




一、引言
在当今科技飞速发展的时代,AI(人工智能)已经成为了热门话题,而AI模型和大模型更是其中的核心概念。对于初级程序员来说,了解这些概念不仅能拓宽技术视野,还能为未来的职业发展打下坚实的基础。那么,究竟什么是AI模型和大模型呢?让我们一起揭开它们的神秘面纱。
二、AI模型基础
(一)AI模型是什么
AI模型是使用数据来训练计算机模拟人类思维的一种程序工具。简单来说,它是一种算法,能够根据数据进行学习,并根据这些学习做出预测或分类决策。例如,图像分类模型能够识别照片中的物体,语言模型可以进行对话或者生成文章。
AI模型主要包括机器学习模型和深度学习模型。机器学习模型通常用于结构化数据(如表格数据),而深度学习模型则适合处理图片、语音、文本等复杂的非结构化数据。深度学习使用多层神经网络对数据进行处理,这些神经网络模仿了人类大脑的学习方式。
(二)AI模型的基本类型
- 监督学习:在这种类型中,模型学习已标记的数据,即数据中包含输入和期望的输出。常见的算法包括线性回归、支持向量机(SVM)、决策树等。
- 无监督学习:在无监督学习中,模型没有标记数据,目的是发现数据中的模式和关系。常见的无监督学习算法包括K均值聚类、主成分分析(PCA)等。
- 强化学习:强化学习是通过环境的反馈和奖励来指导模型的行为,通常应用于游戏、机器人控制等领域。
- 深度学习:深度学习是使用神经网络进行数据学习的过程。常见的深度学习模型有卷积神经网络(CNN)和循环神经网络(RNN)。
(三)AI模型的构成要素
要构建一个AI模型,需要以下几个主要构成要素:
- 数据集:数据是训练AI模型的核心。高质量的数据集对模型的表现至关重要。
- 特征工程:特征是数据中的重要属性。特征工程是提取和处理数据中特征的过程,目的是使模型更好地理解数据。
- 模型算法:算法是AI模型的核心,用于将数据映射到输出的结果。
- 训练过程:训练是使用数据来调整模型参数的过程,使得模型能够适应数据并做出准确的预测。
- 验证与测试:模型训练完成后,需要使用验证集和测试集对模型进行评估,确保其性能稳定。
(四)AI模型代码示例 - 线性回归
下面我们通过一个简单的例子来了解如何使用Python构建一个线性回归模型。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 创建一个简单的数据集
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
y = np.array([3, 4, 2, 5, 6, 7, 8, 9, 10, 11])
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
# 绘制训练数据和预测结果
plt.scatter(X, y, color='blue', label='Actual data')
