







深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎大白在之前写过 《深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解》对 Yolov4的相关基础知识做了比较系统的梳理,但Yolov4后不久,又出现了Yolov5,虽然作者没有放上和Yolov4的直接测试对比,但在COCO…![]() https://zhuanlan.zhihu.com/p/172121380进击的后浪yolov5深度可视化解析 - 知乎0 摘要论文:暂无 github: https://github.com/ultralytics/yolov5 我注释版本github: https://github.com/hhaAndroid/yolov5-comment 关于yolov5是否应该赋予这个名称,网上众说纷纭, 如何评价YOLOv5?讨论非常…
https://zhuanlan.zhihu.com/p/172121380进击的后浪yolov5深度可视化解析 - 知乎0 摘要论文:暂无 github: https://github.com/ultralytics/yolov5 我注释版本github: https://github.com/hhaAndroid/yolov5-comment 关于yolov5是否应该赋予这个名称,网上众说纷纭, 如何评价YOLOv5?讨论非常…![]() https://zhuanlan.zhihu.com/p/183838757如何评价YOLOv5? - 知乎看到YOLOv5出来了就去看了一下,虽然很多事情并不清楚,自己也只是去使用而不是研究,但是有几个问题想说…
https://zhuanlan.zhihu.com/p/183838757如何评价YOLOv5? - 知乎看到YOLOv5出来了就去看了一下,虽然很多事情并不清楚,自己也只是去使用而不是研究,但是有几个问题想说…![]() https://www.zhihu.com/question/399884529
https://www.zhihu.com/question/399884529
yolov5没有论文,主要就结合着代码来分析一下,使用了mosaic,图片缩放,focus,csp,gious,fpn+pan,放缩的网络结构,放缩的网络结构让模型更加灵活,一共有四个版本,s,m,l,x,遗传算法搜超参,自适应的anchor,ema。非常建议读深度眸的解析版本,这算是解析很透彻的版本,核心在正负样本上做了优化,yolo系列的正负样本定义的代码基本都在build_targets函数里。