








标题:基于Tree-LSTM的连接顺序选择强化学习
***摘要***:连接顺序选择(Join order selection, JOS)——为SQL查询找到最优连接顺序的问题——是数据库查询优化器的主要关注点。这个问题很难,因为它的解空间很大。彻底遍历解决方案空间是非常昂贵的,这通常与启发式修剪相结合。尽管经过了数十年的努力,传统的优化器在处理复杂的SQL查询时仍然存在低可伸缩性或低准确性的问题。最近使用深度强化学习(DRL)的尝试,通过用固定长度的手动调整特征向量编码连接树,为JOS提供了一些启发。然而,使用固定长度的特征向量不能捕获连接树的结构信息,这可能会产生较差的连接计划。此外,在处理模式更改(例如,添加表/列)或SQL查询中常见的多别名表名时,还可能导致对神经网络进行重新训练。
在本文中,我们提出了一种新的学习优化器RTOS,它使用具有树状结构长短期记忆(LSTM)的强化学习进行连接顺序选择。RTOS主要在两个方面改进了现有的基于DRL的方法:(1)采用图神经网络捕获连接树的结构;(2)支持对数据库模式和多别名表名的修改。在Join Order Benchmark (JOB)和TPC-H上的大量实验表明,RTOS优于传统的优化器和现有的基于DRL的学习优化器。特别是,与动态规划相比,RTOS为JOB生成的计划平均为101%的(估计)成本和67%的延迟(即执行时间),动态规划可以在连接计划上产生最先进的结果。
介绍
Join order selection (Join order selection, JOS)是一个关键的DBMS优化问题,已经被广泛研究了几十年[1],[26],[32],[36],[38]。传统方法通常基于基数估计和成本模型,使用一些修剪技术搜索所有可能连接顺序的解空间。基于动态规划(DP)的算法[10]通常选择最佳计划,但成本非常高。启发式方法,如GEQO[3]、QuickPick-1000[38]和GOO[4],可以更快地计算计划,但通常产生较差的计划。
最近,基于机器学习(ML)和深度学习(DL)的学习优化器方法[11],[15]在数据库社区中很流行。特别是,基于深度强化学习(DRL)的方法,如ReJOIN[20]和DQ[16],已经显示出有希望的结果——它们可以生成与本地查询优化器相当的计划,但在学习后执行速度要快得多。
-
Shortcomings of Existing DRL-based Methods
现有的基于DRL的学习优化器方法(例如,DQ和ReJOIN)将连接树编码为固定长度的向量,其中向量的长度由数据库中的表和列决定。这将导致两个问题:(1)这些向量不能捕获连接树的结构信息,这可能导致较差的计划;(2)当数据库模式发生变化(例如,添加列/表)或多别名表名时,学习优化器将失败,这需要使用不同长度的新输入向量,然后重新训练神经网络。让我们通过一个例子进一步说明。
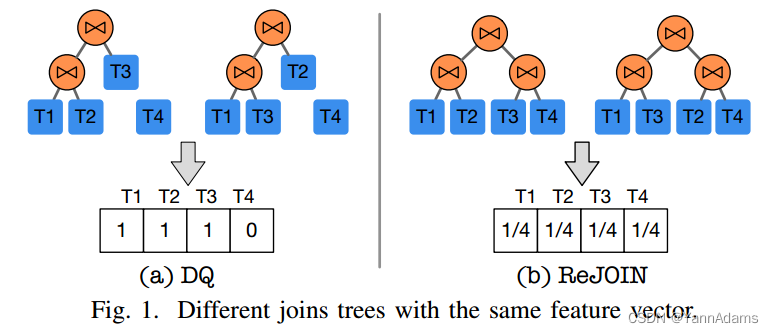
Example 1:考虑一个包含4个表、
、
、
的数据库。DQ[16]采用one-hot编码(1表示有表在树中,0表示表不在树中)对联接树进行编码:
和
具有相同的特征向量[1,1,1,0],如图1(a)所示。
ReJOIN[20]使用的深度表连接构造特征向量:和
有相同的特征向量
=
,每个表的深度是d = 2,如图1(b)所示。
-
Key Observation
例1表明,使用已有的学习器可以将不同连接顺序的连接树编码为相同的特征向量;也就是说,它们只考虑连接的静态信息(如表和列),而不能捕获连接树的结构信息。直观地说,一个更好的学习器还应该理解不同连接树的不同结构信息。
-
Our Methodology
基于上述观察,我们提出了RTOS,一种使用树状结构长短期记忆(Tree-LSTM)的新型学习优化器[35]。RTOS为JOS训练一个DRL模型,该模型可以通过学习以前执行的查询来自动改进未来的JOS。
Tree-LSTM是图神经网络的一种。基于图结构数据的GNN在社交网络[7]和知识图[6]等各种应用中表现出优异的性能[40]。与以序列数据作为输入的传统LSTM结构不同,Tree-LSTM直接读取树结构作为输入,并输出树的表示形式。我们使用基于树的表示来解决缺点(1)。此外,我们使用动态图特征来支持模式更改和多别名,以克服缺点(2)。
我们的基本目标是生成低延迟(即执行时间)的计划。然而,估计延迟要比成本昂贵得多(从成本模型估计)。我们首先使用成本作为反馈来训练模型,然后切换到延迟作为反馈进行微调。与[21]只使用延迟作为反馈不同,我们通过多任务学习将这两种反馈视为两个独立的任务,但共享一个共同的表示[29]。这样,通过将目标损失函数设置为这两个问题的加权和,模型可以同时学习成本和延迟。
有人可能会担心,训练一个深度神经网络并不便宜,因为它需要大量的训练数据和与神经网络交互的反馈,这在DQ[16]中也有报道。然而,为数据库训练DL模型通常被认为是离线操作,一旦训练完成,将其用于预测是非常有效的。
-
Contributions and Roadmap
我们提出了使用DRL和Tree-LSTM的RTOS来实现JOS。本文的主要贡献和研究思路如下:
-
我们给出了RTOS的概述。(第二节)。
-
我们引入中间连接计划(即连接森林)的表示,它利用Tree-LSTM将给定查询的表示和连接森林中的连接树结合起来。(第三节)。
-
我们描述了如何采用Deep Q learning[23]来解决JOS的DRL问题。(第四节)。
-
我们将讨论RTOS如何处理数据库修改,例如添加列/表,以及处理多别名。(第五部分)。
-
在两个流行的基准测试,Join Order Benchmark[17]和TPC-H上进行的大量实验表明,RTOS通过产生更低延迟和成本的连接计划,优于现有的解决方案。(第六部分)。
RTOS概述
我们主要关注SPJ查询,类似于DQ[16]。RTOS使用DRL和Tree-LSTM训练学习优化器。给定一个SQL查询,它输出一个连接计划。DBMS将执行此连接计划并发送反馈,然后RTOS将其作为新的训练样本来改进自身。
A. The Working Mechanism