plt.plot(X_test, y_pred, color='red', label='Predicted line')
plt.xlabel('X values')
plt.ylabel('Y values')
plt.legend()
plt.show()三、大模型详解
(一)大模型的定义
大模型通常使用更深、更宽的神经网络,例如深度卷积神经网络(如ResNet、Inception、EfficientNet)或大型变换器模型(如BERT、GPT)等。这些模型具有数百万到数十亿、千亿个参数,可以捕获更多的特征和复杂性。大模型常用于自然语言处理、计算机视觉、语音识别等需要高度抽象和复杂模式识别的任务。大模型通常需要更多的计算资源来训练和推理,这包括更多的GPU/TPU、更大的内存等。所以在部署时,大模型通常需要更多的计算能力,可能需要特殊的硬件支持才能高效部署。
(二)大模型的发展历程
大模型的发展经历了多个阶段:
- 萌芽期(1950年 - 2005年):是以CNN为代表的传统神经网络模型阶段。1956年,计算机专家约翰·麦卡锡提出“人工智能”概念,AI发展由最开始基于小规模专家知识逐步发展为基于机器学习。1980年,卷积神经网络的雏形CNN诞生。1998年,现代卷积神经网络的基本结构LeNet - 5诞生,为自然语言生成、计算机视觉等领域的深入研究奠定了基础。
- 沉淀期(2006年 - 2019年):是以Transformer为代表的全新神经网络模型阶段。2017年,Google颠覆性地提出了基于自注意力机制的神经网络结构——Transformer架构,奠定了大模型预训练算法架构的基础。2018年,OpenAI和Google分别发布了GPT - 1与BERT大模型,意味着预训练大模型成为自然语言处理领域的主流。
- 爆发期(2020年 - 2023年):是以GPT为代表的预训练大模型阶段。2020年,OpenAI公司推出了GPT - 3,模型参数规模达到了1750亿。2022年11月30日,搭载了GPT3.5的ChatGPT横空出世,迅速引爆互联网。2023年3月,最新发布的超大规模多模态预训练大模型——GPT - 4,具备了多模态理解与多类型内容生成能力。
- 应用加速落地期(2024年至今):国家互联网信息办公室公开发布第三批境内深度合成服务算法备案清单,更多大模型应用开始加速落地。
(三)大模型的架构
以Transformer架构为例,它是大模型的重要基础。Transformer架构通过引入注意力机制彻底改变了序列建模的方式,使得长距离依赖问题得到了有效解决,并且极大提高了并行计算效率。其关键组件包括:
- 编码器:负责将输入序列转换成高维向量表示。
- 解码器:根据编码器生成的信息预测输出序列。
- 位置编码:给定没有顺序信息的数据,添加绝对或相对的位置信息来帮助模型学习序列中的时间关系。
- 多头注意力层:允许模型同时关注多个不同方面的重要特征。