不同于yolov3,v4的正负样本定义,一个gt只和iou最大的anchor匹配,v5中的正样本不再通过iou筛选,而是通过宽高比筛选,在三个预测层上也不再只有一个gt的anchor负责预测gt,而是可能存在多个,类似于mmdet给fcos找正样本的写法,三个预测层是可能存在gt的不同尺度预测的,但是也是经过宽高比筛选的,而且网格单元也从1个扩展到3个,但是也可能会引入质量较低的正样本.
1.网络结构变化
1.1 mosaic数据增强

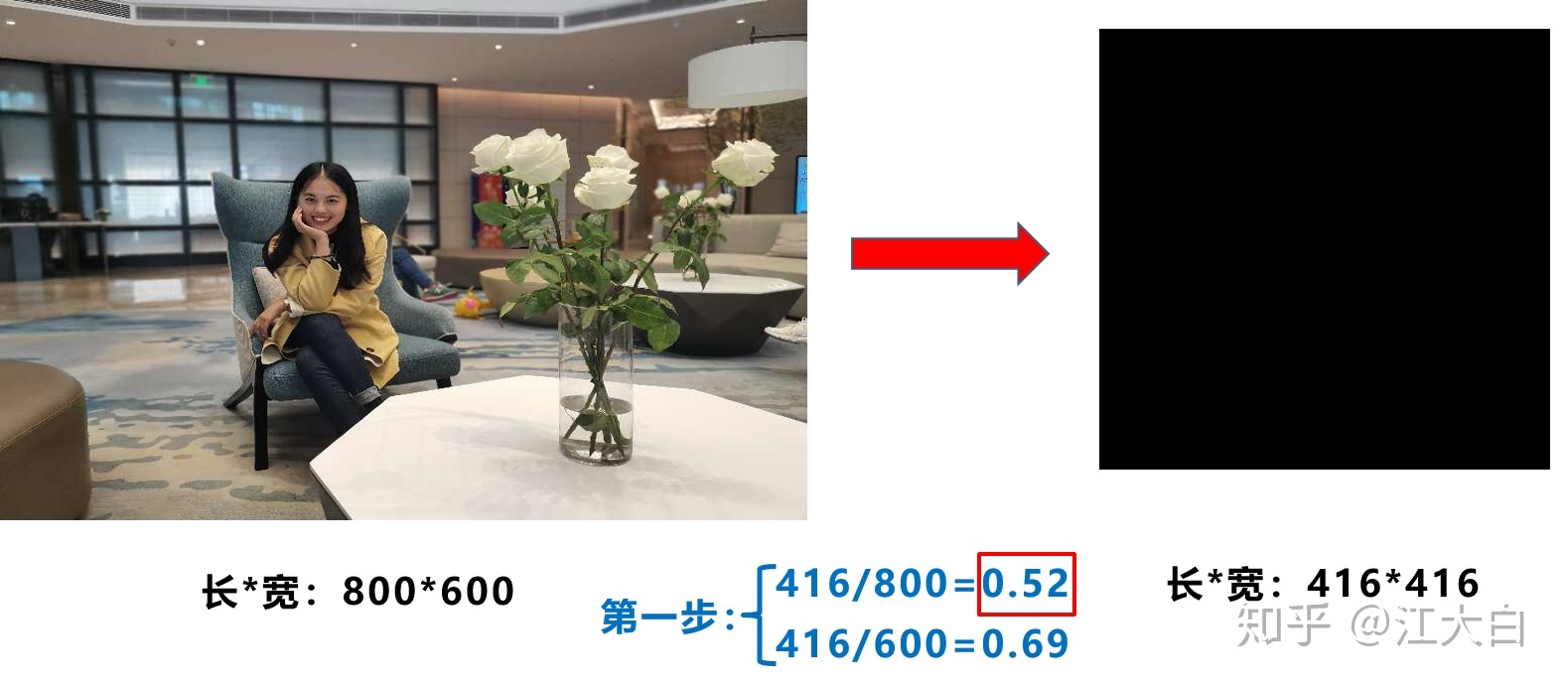
1.2 自适应图片缩放
这块的逻辑其实是日常训练中很常用的逻辑,面向生产除了端到端的模型一般我们对输入都会做处理的。


第一张图是yolov1-v4的方式,先padding再输入,保证了输入尺寸是416*416或者其他的32的倍数,下采样的feature map是奇数就可以,在v5的前向推理中,长宽比不一定是固定的,只要和最长边resize到416之后的尺寸一致就可以,这样填充的边也少了很多,训练保持一致,推理变了。


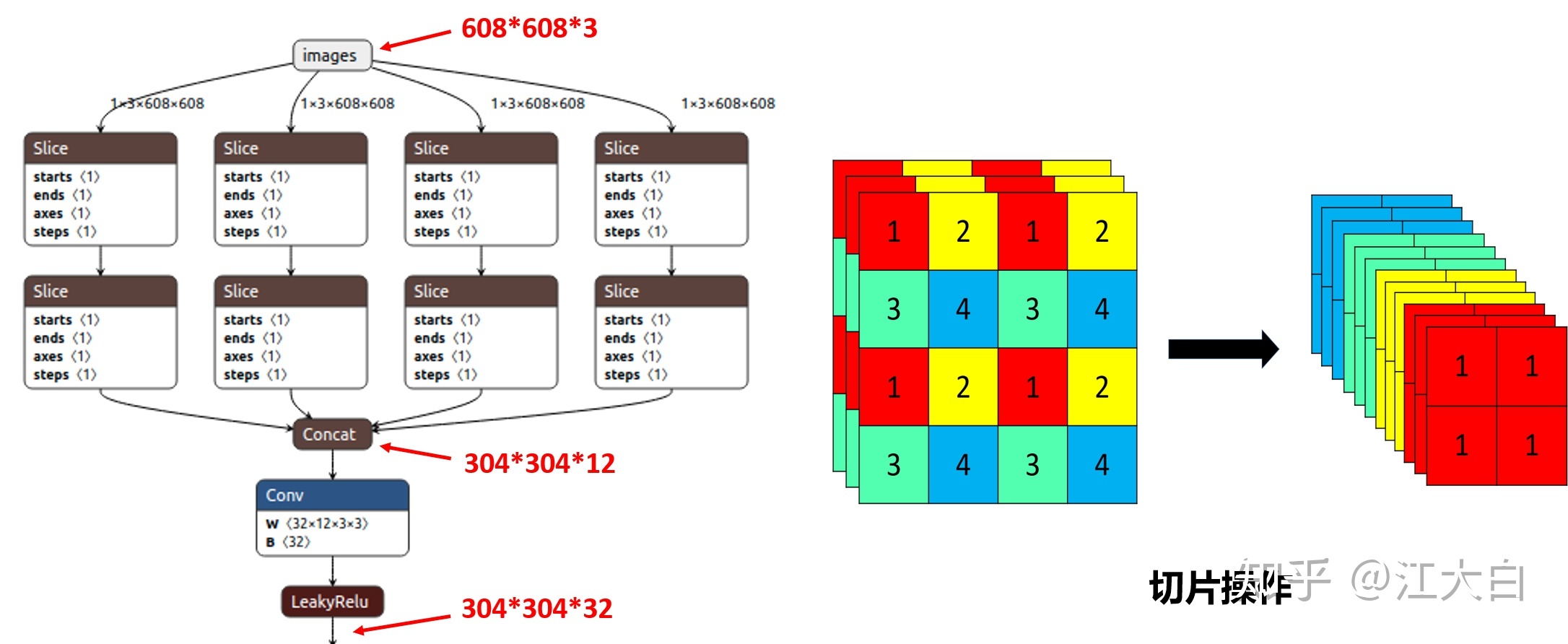
1.3 focus
# focus模式的下采样
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
直接看代码,就是将c,w,h变成了4c,w/2,h/2.但是注意,取的时候是隔一个取一次。如下,输入是608*608没问题的,只是取的时候只取到了一般,再concat。
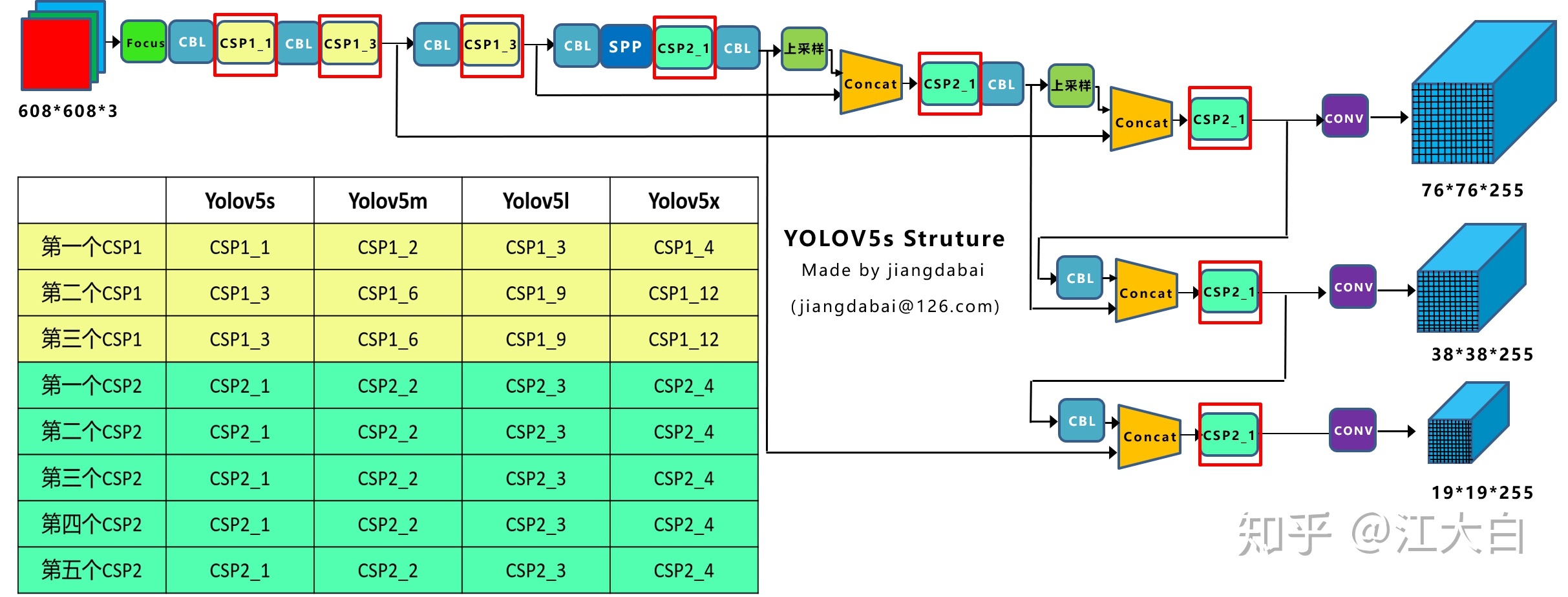
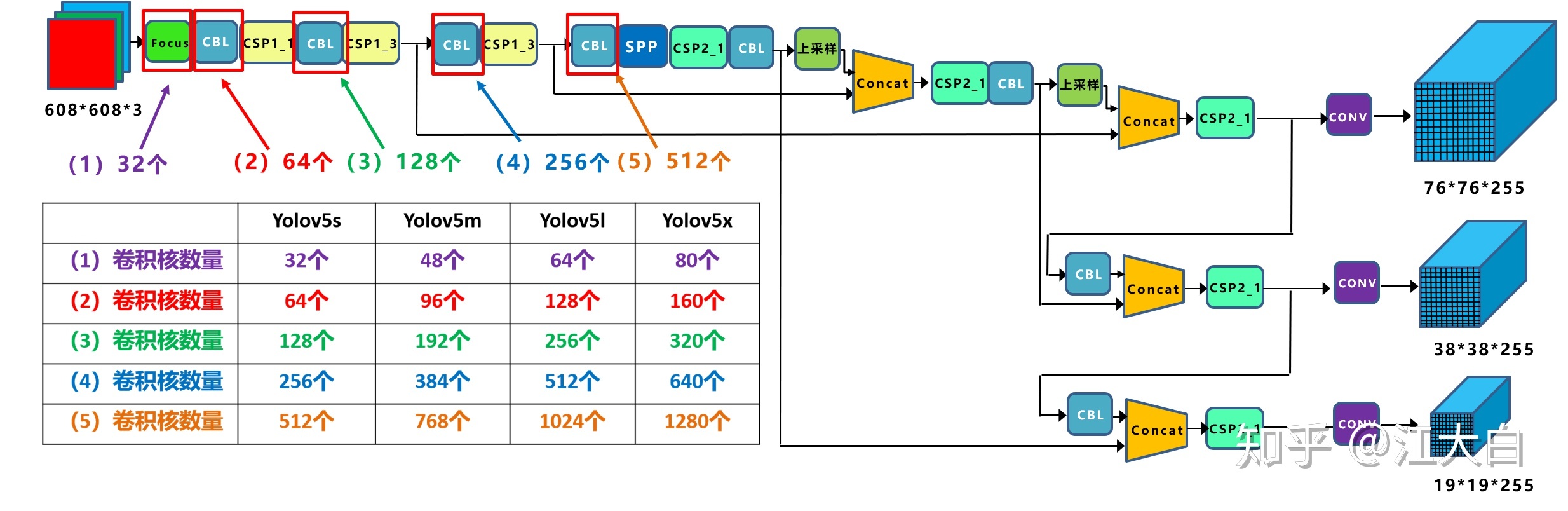
1.4 放缩的网络结构
这块可以看上面江大白的知乎解析,很直观了,网络采用了efficientdet的思路,做了四种结果,分别是5s,5m,5l,5x,s最小结构,l是标准结构。

1.5 自适应的anchor
yolov3是提前在数据上用iou计算聚类anchor,v5考虑到有数据增强,是放在训练中去计算的,当然也不是看iou的。
2.正负样本分类
这块很重要,v5和v1-v4的正负样本分配是不一样的。yolov3中是经典的正样本匹配,每个gt都有一个网格单元中的anchor与之匹配,匹配规则是iou,并且某个gt只会在三个特征图的某一层进行预测,不会同时出现在三个特征图上,这里和传统的fpn多尺度预测以及fcos这种fpn分层预测都是不太一样,很粗暴。fcos和atss中都表明,增加高质量正样本anchor可以显著加速收敛。