1)RTOS中的深度强化学习(DRL):强化学习(RL)是agent(例如,优化器)通过与environment(例如,DBMS)的试错交互从反馈中学习的一种方法,通常包含深度学习(DL)。对于每个state(例如,中间连接计划),RTOS读取该计划并利用Tree-LSTM[35]来计算每个action(例如,哪两个表应该连接以使当前状态更完整)的估计长期reward(例如,来自DBMS的反馈)。然后,它选择具有最大reward(最小成本)的预期最优action。当所有的表都连接起来时(即,生成一个完整的连接计划),连接计划将被发送到DBMS执行。然后,RTOS将从DBMS获取反馈来训练Tree-LSTM并更新优化器。
2)延迟和成本的反馈:我们使用来自DBMS的两种类型的信息作为反馈:延迟和成本。延迟是连接计划的实际执行时间,这是优化的基本目标。但是,它只能在执行SQL查询之后获得,这是非常昂贵的。成本是对延迟的估计,通常由成本模型给出,而且往往是不准确的。
除了利用成本的速度优势训练学习器外,我们还使用了延迟反馈,具体步骤如下。
-
Cost training
成本训练首先使用成本作为reward来训练RL模型。在此阶段完成后,我们的模型可以生成一个以成本为指标的好的计划。同时,神经网络对数据库具有基于成本的理解。
-
Latency tuning
延迟调优进一步将延迟作为反馈合并,并将其作为新的优化目标。通过前一步的成本训练,神经网络已经对数据库有了大致的了解。在此基础上,我们利用延迟信息进行连续训练。因此,这一步可以看作是微调。
3)增量式维护模型:深度强化学习已被广泛应用于动态环境中,因为只有state-action对的reward可能会随着时间而变化。对于我们的问题,我们记录所有执行的查询,并使用执行结果(成本,延迟)在后台更新我们的模型。通过这样做,我们的模型可以实时地适应改变。我们还在第五节中讨论了“添加列”和“添加表”两种情况。
B. The RTOS Framework
非正式地说,连接过程中的状态是一个连接森林,它可以由几个连接树组成。

Example 2:考虑图2中的一个SQL查询。它的初始状态是一个连接森林,有四棵连接树、
、
和
。第一个中间状态是一个连接森林,它有三个连接树:
、
和
。第二种中间状态是一个有两个连接树的连接森林:
,
。终止状态是只有一个连接树的完整计划。
接下来我们展示它的框架,如图3所示。
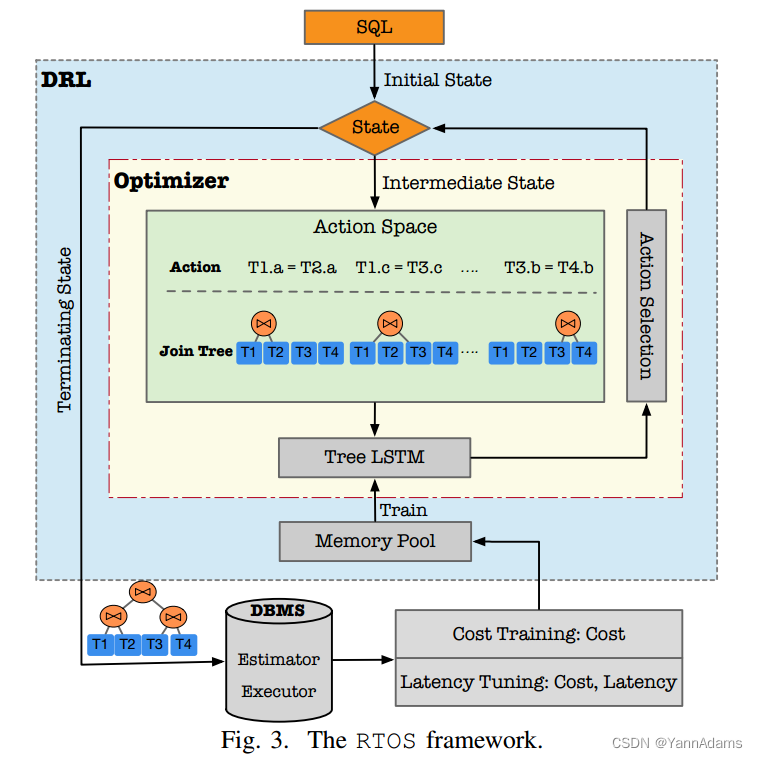
1)DRL优化器:学习优化器。
State维护连接进程的当前state信息。Terminating State是一个连接树,所有表都连接在一起,它将被转换为查询计划并传递给DBMS执行。Intermediate state是保存部分连接计划的state。将Intermediate state传递给Optimizer以选择现在应该执行的action,并且根据所选action更新State本身。
Optimizer对应于RL中的agent,是整个系统的核心部分。对于给定的state,可以将每个候选连接条件视为一个action。Action Space包含所有可能的actions和相应的连接树(例如,{( =
,
), …})。对于action space中的连接树,我们将使用Tree-LSTM来表示它们,并得到相应的估计长期reward。Action Selection从Tree-LSTM中获取每个连接树的结果,并选择最优连接树对应的action:

Memory Pool记录RTOS生成的计划状态和DBMS的反馈。DRL需要训练数据来训练神经网络。常用的做法是使用重放内存[23]来记录状态和系统反馈。我们在这里使用一个内存池,并从中抽取训练数据样本来训练Tree-LSTM。
2)DBMS:RTOS为给定的查询生成一个连接计划,然后将其传递给DBMS,例如PostgreSQL。我们使用来自DBMS的两个组件,一个Estimator和一个Executor。Estimator可以在不执行Executor的情况下使用统计信息来估计成本,从而给出计划的成本。
获取每个连接条件的延迟是很困难的。为了降低实现难度,使系统更容易迁移到其他系统,我们采用了一种经典的方法,ReJoin[20]和DQ[16]中也使用了这种方法。我们将中间状态的每一步反馈(reward)设为0,将终止状态反馈为整个计划的成本(延迟)。
state的表示
ML/DL方法的性能严重依赖于数据表示(或特征),通常由向量表示。在我们的例子中,我们需要学习查询、列、表和连接树的表示。为了学习state s的表示R(s),我们需要同时考虑当前状态(即连接森林F)和它的目标状态(即SQL查询q)。state s的表示R(s)是连接森林F的表示R(F)和查询q的表示R(q)的连接;即
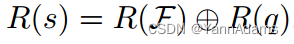
在接下来的内容中,我们将首先将查询q的表示R(q)描述为向量(第III-A节)。然后,我们将给定查询的列和表表示为向量(第III-B节)。我们将介绍Tree-LSTM(第III-C1节),并讨论如何使用Tree-LSTM来学习连接树的表示,基于列和表的表示(第III-C2节)。我们通过给出连接森林F的表示R(F)和state s的表示R(s)来结束本节(第III-C3节)。
我们在表I中总结了本文中使用的符号。
A. Representation of Queries
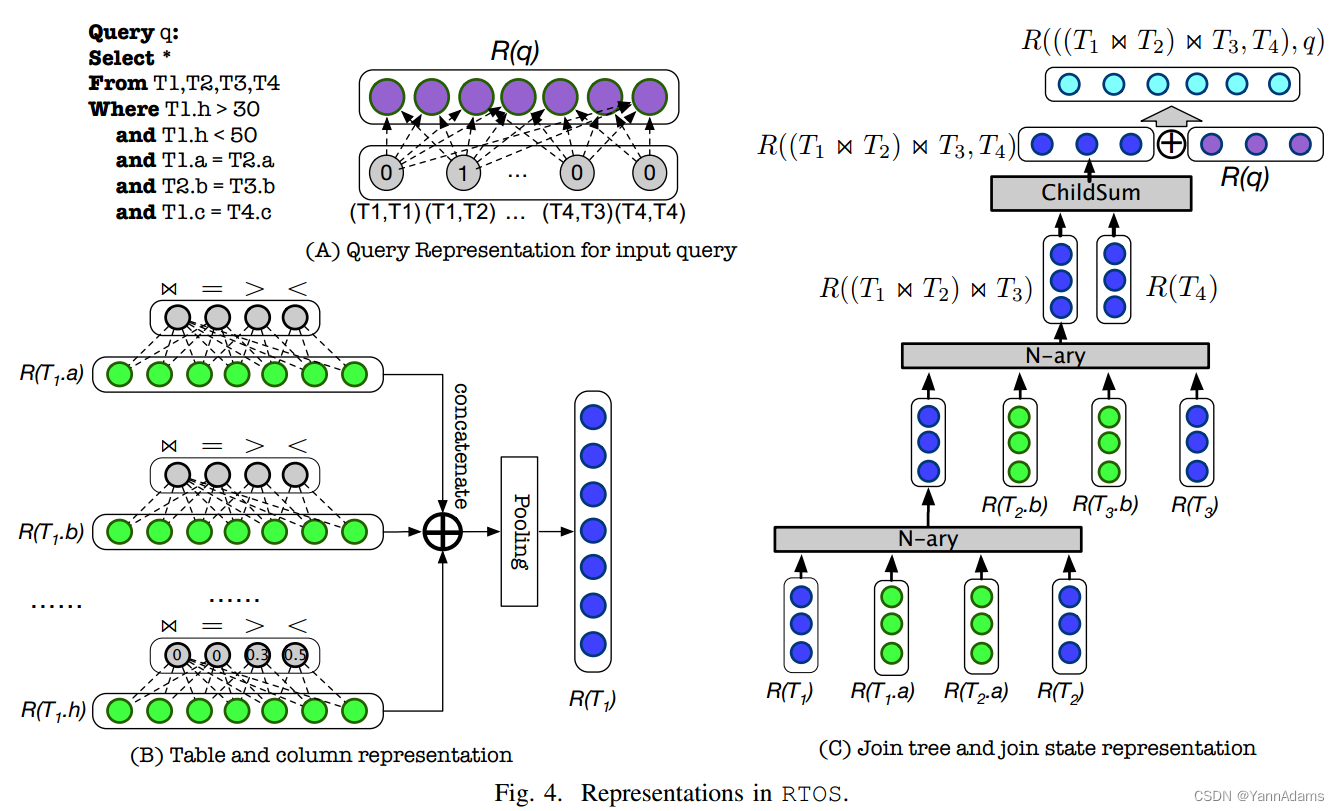
查询q的表示R(q)是一个向量,它包含q中所有表的连接信息。
设n为数据库中表的个数,每个表有一个从0到n−1的唯一标识符。设m为矩阵,其中每个单元格为0或1。
= 1表示第i张表和第j张表之间存在连接关系,否则为0。然后通过将原始矩阵m的从0到n−1的所有行放入向量中,即
=
和|v| =
,将这个矩阵平铺为向量v。
之后,我们在向量v上应用一个完全连接(FC)层(见图4(A)),得到q的表示:
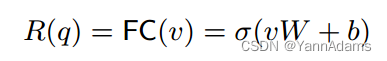
其中σ为神经网络中的一个激活函数(如tanh, Sigmoid, ReLU);W(形状为(n∗n, hs)的矩阵)和b(形状为(1,hs)的向量)是FC层中需要使用训练样本学习的参数;hs为神经网络中隐藏层的大小;R(q)是形状为(1,hs)的向量,表示查询q。
从这种基于矩阵的表示中学习查询的一种改进方法具有处理模式更改和多别名的良好特性(有关详细信息,请参阅第V-A节)。
B. Representation of Columns and Tables
