这在实际设置中通常是不可能的。
模型选择中有许多折衷。 一个具有太多参数的高度复杂的模型将很可能导致过度拟合。 一个简单的模型,它对数据有很好的直观理解(也可能是分析师对正在寻找的东西的理解),可能会带来更好的结果。 另一方面,一个过于简化的模型,可能会将正常数据判别为异常值。 选择数据模型的最初阶段也许是异常分析中最关键的一步。 本书将重复关于数据模型影响的主题,并举例说明。















 3354
3354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