1.对于任何一个特征图输出层,不再基于max iou的匹配规则,采用wh shape规则匹配,也就是该gt和当前的anchor计算宽高比,如果宽高比大于设定阈值,则说明该gt和anchor的匹配度不够,将该gt暂时丢掉,至少在这一特征图输出层认为其实背景,负样本。(注意计算预测框和gt以及anchor和gt是两种写法)
2.对于剩下的gt,计算其落在哪个网格单元内,找出其最近的两个网格,将这三个网格都认为是负责改gt的预测,这样相比较原本的正样本分配,v5的正样本至少增长了3倍。


看一下上面这组图就更加清晰了,第一张图是stride=8,对检测小物体友好,第二张图是stride=16,第三张图是stride=32,红色表示gt,黄色表示该位置正样本anchor,第一张图由于检测目标过大,超过了wh shape,这里阈值为4,也就是anchor比gt的max(w,h)的比值大了4倍,anchor直接变负样本了,第二张图,黄色框多了,第三张图中黄色框更多,并且黄色框不仅是该gt中心的网格单元,还是其附近的。
有几个结论:
1.gt可以跨层预测,不止有一个层,可能三个层中都有预测gt的不同框
2.gt的匹配个数从1增长到3-9之间,三个网格单元,每个1个anchor,至少3个anchor正样本。
3.匹配规则由iou变成了wh shape,因此wh不再是整图大小,而是0-4,有阈值限制。
代码如下:
# 核心操作
# 其和常规的yolov3 loss完全不同
# 其label没有跨层,对于任何一个bbox,首先三个输出层都有,对于任何一层
# 首先计算当前bbox和当前层anchor的匹配程度,算法不再是iou,而是shape比例
# 如果anchor和bbox的宽高比差距大于4,也就是认为不匹配,此时暂时把bbox删除,其实就相当于当做背景了
# 然后在对bbox计算落在那个网格,也就是说对于某个bbox落在的网格内部(注意此时落在网格也不再是一个,而是附近的多个,增加正样本数),所有anchor都算Loss
# 不存在取最大iou对应的anchor计算loss的设置
# 所以可能存在有些bbox在三个都预测的情况
# 也没有conf分支忽略阈值的操作
def build_targets(p, targets, model):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
# targets nx6,其中n是batch内所有的图片label拼接而成,6的第0维度表示当前是第几张图片的label =index classid xywh
na, nt = det.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch, ttar = [], [], [], [], []