列和表是查询中的两个关键组件。给定一个查询q,我们只需要使用q中的谓词来构造列的表示,而不需要扫描数据库。接下来,我们首先讨论列c的表示R(c),然后使用列表示构造表t的表示R(t)。
-
Column Representation
我们考虑两种类型的列:数值和其他值(例如字符串)。注意,在查询中,列c可以与两个操作(Join和Selection)相关联,这两个操作都需要考虑。特别地,我们将Selection信息编码为列c的列表示R(c),这可以看作是将所有Selection推入连接树的叶子中。
(i)对于含有数值的列c,Selection操作可分为三种情况:=、>和<。因此,我们将c编码为长度为4的特征向量:F(c) = (,
,
,
),其中如果列c存在于连接谓词中,则
= 1,否则为0。
对于其他三个Selection操作,仅仅将存在编码为Join操作是不够的,因为谓词中的值很重要。例如,给定一个谓词c > v,我们应该考虑值v作为特征。由于不同列中的数据具有不同的尺度,因此我们根据列中的最大值()和最小值(
)将值归一化为[0,1]。接下来我们将说明这三种情况。
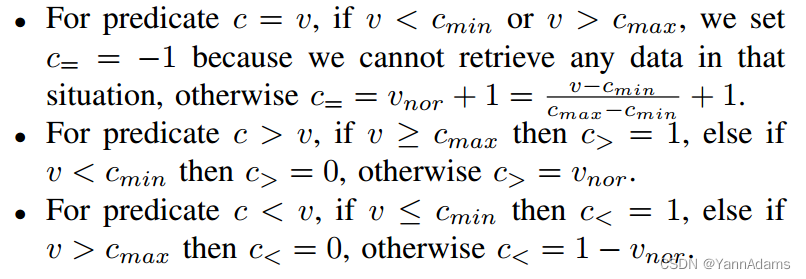
-
对于谓词c = v,如果v <
或v >
,我们设置
= -1,因为在这种情况下我们无法检索到任何数据,否则
+ 1 = 公式。
-
对于谓词c > v,如果v ≥
= 1,否则如果v <
-
对于谓词c < v,如果v ≤
= 1,否则如果v >
Example 3:考虑图4(A)中的查询,F() =(0,0,0.3, 0.5)。列
没有连接条件,也没有“=”谓词,因此
= 0和
= 0。
的最大值和最小值分别为0和100,因此当
> 30时设
= 0.3,当
< 50时设
= 1 - 0.5 = 0.5。
我们为每个列c定义一个形状为(4,hs)的矩阵M(c)。M(c)已经学习了包含列信息的参数。形状为(1,hs)的数值列c的表示R(c)为:
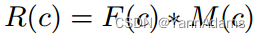
对于列c有通过“or”连接的谓词,我们分别处理这些谓词,并应用最大池化来获得一个表示。
(ii)对于具有其他值的列c(例如string)。它不能通过简单的方法(例如hash)映射到具有区间含义的值(“>”,“<”),而是需要更复杂的编码方法(例如word2vec[22])。这里我们只使用它的选择性信息对它进行编码,并得到列表示。
为了与上述特征向量对齐,我们还使用大小为4的向量来编码列,即(,
,
,
)。
的计算方法同上。
= 0和
= 0是因为字符串列的间隔信息不能直接用数值表示。对于
,给定谓词v,我们估计v的选择性,并设
为估计的选择性。
-
Table Representation
对于有k列的表t,我们使用它的列的表示来构造它的表表示R(t)。更具体地说,我们连接k列表示(,
,…,
)成矩阵M(t),其形状为(k, hs), M(t) = (
⊕…⊕
),并应用一个平均池化层(kernel shape(k, 1))得到形状(1,hs)的表表示(见图4(b)),为:
C. Representations of Join Tree, Join Forest and the State
接下来,我们将首先描述如何使用Tree-LSTM来学习连接树的表示,因为连接树是一种图结构,很难通过构造特征向量来直接获得其表示。
1)Tree-LSTM:传统的LSTM[8]显示了它在获取序列数据特征方面的能力,即使是对于很长的序列(例如,在自然语言处理中)。我们有一个序列输入X = (,
,
,…)。在每个时间步i,隐藏状态向量
表示步i的当前状态,存储单元向量
保存
,
,…,
的长期信息来处理长序列。LSTM在第i−1步使用LSTMUnit对输入
和之前的表示(
,
)进行处理,得到
和
。
,
=
。
然而,传统的LSTM读取序列数据,不能直接应用于树等复杂结构。为了解决这一限制,Child-Sum Tree-LSTM和N-ary Tree-LSTM[35]被提出在树结构输入上运行。对于给定的树,Tree-LSTM可以自动学习树的结构信息并给出其表示。
-
Child-Sum Tree-LSTM
Child-Sum Tree-LSTM不考虑其子树的顺序。对于给定的具有多个子节点的树节点j,它对所有子节点的表示求和,然后构造其表示。
-
N-ary Tree-LSTM
N-ary Tree-LSTM考虑其子树的顺序。对于给定的树节点j,其第k个子节点的表示将被单独计算。对于第k个子节点,它将有自己的权重矩阵关于k。顺序信息将被这些位置相关的权重矩阵捕获。
根据连接森林的特点,将这两种Tree-LSTM结合起来。森林F由几棵连接树{
,
,…}组成。在树形结构上没有任何人类特征的情况下,我们将连接树作为输入,使用模型自动学习连接树T的表示R(T)。
2)Representation for Join Tree:如图4(C)所示,我们为连接树构造了一个树模型。叶节点可以是表或列。连接树中的一个内部节点对应一个连接,由4个节点(,
,
,
)组成。
和
是两个需要连接的连接树(表)。
和
是节点对应的列。
,
,
,
是位置敏感的,我们在连接树中应用N-ary Tree-LSTM。
对于树节点j,我们使用表示它的表示,使用
表示内存单元。
-
如果节点j是代表单表的叶子,则
= R(j),
将被初始化为零向量。
-
如果节点j是代表单列的叶子,则
-
对于表示连接的节点j,它有4个子节点(
,
,
,
)。我们在N-ary Tree-LSTM中对这四个节点的表示应用N-aryUnit,得到
节点j的N-ary Tree-LSTM 的单元方程如下:
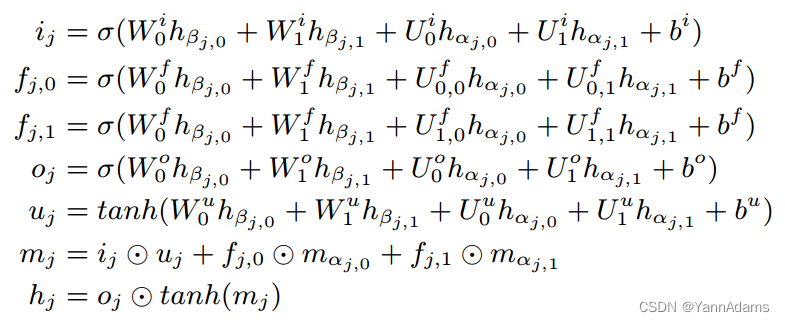
其中i, f, o, u为计算中的中间神经网络,对应于传统LSTM中被证明有助于捕获长期信息(深度树或长序列)的每个门。,
,
,
,*∈{i, f, o, u}, p∈{0,1}是与神经网络中的门和节点位置相对应的参数,将被训练以最小化给定的损失函数。
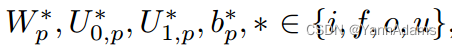
