







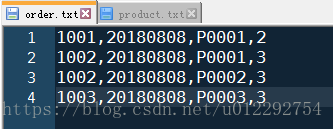
1 订单和商品的信息表
order
| id | date | pid | amount |
|---|---|---|---|
| 1001 | 20180808 | P0001 | 2 |
| 1002 | 20180808 | P0001 | 3 |
| 1002 | 20180808 | P0002 | 3 |
| 1003 | 20180808 | P0003 | 3 |
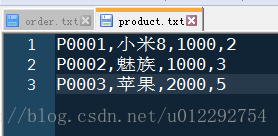
product
| id | pname | category_id | price |
|---|---|---|---|
| P0001 | 小米8 | 1000 | 2 |
| P0002 | 魅族 | 1000 | 3 |
| P0003 | 苹果 | 2000 | 5 |
2 源码
本地运行,调用集群,需要用到上一篇笔记的知识
package rjoin;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class InfoBean implements Writable {
private int order_id;
private String dateString;
private String p_id;
private int amount;
private String pname;
private int category_id;
private float price;
//0-- 表示对象封装的订单表;1--产品信息表
private String flag;
public InfoBean() {
}
public void set(int order_id, String dateString, String p_id, int amount, String pname, int category_id, float price, String flag) {
this.order_id = order_id;
this.dateString = dateString;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.category_id = category_id;
this.price = price;
this.flag = flag;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public String getDateString() {
return dateString;
}
public void setDateString(String dateString) {
this.dateString = dateString;
}
public String getP_id() {
return p_id;
}
public void setP_id(String p_id) {
this.p_id = p_id;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public int getCategory_id() {
return category_id;
}
public void setCategory_id(int category_id) {
this.category_id = category_id;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public String toString() {
return
"order_id=" + order_id +
", dateString='" + dateString + '\'' +
", p_id=" + p_id +
", amount=" + amount +
", pname='" + pname + '\'' +
", category_id=" + category_id +
", price=" + price +
", flag='" + flag ;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeUTF(dateString);
out.writeUTF(p_id);
out.writeUTF(pname);
out.writeInt(category_id);
out.writeFloat(price);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
order_id = in.readInt();
dateString = in.readUTF();
p_id = in.readUTF();
pname = in.readUTF();
category_id = in.readInt();
price = in.readFloat();
flag = in.readUTF();
}
}
package rjoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
public class RJoin {
static class RJoinMapper extends Mapper<LongWritable, Text, Text, InfoBean> {
InfoBean bean = new InfoBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName();
String pid = null;
if (name.startsWith("order")) {
String[] fields = line.split(",");
pid = fields[2];
bean.set(Integer.parseInt(fields[0]), fields[1], pid, Integer.parseInt(fields[3]), "", 0, 0, "0");
} else {
String[] fields = line.split(",");
pid = fields[0];
bean.set(0, "", pid, 0, fields[1], Integer.parseInt(fields[2]), Float.parseFloat(fields[3]), "1");
}
k.set(pid);
context.write(k, bean);
}
}
static class RJoinReducer extends Reducer<Text, InfoBean, InfoBean, NullWritable> {
@Override
protected void reduce(Text pid, Iterable<InfoBean> beans, Context context) throws IOException, InterruptedException {
InfoBean pdBean = new InfoBean();
ArrayList<InfoBean> orderBeans = new ArrayList<InfoBean>();
for (InfoBean bean : beans) {
if ("1".equals(bean.getFlag())) {
try {
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
} else {
InfoBean obean = new InfoBean();
try {
BeanUtils.copyProperties(obean, bean);
orderBeans.add(obean);
} catch (Exception e) {
e.printStackTrace();
}
}
}
//拼接两类数据形成最终结果
for (InfoBean bean : orderBeans) {
bean.setPname(pdBean.getPname());
bean.setCategory_id(pdBean.getCategory_id());
bean.setPrice(pdBean.getPrice());
context.write(bean, NullWritable.get());
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name","yarn");
conf.set("yarn.resourcemanager.hostname","node1");
conf.set("fs.defaultFS","hdfs://node1:9000/");
Job job = Job.getInstance(conf);
job.setJar("h:/rjoin.jar");
//job.setJarByClass(RJoin.class);
job.setMapperClass(RJoinMapper.class);
job.setReducerClass(RJoinReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(InfoBean.class);
//指定最终输出的数据类型
job.setOutputKeyClass(InfoBean.class);
job.setOutputValueClass(NullWritable.class);
