







摘要:
Apache Superset是一个开源的基于主流云原生技术构建的数据可视分析平台Business Intelligence(BI),给用户提供轻量,直观,可定制的操作界面来对接各种数据源,实现数据的查询,编排和可视化。通过结合Amazon Elastic Container Service(Amazon ECS),Amazon Cloud Map等托管服务,我们可以将Apache Superset快速构建至托管的容器集群,而无需安装、操作和扩展额外的容器编排和集群管理基础设施,IT人员,数据分析师等角色可以专注于业务本身,更加高效的实现从数据驱动认知到数据驱动决策的转变。
-
Apache Superset:
https://superset.apache.org/
关键消息:
Business Intelligence(BI),容器技术;
关键服务:
Amazon Elastic Container Service(ECS),Amazon Cloud Map,Amazon Elastic File System(EFS);
前言
当今BI平台的技术演进向数据和分析两端发展,数据端通过ODBC/JDBC等SQL应用接口对接数据源,通过ETL加工后送入数据仓库实现云上,线下数据的统一管理,分析端利用大数据,AI/ML,NLP等技术实现数据的智能查询,深度分析和知识图谱等能力。伴随云计算技术成熟和发展,利用云服务厂商所提供的托管服务打造的基础平台,在业务可靠性,应用灵活性以及现有服务对接方面相较传统BI都存在较大优势,以云托管服务为基础设施的一站式BI平台逐渐成为趋势。
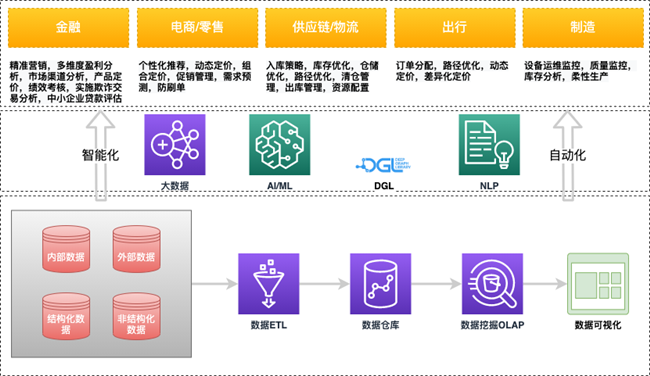
在数据ETL,数仓托管,数据挖掘,数据可视化环节,亚马逊云科技都提供了成熟可靠的托管服务(如Amazon Glue,Amazon Redshift,Amazon EMR)来帮助客户快速搭建起自有的全自动化数据处理流水线,实现从原始数据获取到最终商业决策的快速落地,同时针对BI平台未来智能化,自动化的技术趋势,亚马逊云科技也提供了从应用Amazon SaaS到基础设施的全AI/ML产品体系,以更好支撑各垂直行业如金融,电商,制造的细分领域和具体应用。
架构概览
Amazon Apache Superset各功能模块采用松耦合的方式独立开发迭代,模块间的通信通过Celery构建的分布式消息队列实现,对于容器技术如Docker,Kubernetes的支持相对完善。
-
Celery:
https://docs.celeryproject.org/en/stable/index.html
其主要模块及采用的技术栈如下所示:
-
web server(Gunicorn, Nginx, Apache)
-
metadata database engine(MySQL, Postgres, MariaDB, etc.)
-
message queue(Celery, Redis, RabbitMQ, SQS, etc.)
-
results backend(S3, Redis, Memcached, etc.)
-
caching layer(Memcached, Redis, etc.)
基于云原生技术开发的理念,用户可以按照自身需求灵活定制后端实现,如消息队列方面,用户可以采用默认的Redis,也可以对接Amazon SQS实现更为经济可靠,弹性高效的队列功能。目前社区提供的容器版本通过Host Volume单节点运行的方式来实现应用的初始创建,数据挂载等功能,如下图所示:
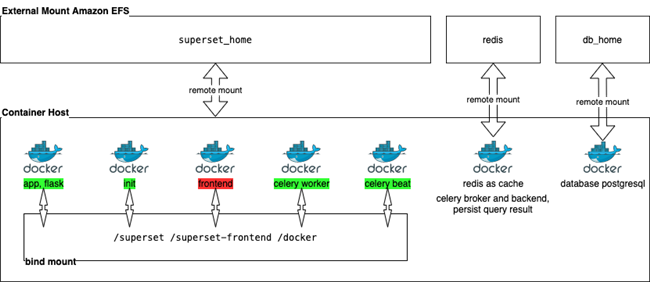