我们已经定义了N-aryUnit,它可以计算节点的表示。我们可以使用N-aryUnit来获得这个连接树的表示。利用PyTorch的动态图特性,我们可以在得到树后构造神经网络的计算图。我们使用深度优先搜索(DFS)遍历树并生成计算图,如函数JoinTreeDFS()所示。每个连接树根节点的可以看作是该连接树T的表示R(T), R(T) =
。

3)Representation for Join State:连接状态s由森林F = {
,
,…}和查询q组成。
对于一个有m个表要连接的查询q,在l个连接之后我们有m - l个连接树。对于那些尚未连接的连接树T,它们是无序的,任何两个表都可以在下次连接。为了表示这些连接树的组合,我们使用根节点来表示森林,其子节点是所有这些m-l连接树。连接树是位置无关的,这里使用Child-Sum Tree-LSTM来获得根
的输出。Child-Sum Tree-LSTM 中根的单位方程
如下:
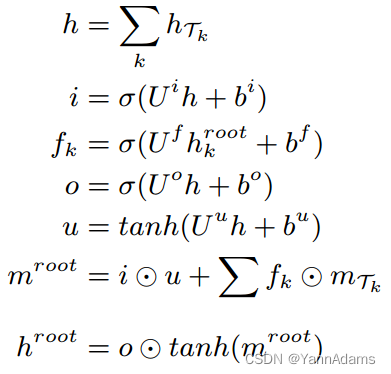
其中i, f, o, u为计算中的中间神经网络,分别对应传统LSTM中的每个门。方程中的参数,
,*∈{i, f, o, u}是神经网络中需要训练的参数。它们是CSUnit中与N-aryUnit不同的其他参数。根
的表示可以看作是森林R(F) =
的表示。在我们有了森林F和查询q的表示之后,我们将这两个表示连接起来,得到连接状态s的表示,R(s) = R(F) ⊕ R(q)
R(F)和R(q)是形状为(1, hs)的向量,R(s)是形状为(1, hs ∗ 2)的向量。
RTOS中的深度强化学习
在将JOS映射到RL问题并描述连接状态的表示之后,我们的下一个目标是解决这个问题,并给出一个具有小成本(延迟)的连接计划,为此我们使用深度Q网络(DQN)[23]。
A. DQN for Join Order Selection
Q-learning[39]是一种基于值的强化学习算法。与DP类似,Q-learning使用Q-table来存储所有状态的最佳值。给定几种可能的actions,它列举所有actions,然后选择最佳action。对于JOS,action空间A(s) = {(,
),(
,
),…}对应于所有可能的连接条件
其中
=
,
表示当前状态s在采取action
后转移到的新状态。我们将函数中的Q-values Q(s)定义为连接状态s下最优连接计划的期望最小成本(延迟)。我们可以得到Q的公式为:
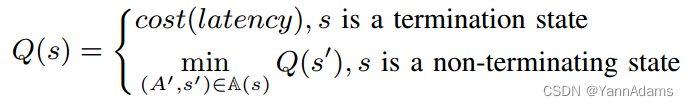
与动态规划类似,Q-learning使用Q-table来计算Q(s)。Q-table使用一个列表记录所有已知的状态值对(s, Q(s))。对于请求s的Q(s),如果s在Q表中,则直接返回Q(s),否则根据上述方程从其action空间A(s)递归请求Q-table Q(s')计算Q(s)。
policy函数π(s)用于返回给定状态s下选择的最优动作。一旦我们得到Q-table,我们就可以用它来指导策略函数。policy函数π(s)可得:
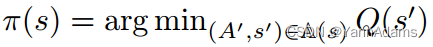
然而,作为动态规划,Q-learning需要一个大的Q-table,这消耗了大量的内存,并且枚举所有状态花费了太多的时间。
DQN通过使用神经网络(Q-network)从已知状态估计未知状态来改进Q-learning,而不是使用Q-table。我们在第III-C3节中得到了状态s的连接状态表示R(s)。我们用(R(s),ω)表示Q-network,其中ω是Q-network中的参数。
一个过程是RTOS生成一个连接计划并得到一个反馈v的完整过程。对于这个过程中的每个状态s,与Q-learning类似,(R(s),ω)有一个目标值V
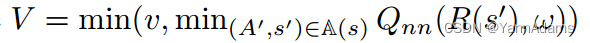
(R(s),ω),δ(R(s)) =
(R(s),ω) - V 的目标值之差可以表明Q-network对状态s的估计有多精确,越接近零意味着估计越好。我们使用L2损失来定义Q-network的损失函数,该函数需要最小化以训练Q-network:Loss(R(s))

B. Multi-task Learning for the Joint Loss of Cost and Latency
在RTOS中,需要考虑的一个问题是成本和延迟的选择。我们希望RL能够给出最短的执行时间,但是每一步都需要很长时间才能得到反馈。成本模型可以快速给出估计成本,但可能不准确。如第II-A节所述,我们将训练过程分为两个步骤:成本训练和延迟调优。在进行延迟调优时,我们不像以前的工作那样直接将目标从成本移到延迟。
相反,我们将它们视为两个相似的任务并一起训练神经网络,以便在需要大量新训练数据(例如,修改数据库模式)时,从成本效率和使用延迟进行微调中受益。这种思想来源于多任务学习[2],它共享神经网络的表示,同时得到多个任务的输出。在本RTOS中,我们考虑两个Q-network ,
,分别得到延迟
和成本
的Q-value。
在计划生成过程中,用于生成连接计划。在一个过程(一个计划生成过程)完成后,我们收集延迟L和成本C。对于本过程中的一个状态s,两个Q-network将以相同的表示来计算连接状态s。如图6所示,我们得到状态s的表示R(s),然后我们分别计算
和
,并使用它们自己的输出层。
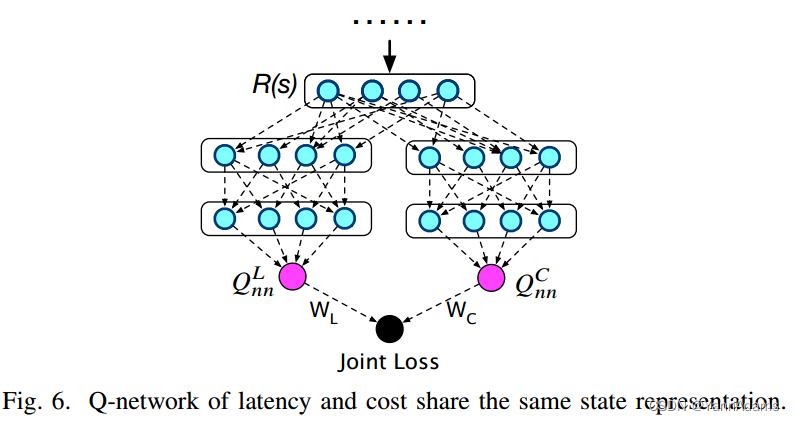
这两种Q-network的损失分别为:
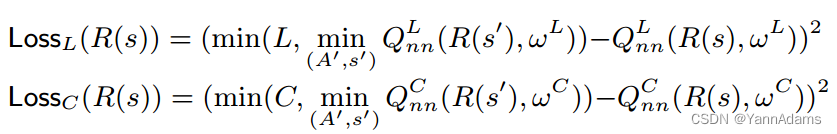
我们计算两个损失函数的加权和,得到整个网络的损失。
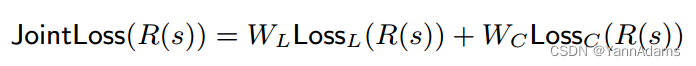
我们在成本训练时设置 = 0,
= 1,可以看出我们没有使用延迟,在延迟调优时设置
= 1,
= 1。成本用于训练网络,延迟用于找到计划。
处理修改和多别名
学习方法与传统方法的一个主要区别是,学习方法在应用于实际系统之前需要经过长时间的训练。以前学习的优化器使用与数据库中表和列的数量相关的固定长度向量,这使得它们难以处理以下(频繁)情况:
-
向表中添加列
-
向数据库插入表
-
多别名:一个表在一个查询中可以有多个别名,例如“Select ∗ from T as
, T as
…”,其中
添加列和插入表会改变数据库的模式。基于固定长度特征的神经网络需要改变网络的大小并重新进行训练。此过程耗时较长,可能导致系统故障。更重要的是,多别名可以被看作是一个在任何时候都很难处理的“插入表”。ReJoin[20]为每个表定义了一个冗余位置,并将和