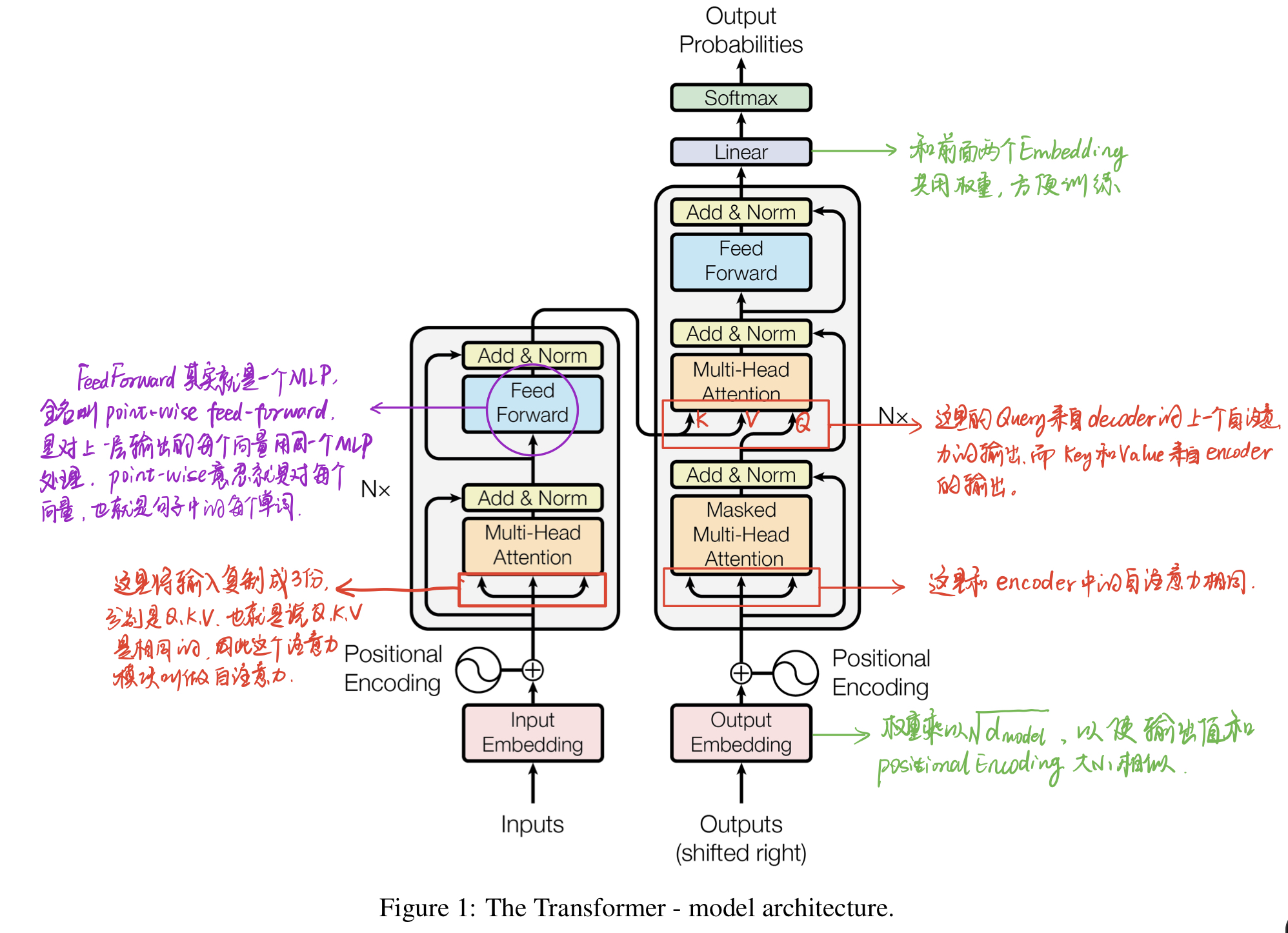
(四)大模型的应用场景
大模型在各个领域都有广泛的应用:
- 自然语言处理:如文本生成、机器翻译、问答系统等。例如,ChatGPT能够进行自然语言对话,生成高质量的文本内容。
- 计算机视觉:图像识别、目标检测、图像生成等。比如,Stable Diffusion可以根据文本描述创作图片。
- 医疗领域:辅助医生进行疾病诊断、治疗方案制定,以及药物研发等。例如,基于AI大模型的智能辅助诊断系统可以通过分析患者的医学影像和病历数据,辅助医生进行癌症诊断、肺炎诊断等复杂疾病的诊断。
- 金融领域:风险评估、信用评估、智能投顾服务等。基于AI大模型的智能风控系统可以通过分析海量数据,实时监测金融市场的风险变化,帮助金融机构避免损失。
(五)大模型代码示例 - ChatGLM调用
以下是以ChatGLM模型为例,完成一次大模型的API调用的代码。
from transformers import AutoTokenizer, AutoModel # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3 - 6b", trust_remote_code=True) model = AutoModel.from_pretrained("THUDM/chatglm3 - 6b", trust_remote_code=True, device='cuda') model = model.eval() # 输入问题并获取回答 response, history = model.chat(tokenizer, "你好", history=[]) print(response)四、AI模型与大模型的关系
(一)联系
大模型是AI模型的一种,它继承了AI模型的基本概念和技术,是AI模型在参数规模、计算能力和应用效果上的进一步发展。大模型通过大规模数据训练和强大的计算资源支持,能够实现更复杂的任务和更高的性能。
(二)区别
- 参数规模:AI模型的参数数量相对较少,而大模型具有数百万到数千亿个参数。
- 计算资源需求:AI模型对计算资源的要求较低,而大模型需要更多的GPU/TPU、更大的内存等。
- 应用场景:AI模型适用于一些相对简单的任务,而大模型更擅长处理复杂的、需要高度抽象和模式识别的任务。
五、总结
通过本文的介绍,相信初级程序员们对AI模型和大模型有了更深入的了解。AI模型是基础,大模型是在AI模型基础上的发展和突破。在实际应用中,我们可以根据任务和资源限制选择适当规模的模型。希望大家能够在未来的学习和工作中,不断探索和应用这些技术,为AI领域的发展贡献自己的力量。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