为了最大程度适配原有Apache Superset的架构设计,我们将其迁移运行到亚马逊云科技的基本思路是将平台本身相对独立的功能模块运行在Amazon ECS上,利用Amazon ECS Fargate实现资源的调度,服务的健康检查,各Amazon ECS服务本身通过Amazon Cloud Map创建的私有DNS进行服务发现,寻址和通信,各Amazon ECS服务自身的数据存储共享通过Amazon EFS实现,以获取更好的可用性,灵活性和低成本。网络规划我们遵循亚马逊云科技最佳实践,用户上行inbound访问流量通过Amazon Application Load Balancer对接到Amazon ECS集群的Superset Service,Superset Service的下行outbound流量如连接外部数据源,获取示例数据等则通过Amazon NAT Gateway实现,结合Amazon VPC安全组实现网络流量的端口控制(如Superset默认的端口8088),整体方案的软件架构如下图所示:
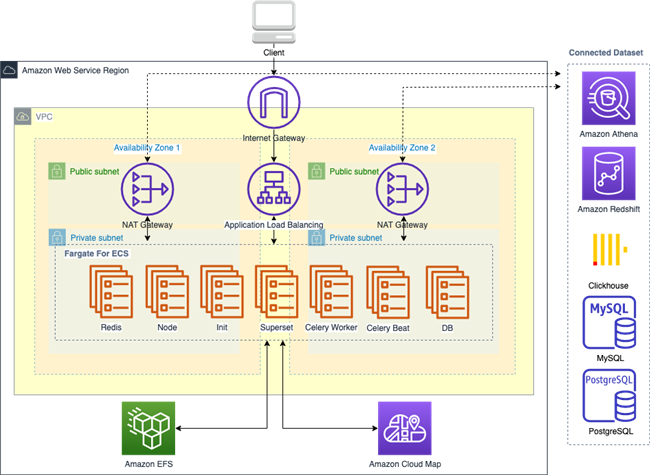
相较于Apache社区版本,运行在亚马逊云科技上的Apache Superset存在如下优势:
-
核心模块(Superset,Cache,Database)高可用;
-
业务数据(元数据,查询数据,交互数据)持久化;
-
平台资源弹性伸缩,用户无需关心底层资源调度;
-
预装SQL,PostgreSQL,Redshift,Athena,ClickHouse数据源驱动,创建完毕即可连接已有数据
-
预装时序预测算法,基于导入数据实现未来趋势预测
-
可视化看板实时监控亚马逊云服务各项指标以及应用综合指标
创建步骤
该方案Apache Superset的所有功能模块通过预定义好的Amazon CloudFormation模版实现创建启动,点击如下按键将跳转到Amazon CloudFormation控制台界面(Beijing)进行整体方案的一键部署。代码实施细节参见这里。
-
Amazon CloudFormation:
https://aws.amazon.com/cn/cloudformation/
-
这里:
https://github.com/aws-quickstart/quickstart-aws-superset
部署到已有Amazon VPC:
https://cn-north-1.console.amazonaws.cn/cloudformation/home?region=cn-north-1#/stacks/create/template?stackName=SupersetOnAWS&templateURL=https://aws-cn-quickstart-cn-north-1.s3.cn-north-1.amazonaws.com.cn/quickstart-aws-superset/templates/superset-entrypoint-existing-vpc.template.yaml
部署到新建Amazon VPC:
https://cn-north-1.console.amazonaws.cn/cloudformation/home?region=cn-north-1#/stacks/create/template?stackName=SupersetOnAWS&templateURL=https://aws-cn-quickstart-cn-north-1.s3.cn-north-1.amazonaws.com.cn/quickstart-aws-superset/templates/superset-entrypoint-new-vpc.template.yaml
配置选项配置用于登陆Superset控制台的用户名和密码,其中“Pre-populate example dashboard”用于配置是否要获取官方内置示例数据集以及仪表板,”Install Prophet library”用于配置是否要安装Prophet软件包以实现数据的在线预测功能。