视为两个完全不同的表。
和
的信息在训练的时候是不能共享的,当我们有
的时候就不能共享了,因为我们无法提前知道会出现多少别名。
下面我们将展示我们的模型如何使用RTOS中的动态特征和共享权重特征来支持这些操作。如果没有特别说明,RTOS默认使用下面的模型。
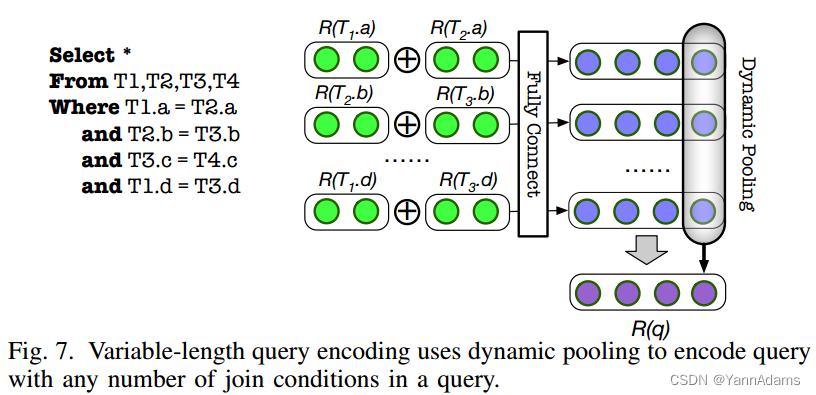
A. Variable-length Query Encoding
在第III-A节中,我们使用矩阵来表示查询。插入表时,n = n + 1,导致全连接层失败。我们探索查询编码的表示。对于给定的查询q,
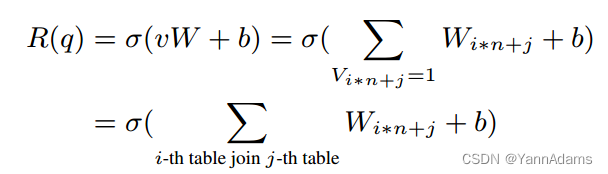
我们可以知道FC层使用一个向量来表示每个连接条件。R(q)是查询中join的那些向量的和。连接集Θ(q)
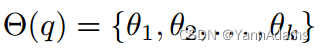
是查询q中所有k个连接条件的集合。连接条件由两列组成,
= (
,
)。
我们在这两列的表示,
上应用一个完全连接(FC)层来构造连接条件表示
=
。然后我们表示R(q) 替换W:
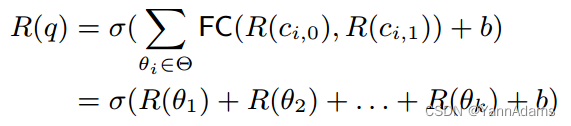
我们的目标是将这k (1, hs)-vectors (对于i∈[1,k])转换成一个(1, hs)-vectors,而k是根据不同查询的动态参数。为了解决这个问题,提出了动态池化[33]。动态池化是一种池化层,其内核大小将根据预期的输出特征大小来决定。如图7所示,我们对这k个向量
使用动态平均池化,并得到一个形状为(1,hs)的向量来表示R(q)。
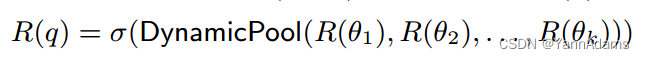
其中k是查询中的连接数量,与数据库中表的个数n无关。
B. Adding Columns and Inserting Tables
添加列将改变表的大小。当我们想在表t中添加一个列时,我们首先为
在神经网络中分配属性矩阵
,然后使用
构造
。在第III-B节中,我们使用k列表示
来构造表表示R(t)。增加一列会使k变为k + 1,因此我们将简单池化方法转换为动态池化方法来获得R(t)。
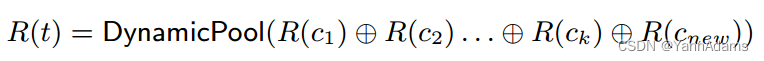
对于与相关的查询,我们学习
。对于没有
的其他查询,
保持为零,并保持R(t)与之前相同。
添加表将把数据库的大小从n更改为n + 1。我们首先为
中的所有列
分配相应的属性矩阵
来构造
。利用Tree-LSTM的动态特性,在得到连接树后,采用DFS方法构建了Tree-LSTM中的神经网络。任何节点都可以随时添加到连接树中。对于那些与
相关的查询,我们直接将
添加到连接树中,并通过Tree-LSTM更新相关参数。
权值初始化是减少训练时间的重要任务,称为迁移学习[29]。我们可以使用之前已知的类似列(表)初始化添加的列(表)的参数。在这里,我们简单地初始化添加列的属性矩阵,那些与前一列具有连接关系的。
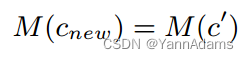
其中c'与有连接关系(例如外键)。
C. Multi-aliases
多别名可以看作是在执行查询时从原始表t插入复制表(,
)。复制表与原始表共享相同的数据。更重要的是,当我们使用强化学习学习反馈时。对别名
和
的反馈将共享神经网络中t的参数。
我们的想法是利用共享信息。,
将共享t的神经网络参数。对于
和
中列
的特征向量,我们使用t的属性矩阵构造它们的列表示。
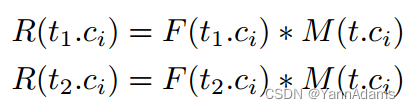
我们可以用那些来构造表表示
。与“插入表”操作一样,我们将
和
加入到连接树中,并在需要时构建神经网络。由于共享机制,它们反馈
,
的信息会作用于t的参数。
实验
我们实验的主要目的是了解基于DRL的方法和传统方法在连接顺序选择问题上的性能。我们在PostgreSQL上构建RTOS。
-
Datasets
(1) Join Order Benchmark (JOB) [17]
(2) TPC-H [30]
对于每个数据集,我们将所有查询分成10个部分,并选择9个作为训练集,另外1个作为测试集。
-
Algorithms
对于RTOS,默认情况下,我们在第五节中使用了final。RTOS是在PostgreSQL上实现的,它改进了查询计划的连接顺序部分,而将其他部分(例如,哈希连接或索引连接等访问方法)留给PostgreSQL来决定。我们比较了以下几种方法。
-
DQ 使用三个一维向量分别表示列、连接状态和投影的选择性。它还使用了深度Q-network,该模型是一个两层全连接网络。
-
ReJoin 使用两个
矩阵分别表示查询和连接状态,并使用一个one-hot向量表示查询中的列存在性。它使用PPO[31],另一种DRL技术。该模型是一个两层全连接网络。
-
SkinnerDB[37] 是根据RL策略选择良好连接顺序的最新方法。我们与Skinner-C最终生成的连接顺序进行了比较。
-
QP100(1000):给定一个查询,它随机测试100(1000)个可能的计划,并选择成本最低的计划。
-
Dynamic-program (DP):给定一个查询,它使用动态规划枚举所有连接计划,并选择成本最低的计划。我们利用PostgreSQL中的实现来测试这个方法。
所有方法都进行PK-FK连接。我们调优DQ和ReJoin的参数以获得更好的性能。我们将隐藏层大小设为hs = 128,取学习率为3e−4的Adam[12]作为模型的优化器。2小时用于成本训练,10小时用于延迟调优。
-
Training Sample Collection
为了探索模型从反馈(好的和坏的样本)中学习的能力,所有的DRL方法都是随机初始化的,并且只从反馈中学习。DQ通过从动态规划中采集样本对模型进行预训练,在连接数较少时使模型充当动态规划,在连接数较多时进行探索,需要复杂的人工干预。我们很难知道模型只是作为动态规划(只有好的样本),或者它可以从反馈(好的和坏的样本)中学习。此外,在延迟调优过程中,仅使用延迟作为反馈来改进模型,这是DP无法提供的。公平地说,这里所有的DRL方法都是通过仅从DBMS获取反馈来收集训练样本的。
-
Latency Collection.