gain = torch.ones(7, device=targets.device)
# anchor=3个数,将target变成3xtarget格式,方便后面算Loss
# anchor索引,后面有用,用于表示当前bbox和当前层的哪个anchor匹配
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt)
# 先repeat和当前层anchor个数一样,相当于每个bbox变成了三个,然后和3个anchor单独匹配
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # 网格中心偏移
# 附近的4个网格
off = torch.tensor([[0, 0], [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(det.nl): # 三个输出分支
anchors = det.anchors[i] # 当前分支anchor
# p是网络输出值
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # 1 1 特征图大小 特征图大小 特征图大小 特征图大小 1
# targets的xywh本身是归一化尺度,故需要变成特征图尺度
t = targets * gain
if nt:
# 计算当前target的wh和anchor的wh比例值
# 如果最大比例大于预设值model.hyp['anchor_t']=4,则说明当前target和anchor匹配度不高,不应该强制回归,把target丢弃
# 主要是把shape和anchor匹配度不高的label去掉,这其实也说明该物体的大小比较极端,要么太大,要么太小,要么wh差距很大
# 基于shape过滤后,就会出现某些bbox仅仅和当前层的某几个anchor匹配,即可能出现某些bbox仅仅和其中某个匹配,而不是和当前位置所有anchor匹配
r = t[:, :, 4:6] / anchors[:, None] # wh ratio 不考虑xy坐标
j = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter 注意过滤规则是没有考虑xy的,也就是当前bbox的wh是和所有anchor计算的