待Stack安装完毕之后,我们可跳转到Amazon ECS控制台查看所有的Superset组件是否正常启动运行,如下图所示,我们可以看到所有的服务处于Active状态

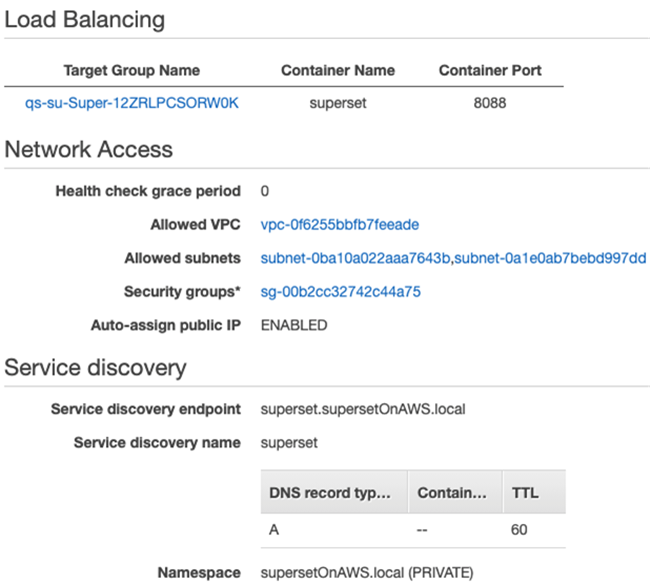
点击其中包含SupersetService字样的Service,在Load Balancing一栏可查看所对接的Amazon ALB的Target Group,其默认开放的端口为8088,我们之后的操作访问页面也将通过这个端口;在Network Access一栏可查看Superset所在Amazon VPC的基本信息,包括子网,安全组等,在接下来的数据对接中,我们需要确保创建的Amazon Redshift在同一个Amazon VPC;在Service discovery一栏可查看服务对应的内部DNS名称,该兴趣的读者可以跳转至Amazon Route 53界面查看对应的Domain name和Record name以了解各服务之间如何发现,寻址和通信。
接下来我们在浏览器中输入Outputs选项中输出的登陆Superset的地址。

输入之前创建应用时配置的用户名和密码,便可以开始使用Superset来进行数据分析。

数据对接
接下来我们将创建一个Amazon Redshift,具体的集群创建,数据导入等流程在此不再赘述,可参考官方网站详细介绍。需要注意的是,我们在此创建的Amazon Redshift所在Amazon VPC需要同创建Superset所在的Amazon ECS一致,以确保在不开启Amazon Redshift公共访问权限的情况下,Superset仍然能够通过内部Amazon VPC网络实现数据的关联。
-
官方网站:
https://docs.aws.amazon.com/redshift/latest/gsg/getting-started.html
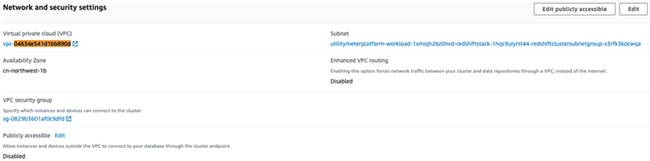
Amazon Redshift创建完毕之后,记录下对应的Endpoint地址。

接下来切换到Superset操作界面,点选Data,下拉框选择Databases开始连接,URL格式为redshift+psycopg2://:@:5439/,更多其他数据源的URL格式可以参考Superset官方文档。
-
Superset官方文档:
https://superset.apache.org/docs/databases/redshift
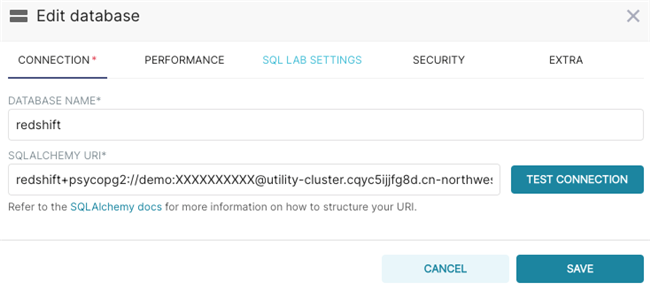
连接成功后,点击Datasets查看对应的数据集是否正常显示,这里的示例数据是”daily”。