我们首先得到每个查询q的DP计划的延迟时间和成本
。为了避免浪费不必要的时间,我们将执行时间限制为DP计划的5倍延迟 5 *
,并记录计划的延迟时间。收集延迟时使用单核。
-
Planning Time
DRL方法通常使用多项式时间,例如,ReJoin为, DQ为
,这取决于神经网络作为常数的计算。RTOS也是
,但有一个更大的常数。获取JOB中查询的连接树表示的平均时间约为5ms。JOB中最大查询(17个关系)的规划时间分别为213ms (RTOS)、97ms (DQ)和63ms (ReJoin)。对于JOB中的所有113个查询,RTOS的总规划时间为8秒,约为DP计划总延迟712秒的1%,因此,规划时间将在下面不再讨论。
A. Cost Training
我们首先评估了以成本作为反馈来指导RTOS的成本训练。我们选择DP作为基线,并报告其他方法的平均相对成本(MRC),其中MRC = 1表示与DP相同的成本。
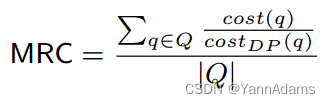
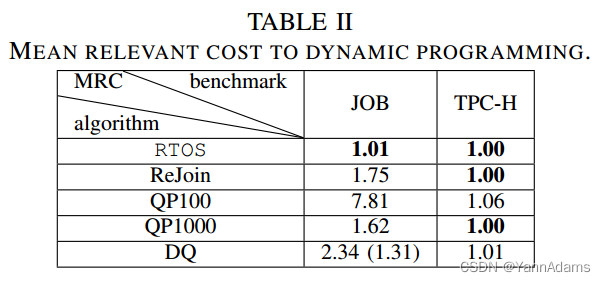
从表2中,我们可以看到RTOS优于其他4种方法,并且与DP一样好。我们在这里没有报告Skinner-C的成本结果,因为它没有成本模型,只使用延迟来生成连接顺序。在TPC-H中,所有方法都能得到接近最优计划。在进一步研究TPC-H查询后,我们发现这些查询通常很短(不超过8个关系),这限制了搜索空间。因此,连接顺序不是TPC-H中的主要问题。QP1000甚至可以枚举搜索空间,得到DP的相等计划。甚至QP100的MRC也达到了1.06。在JOB中,不同方法之间的MRC差距很明显,因为JOB中的查询非常多(多达17个关系),因此很难枚举搜索空间。RTOS的MRC(1.01)仍然优于其他两种DRL方法(1.75和2.34)和QP1000(1.62)。RTOS的MRC甚至超过了DQ(从动态规划的良好样本中预训练)的报告值1.31。RTOS 1.01的MRC反映了在估计成本下RTOS的竞争性能。
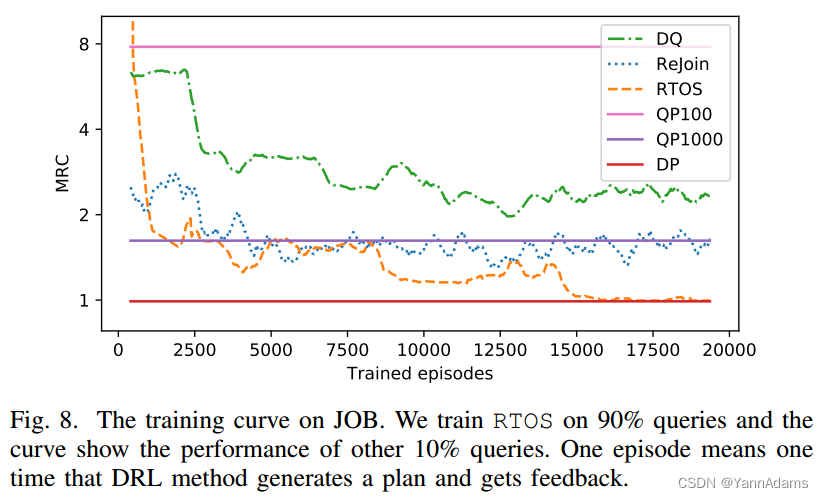
图8描述了JOB的训练曲线。我们可以看到,所有的DRL方法在开始时都表现得很差,经过足够的训练后就好多了。我们可以看到,在大约8000回合之后,RTOS甚至超过了QP1000。结果表明,RTOS不仅受益于DRL中的随机探索,而且还学习了数据库的连接特征。ReJoin和DQ的训练曲线上下振荡,不能收敛到一个好的训练曲线。一个主要原因是这两种方法将两个不同的计划投影到相同的表示中。神经网络为一个计划输出正确的值,使另一个计划失败。这种冲突使得神经网络很难为所有查询收敛到真正更好的计划。
B. Latency Tuning
经过成本训练,我们得到了一个对数据分布有了解的神经网络,可以以低成本生成计划。从这个经过训练的模型中,我们进一步使用延迟作为反馈来微调,以获得具有较低延迟的计划。
GMRL。我们也选择DP作为基线。注意,在延迟调优之后,基于DRL的方法比DP生成更好的计划,这使得MRC不适合捕获DP的相对性能。例如,给定两个查询,如果DRL方法生成的连接计划的延迟是DP的两倍(2)和一半(0.5),那么相对性能应该是1,但MRL将给出(2+0.5)/2 = 1.25。因此,我们使用基于几何平均的Geometric Mean Relevant Latency (GMRL)。
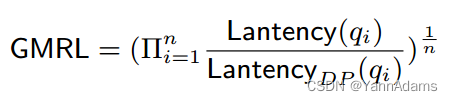
在2和0.5时的GMRL为 = 1,可以直接表示性能改善的比率。我们报告GMRL为DP的平均性能比。
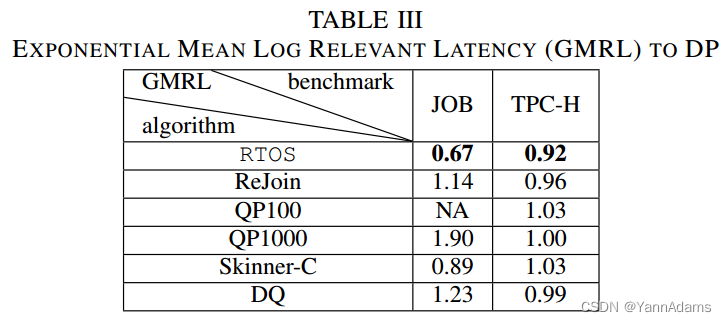
表3给出了各方法的GMRL。我们可以看到,在这两个基准测试中,RTOS优于其他方法。GMRL(在JOB上为0.67,在TPC-H上为0.92)低于1意味着我们可以在延迟上获得比DP更好的计划。我们没有给出QP100在JOB上的结果,因为它对一些需要长时间执行的查询给出了糟糕的计划。
对于TPC-H,所有DRL方法得到的GMRL都低于DP,这与表2的成本结果不同。这一结果表明了成本模型的不准确性。QP1000的执行与DP相同。对于JOB, RTOS的GMRL小于所有其他方法。RTOS的0.67意味着与DP相比改善了37%。我们可以看到Skinner-C优于DQ, ReJoin和DP,但仍然比RTOS差,因为Skinner-C不从以前的查询中学习,而是依赖在线RL模型来学习不同的连接顺序。SkinnerC通过在一个小的时间片中执行连接来度量连接顺序,这在整个执行过程中可能不准确。