# https://www.kaggle.com/c/global-wheat-detection/discussion/172436
# 网络的3个附近点,不再是落在哪个网络就计算该网络anchor,而是依靠中心点的情况
# 选择最最近的3个网格,作为落脚点,可以极大增加正样本数
# 也就是对于保留的bbox,最少有3个anchor匹配,最多9个
gxy = t[:, 2:4] # grid xy label的中心点坐标
gxi = gain[[2, 3]] - gxy # inverse
# 这两个条件可以选择出最靠近的2个邻居,加上自己,就是三个邻居
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
# 5是因为预设的off是5个,现在选择出最近的3个(包括0,0也就是自己)
t = t.repeat((5, 1, 1))[j] # (label个数x3,7) 附近的2个网格anchor,都算该bbox的anchor点
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # 选择出最近的三个
else:
t = targets[0]
offsets = 0
# 按照yolov3,则直接(gxy-0.5).long()即可得到网格坐标
# 但是这里考虑了附近网格,故offsets不再是0.5而是2个邻居
# 所以xy回归范围也变了,不再是0-1,而是0-2
# 宽高范围也不一样了,而是0-4,因为超过4倍比例是算不匹配anchor,所以最大是4
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long() # 当前label落在哪个网格上
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj, gi)) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
ttar.append(torch.cat((gxy, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch, ttar

整体来看,yolov5还是有不少改进的,很多人反应代码写的比较乱,后续有时间好好搞搞这块代码,scaled-yolov4采用和yolov5一样的正负样本分配以后,在coco上的map也很猛,直接就到50%+了,yolov5和yolov4很多地方都存在相互借鉴。















 2087
2087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