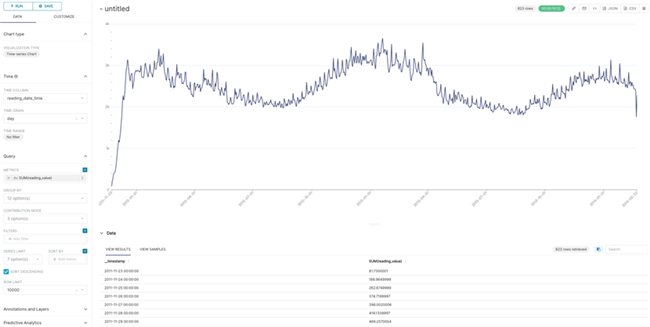
点击进去进行编辑,Visualization Type中选择Time-series Chart,Time Range选择No filter,Query中Column为要显示的数值,Aggregate选择Sum操作,点击Run可以看到数据按照时间序列绘制出来,同时在Data一栏展示了数据样本,注意上述配置需要根据实际数据进行修改。需要注意横向时间轴的最后时间为2014-02-22
如果在创建Superset的选项我们选择了Install Prophet library为yes,我们可以进一步体验Superset内置的时间序列预测功能。点击Predictive Analytics,勾选Enable Forecast选项,其他选项默认,重新执行RUN。
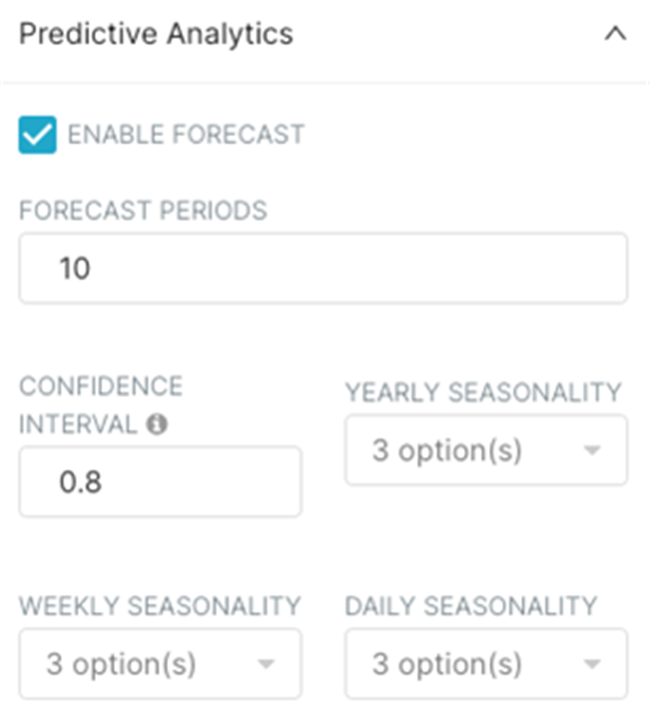
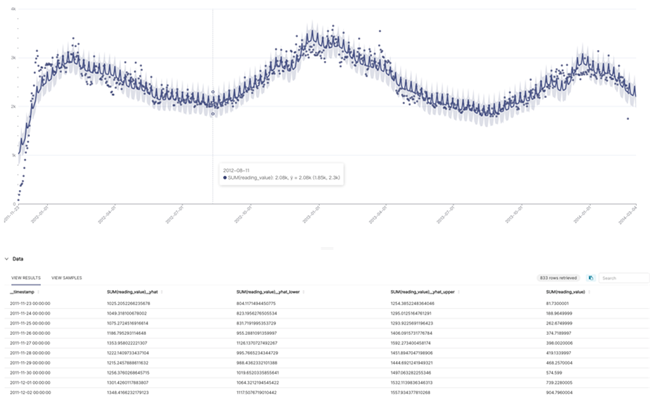
可以看到Superset在之前的数据基础上对未来10天的数据走势进行了预测(此时横向时间轴的最后时间为2014-03-04)并绘制出了数据的置信区间,其中紫色圆点为原始的时间序列离散点,紫色实线为使用时间序列拟合所得到的取值,实线周围的浅色区域则为数据的置信区间,即合理的上界和下界。在该操作中我们需要输入的是包含时间戳和值的原始数据,需要预测的时间序列长度,得到的输出为未来时间序列趋势以及对应的置信区间。
最后
利用Amazon Elastic Container Service(ECS)及其支持的无服务器计算特性(Fargate),我们可将原有容器负载或新开发的云原生负载非常平滑的迁移到亚马逊云科技平台,通过设计隔离各软件模块来提高服务的安全性和可靠性,而无需预置和管理服务器,结合Amazon Route 53,Amazon Cloud Map,Amazon Elastic File System实现服务通信和数据存储,Amazon CloudFormation实现服务部署和扩展,最终降低Amazon BI平台的使用门槛,IT人员,数据分析师等角色可以专注于业务本身,更加高效的实现从数据驱动认知到数据驱动决策的转变。
本篇作者

易珂
亚马逊云科技解决方案架构师
开源项目和新兴技术爱好者,负责亚马逊云科技解决方案的咨询,构建和实施,拥有近十年研发及技术团队管理经验,其技术领域包括无服务器(Serverless),容器,AI/ML。
















 8462
8462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