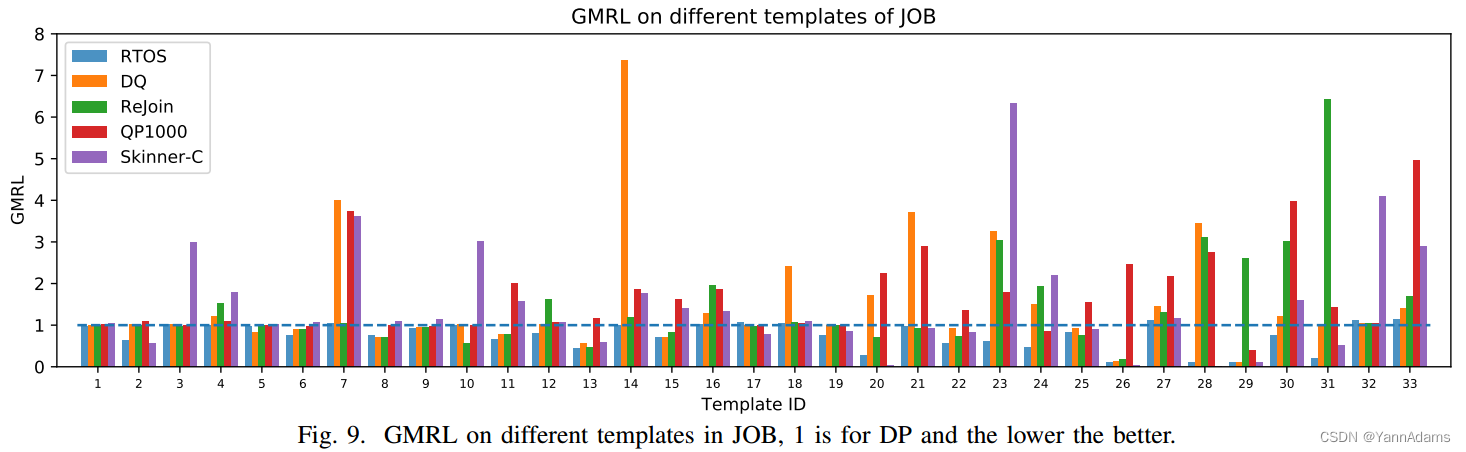
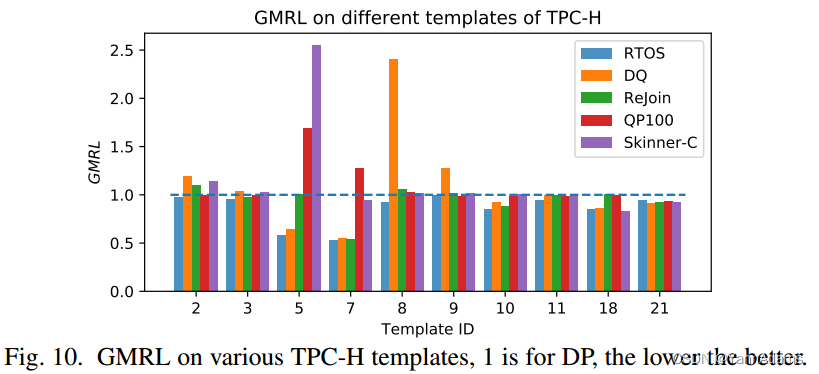
我们进一步按模板id对查询进行分组。图10显示了TPC-H的不同模板上的GMRL,为了有更好的视图,我们没有显示DRL方法执行与DP相同的模板。我们可以看到,对于所有模板,RTOS生成的计划不差于DP (GMRL= 1处的水平线),优于其他方法。图9显示了JOB的结果。我们可以看到,对于所有模板,RTOS几乎都可以生成不差于DP的计划。有趣的一点是,Skinner-C和RTOS在模板T20、T26、T28、T29和T31上明显优于DP,因为在这些查询中有多别名,RTOS可以处理多别名,而Skinner-C可以实时学习顺序。传统的成本模型在这种情况下失效了。对于Rejoin和DQ,它们可以在某些模板(例如,Rejoin的T10和DQ的T5)的查询上生成比其他方法更好的计划。然而,它们将在其他查询上产生糟糕的计划,这些查询可能会受到表示弱点的影响。
C. Recovery From Schema Changes
模式更改使RTOS无法在开始时为这些添加的表或列生成计划。我们研究了从故障状态恢复的方法所花费的时间(过程),以执行与成本上的DP相似的操作。
我们比较了两个版本的RTOS:
-
使用第三节中描述的固定大小表示的模型。它以新的数据库大小构建新的神经网络,并对网络进行再训练。
-
是使用第V节中描述的模型的最终版本,该模型允许模式更改,并使用已知列初始化添加列的神经网络。
1)Insert Table:我们在JOB中选择一个表char_name,并根据查询是否包含该表将所有113个查询拆分为训练集和更新集。我们首先在训练集(没有表char_name)上训练,然后将更新集中的查询作为新添加的表提供给
和
。
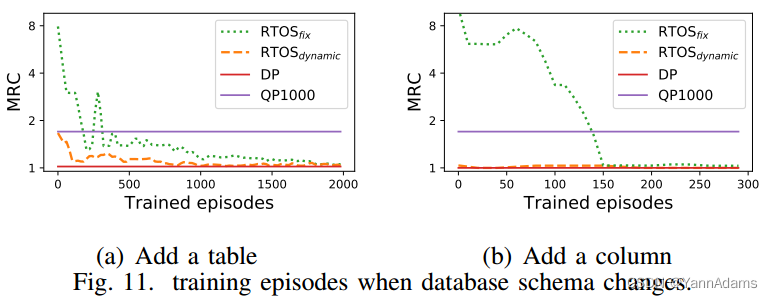
图11(a)显示了查询的训练(恢复)曲线。在一开始就迅速优于QP1000。
750回合之后,可以生成与DP竞争的计划,因为它包含JOB中其他20个表的知识。
大约需要2000回合才能在更新集上获得类似的性能,多花和2.5倍的回合。新训练的
只包含来自更新集的信息,并且从JOB中的所有查询中完全训练将需要20000回合(大约2小时),这是相当长的。
2)Add a column:我们选择一个列char-name.name,然后将所有113个查询拆分为训练集和更新集。
从图11(b)中的曲线可以看出,当将列添加到表中时,恢复得非常快,即使没有发生任何修改。原因是列(char-name.name)仅作为谓词出现。它与其他表或列没有复杂的关系。它的选择性是最重要的信息,与连接信息相比更容易学习。连接计划并不总是对此列敏感。
D. Effectiveness of Cost
来自延迟的反馈(甚至几秒钟)比来自成本模型的反馈(1ms)花费更多的时间。使用延迟作为反馈会使训练花费很长时间。
在这里,我们探讨成本训练的有效性。我们使用RTOS的以下设置来探索它:
-
Latency-Only:RTOS将从初始状态开始训练,并且仅使用延迟作为反馈。
-
Cost+Latency:基于成本训练的方法。我们首先使用成本作为反馈(约1小时的10000回合成本训练),然后将网络目标从成本改为延迟(延迟调整)。
-
JointLoss:基于成本训练的方法。在进行延迟调优时,我们收到了训练神经网络的延迟和成本,如第IV-B节所述。
完全使用延迟作为反馈将需要很长时间来训练网络。我们在JOB中选择了60个延迟最低(从10ms到2秒)的查询作为查询集,以测试上述方法的训练过程。
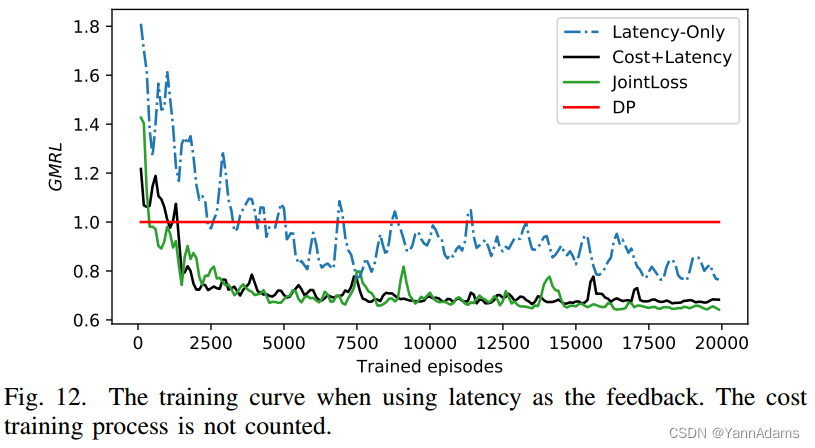
图12显示了使用延迟作为反馈时所有这些方法的训练曲线。基于成本训练的方法(JointLoss和Cost+Latency)只使用了1500回合,与仅使用Latency的约5000回合相比具有竞争力。

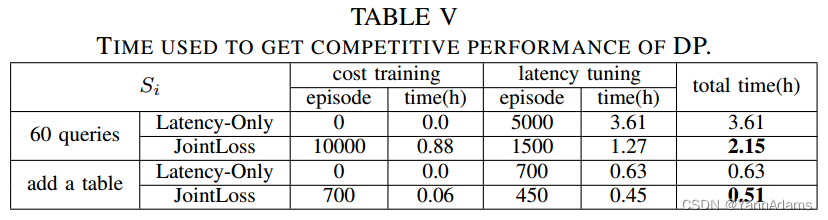
当反馈从成本转换为延迟时,成本训练将减少许多回合。表IV显示了使用延迟作为反馈时不同部分所消耗的时间。在计划执行后用于获取延迟的时间要比获取成本的时间长得多。获得延迟花费了10.27/(10.27+1.71+0.05) = 85.4%的延迟调优时间。表V显示,成本训练将增加回合,但减少总时间。基于成本训练的RTOS训练时间仅为2.15/3.61 = 59.8%,与仅延迟方法相比,可获得具有竞争力的DP性能。