//指定job的输入原始文件目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job配置的参数,以及job所用的java类所在的jar包提交给yarn去运行
//job.submit();
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}3 打包成 jar,放到 h 盘
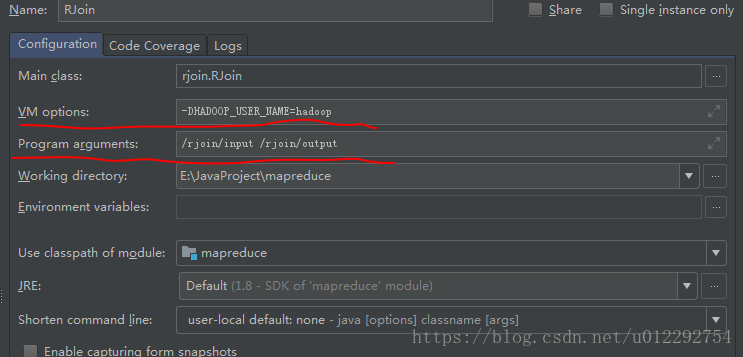
[hadoop@node1 ~]$ hadoop fs -mkdir -p /rjoin/input
[hadoop@node1 ~]$ hadoop fs -put order.txt product.txt /rjoin/input
4 运行
2018-08-08 20:19:05,641 INFO [main] client.RMProxy (RMProxy.java:createRMProxy(98)) - Connecting to ResourceManager at node1/192.168.154.131:8032
2018-08-08 20:19:07,584 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(64)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2018-08-08 20:19:07,991 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(283)) - Total input paths to process : 2
2018-08-08 20:19:08,146 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(198)) - number of splits:2
2018-08-08 20:19:08,329 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(287)) - Submitting tokens for job: job_1533696618495_0010
%JAVA_HOME%/bin/java
$JAVA_HOME/bin/java
2018-08-08 20:19:08,628 INFO [main] impl.YarnClientImpl (YarnClientImpl.java:submitApplication(273)) - Submitted application application_1533696618495_0010
2018-08-08 20:19:08,688 INFO [main] mapreduce.Job (Job.java:submit(1294)) - The url to track the job: http://node1:8088/proxy/application_1533696618495_0010/
2018-08-08 20:19:08,689 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1339)) - Running job: job_1533696618495_0010
2018-08-08 20:19:22,011 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1360)) - Job job_1533696618495_0010 running in uber mode : false
2018-08-08 20:19:22,013 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 0% reduce 0%
2018-08-08 20:19:38,427 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 50% reduce 0%
2018-08-08 20:19:39,436 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 100% reduce 0%
2018-08-08 20:19:48,654 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - map 100% reduce 100%
2018-08-08 20:19:49,691 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1378)) - Job job_1533696618495_0010 completed successfully
2018-08-08 20:19:49,847 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1385)) - Counters: 50
File System Counters
FILE: Number of bytes read=295
FILE: Number of bytes written=368422
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=362
HDFS: Number of bytes written=454
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=27925
Total time spent by all reduces in occupied slots (ms)=7318
Total time spent by all map tasks (ms)=27925
Total time spent by all reduce tasks (ms)=7318
Total vcore-milliseconds taken by all map tasks=27925
Total vcore-milliseconds taken by all reduce tasks=7318
Total megabyte-milliseconds taken by all map tasks=28595200
Total megabyte-milliseconds taken by all reduce tasks=7493632
Map-Reduce Framework
Map input records=7
Map output records=7
Map output bytes=275
Map output materialized bytes=301
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=301
Reduce input records=7
Reduce output records=4
Spilled Records=14
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=494
CPU time spent (ms)=2810
Physical memory (bytes) snapshot=492359680
Virtual memory (bytes) snapshot=6234865664
Total committed heap usage (bytes)=263188480
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=152
File Output Format Counters
Bytes Written=454
Process finished with exit code 0[hadoop@node1 ~]$ hadoop fs -ls /rjoin/output
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2018-08-08 08:19 /rjoin/output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 454 2018-08-08 08:19 /rjoin/output/part-r-00000
[hadoop@node1 ~]$ hadoop fs -cat /rjoin/output/part-r-00000
order_id=1002, dateString='20180808', p_id=P0001, amount=0, pname='小米8', category_id=1000, price=2.0, flag='0
order_id=1001, dateString='20180808', p_id=P0001, amount=0, pname='小米8', category_id=1000, price=2.0, flag='0
order_id=1002, dateString='20180808', p_id=P0002, amount=0, pname='魅族', category_id=1000, price=3.0, flag='0
order_id=1003, dateString='20180808', p_id=P0003, amount=0, pname='苹果', category_id=2000, price=5.0, flag='0
[hadoop@node1 ~]$














 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