JointLoss和Cost+Latency的性能几乎相同,这意味着我们可以在不影响模型性能的情况下保留神经网络中的Cost信息和Latency信息。我们切换到成本训练,然后在添加表时回到延迟调优。表V显示了当添加表char_name.name进行延迟调优时,JointLoss使用更少的时间(0.51 vs 0.63)。
E. Overall Training Time
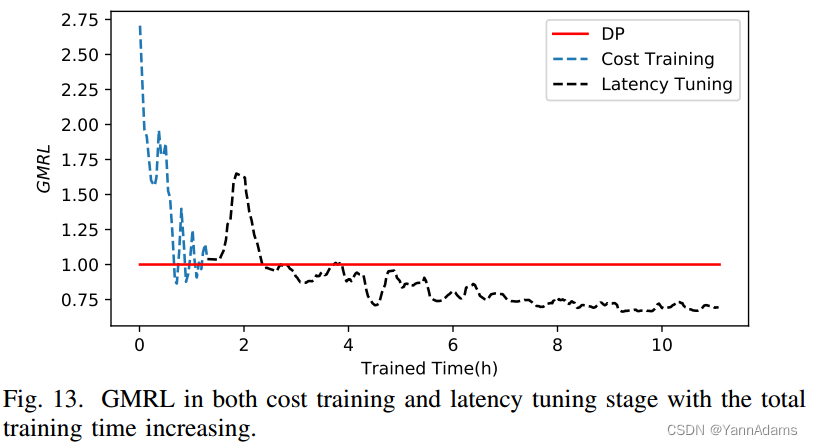
图13显示了在JOB查询的总训练时间增加的情况下,在成本训练和延迟调优阶段的GMRL。成本训练阶段首先需要1.5小时(15000回合),然后延迟调整需要10小时(8000回合)。我们可以看到,在成本训练阶段,RTOS的GMRL在1左右波动,因为RTOS在这个阶段专注于优化成本,而PostgreSQL的成本模型不够精确。当我们切换到延迟调优阶段时,我们可以看到RTOS生成了更好的计划,因为它专注于优化延迟,GMRL最终收敛到一个远小于1的值。
相关工作
-
Reinforcement learning for Join Order Selection
与我们最相似的作品是SkinnerDB [37], ReJoin[20]和DQ[16]。SkinnerDB[37]尝试在查询处理过程中使用RL来选择连接顺序。它通过在一组样本上运行计划,在一个时间片中执行一些计划,并使用性能来度量计划。它依赖于自定义的内存执行引擎来支持连接顺序的高频切换,并且不容易集成现有的DBMS。ReJoin[20]和DQ[16]使用DRL和一个初步的神经网络模型从给定的工作负载中学习连接过程。RTOS不同于这两种方法,它利用Tree-LSTM有效地对连接树的结构信息进行建模,并支持数据库更新。
结果表明,RTOS优于ReJoin、DQ和SkinnerDB。文章[27]试图通过DRL学习整个计划生成过程。DRL的思想可以帮助优化器从成本和延迟中学习,并在多项式时间复杂度内生成良好的连接计划。RTOS侧重于连接顺序选择,与索引选择或物理计划选择(通常编码为one-hot向量[16])相比,连接顺序选择更难以用神经网络表示。
NEO[19]使用值神经网络搜索低延迟的计划。NEO首先将连接树中的每个节点编码为特征向量,然后使用Tree Convolution Network[24]得到连接树的表示。与NEO不同的是,我们的RTOS可以有效地支持数据库更新。此外,RTOS不仅可以估计延迟,还可以估计成本,而NEO则专注于估计延迟。SageDB[15]提出了一个愿景,即机器学习(ML)可以通过对数据分布、工作负载和硬件进行建模来优化数据库。
-
Cardinality Estimation
传统的基数估计方法可以分为三类:基于直方图[9]、基于草图[5]和基于样本[18]的方法。最近,数据库社区正在研究利用深度神经网络的基数估计技术。[14]在查询上训练了一个多集合卷积网络,[28]提出了用强化学习训练连接树表示的愿景。[34]提出了一种树状结构模型来学习查询计划的表示。RTOS与基数估计方法是正交的。准确的选择性输入可以帮助进行延迟调优,甚至可以将基于神经网络的方法直接移植到我们的模型RTOS中(例如列表示)。
-
Deep Learning for Databases
研究人员已经将深度学习用于许多数据库问题,如实体匹配[25]、查询优化器[16]、基数估计[13]。本主题展示了深度学习的潜力。由于图神经网络(GNN)强大的表示能力[40],GNN在许多课题上都取得了成功[6],[7]。我们应用了Tree-LSTM,它也是一个GNN,并提出了表示连接树的方法。
结论及未来工作
我们提出了使用Tree-LSTM学习树状结构连接计划的RTOS。结果表明,在两个基准测试中,我们的方法在成本和延迟方面都能生成良好的计划。结果表明,该方法能够较好地学习连接树的结构,并捕获连接操作的信息。我们还证明了成本可以预训练神经网络并减少延迟调优时间。
当然,还有很多未来的工作。(1)迁移学习是一个有趣的研究方向,它可以将在一个数据库上训练的模型应用于另一个数据库。(2)由于I/O瓶颈、内存大小等因素,当系统处于高工作负载(例如同时执行多个查询)时,延迟可能会增加。如果我们想让系统从复杂的场景中学习反馈,我们需要考虑更多的工作负载信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









