







企业拥有大量数据,其中许多数据由于是非结构化性质,而难以发现。分析非结构化数据的传统方法通常是使用关键词或同义词匹配。
非结构化数据
https://aws.amazon.com/blogs/big-data/unstructured-data-management-and-governance-using-aws-ai-ml-and-analytics-services/
相比之下,文本嵌入使用机器学习(ML)功能来捕获非结构化数据的含义。嵌入由表征语言模型生成,将文本转换为数值向量并在文档中编码上下文信息。这使得诸如语义搜索、检索增强生成(RAG)、主题建模和文本分类等应用程序成为可能。
机器学习(ML)
https://aws.amazon.com/machine-learning/
检索增强生成(RAG)
https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
例如,在金融服务行业,应用包括从收益报告中提取见解、从财务报表中搜索信息,以及分析金融新闻中关于股票和市场的情绪。文本嵌入使行业专业人士能够从文档中提取见解、最小化错误并提高绩效。
在这篇文章中,我们展示了一个可以使用 Cohere 的 Embed 和 Rerank 模型与 Amazon Bedrock 在不同语言的金融新闻中进行搜索和查询的应用程序。
Embed
https://aws.amazon.com/bedrock/cohere-command-embed
Rerank
https://aws.amazon.com/marketplace/pp/prodview-pf7d2umihcseq?sr=0-1&ref_=beagle&applicationId=AWSMPContessa
Amazon Bedrock
https://aws.amazon.com/bedrock/
Cohere 的多语言嵌入模型
Cohere 是一个领先的企业人工智能平台,构建世界一流的大型语言模型(LLM)和由 LLM 驱动的解决方案,使计算机能够搜索、捕获含义并以文本形式进行对话。它们提供了易用性和强大的安全性和隐私控制。
Cohere 的多语言嵌入模型可为超过 100 种语言的文档生成向量表示,并可在 Amazon Bedrock 上使用。这允许亚马逊云科技客户以 API 的形式访问它,从而无需管理底层基础设施,并确保敏感信息得到安全管理和保护。
因此,您不需要深入研究内部文档,只需使用自然语言向 Amazon Q Business 询问需求,它就会立即为您提供相关信息,并帮助简化任务和加速问题解决。
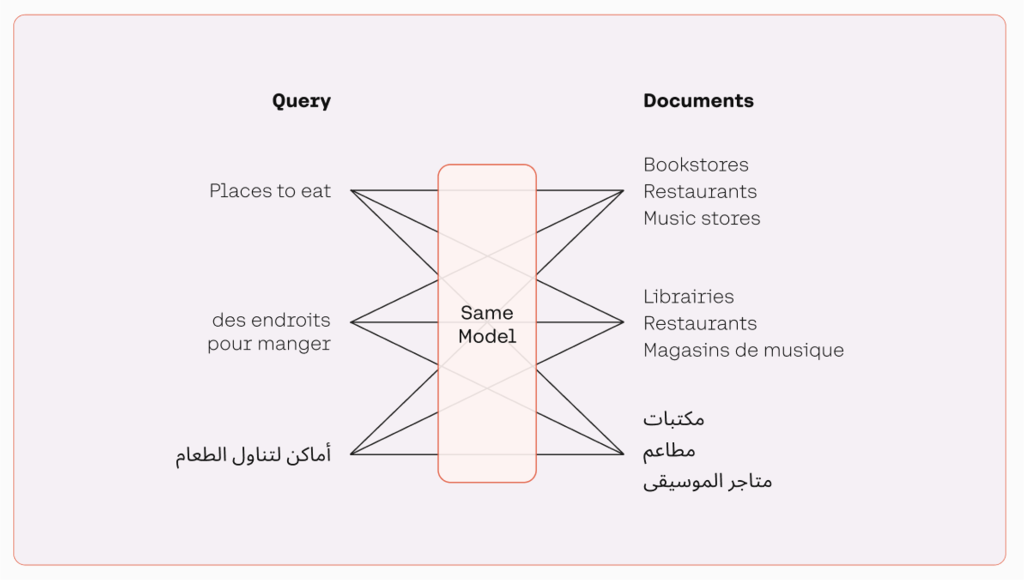
多语言模型通过为具有相似含义的文本分配彼此靠近的语义向量空间位置来对它们进行分组。使用多语言嵌入模型,开发人员可以处理多种语言的文本,而无需在不同模型之间切换,如下图所示。这使处理更加高效,并提高了多语言应用程序的性能。
以下是 Cohere 嵌入模型的一些亮点:
专注于文档质量 – 典型的嵌入模型经过训练以测量文档之间的相似性,但 Cohere 的模型还可以测量文档质量。
RAG 应用程序的更好检索 – RAG 应用程序需要良好的检索系统,Cohere 的嵌入模型在这方面表现出色。
高效的数据压缩 – Cohere 使用特殊的压缩感知训练方法,从而为您的向量数据库带来了大量成本节约。
文本嵌入的使用案例
文本嵌入将非结构化数据转换为结构化形式。这使您能够客观地比较、分解和从所有这些文档中获得见解。以下是 Cohere 的嵌入模型所支持的一些使用案例示例:
语义搜索(semantic search) – 当与向量数据库相结合时,可实现基于搜索短语含义的出色相关性的强大搜索应用程序。
更大系统的搜索引擎(search engine) – 从连接的企业数据源中查找和检索 RAG 系统所需的最相关信息。
文本分类(text classification) – 支持意图识别、情感分析和高级文档分析。
主题建模(topic modelling)– 将一组文档转换为不同的集群,以发现新兴主题。
使用 Rerank 增强搜索系统
在已经存在传统关键词搜索系统的企业中,如何引入现代语义搜索功能?对于长期作为公司信息架构一部分的此类系统,完全迁移到基于嵌入的方法在许多情况下是不可行的。
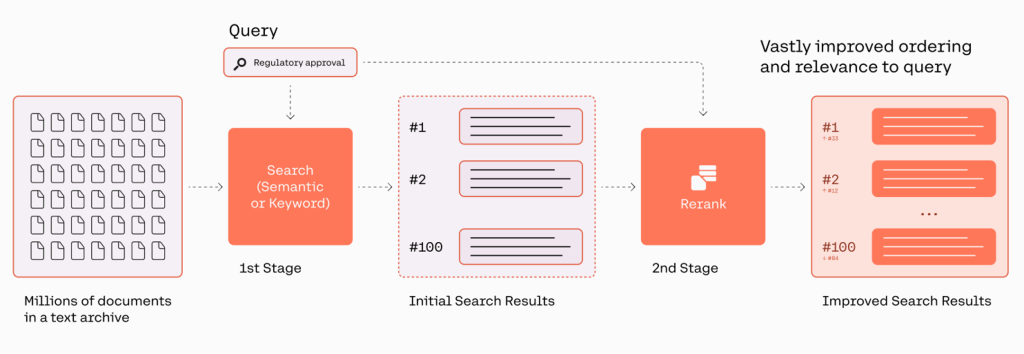
Cohere 的 Rerank 端点旨在弥合这一差距。它充当搜索流程的第二阶段,根据用户的查询对相关文档进行排名。企业可以保留现有的关键词(甚至语义)系统用于第一阶段检索,并使用第二阶段的 Rerank 端点来提高搜索结果的质量。
Rerank 提供了一种快速简单的选择,只需一行代码即可通过在用户的堆栈中引入语义搜索技术来改善搜索结果。该端点还支持多语种。下图说明了检索和重新排序的工作流程。
解决方法概述
金融分析师需要消化大量内容,如金融出版物和新闻媒体,以保持信息灵通。根据财务专业人员协会(AFP)的数据,金融分析师 75% 的时间用于收集数据或管理流程,而非增值分析。跨多种来源和文档寻找问题答案是一项耗时且乏味的工作。Cohere 嵌入模型帮助分析师快速搜索多种语言的大量文章标题,找到并排列与特定查询最相关的文章,从而节省大量时间和精力。
在以下用例示例中,我们展示了如何使用 Cohere 的 Embed 模型在一个独特的管道中搜索和查询不同语言的金融新闻。然后我们演示了如何将 Rerank 添加到您的嵌入检索中(或将其添加到传统的词汇搜索中),以进一步改善结果。
项目信息可在 GitHub 上找到。
GitHub
https://github.com/cohere-ai/cohere-aws/blob/main/notebooks/bedrock/Financial%20Multilingual%20Embeddings.ipynb
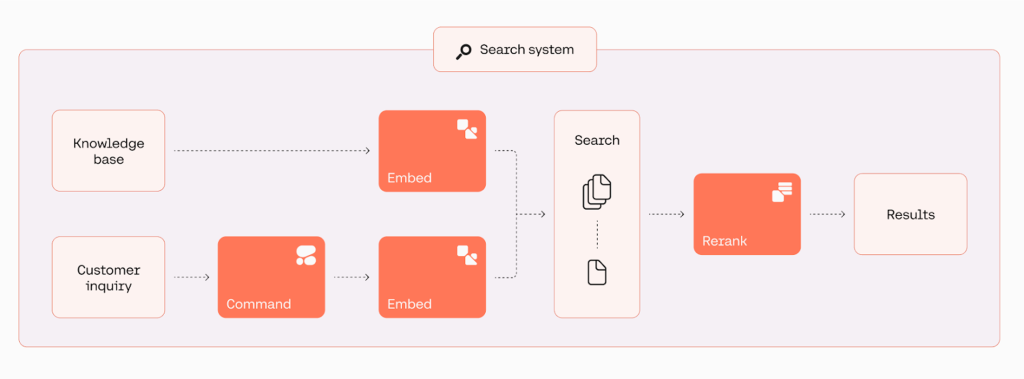
下图说明了应用程序的工作流程。
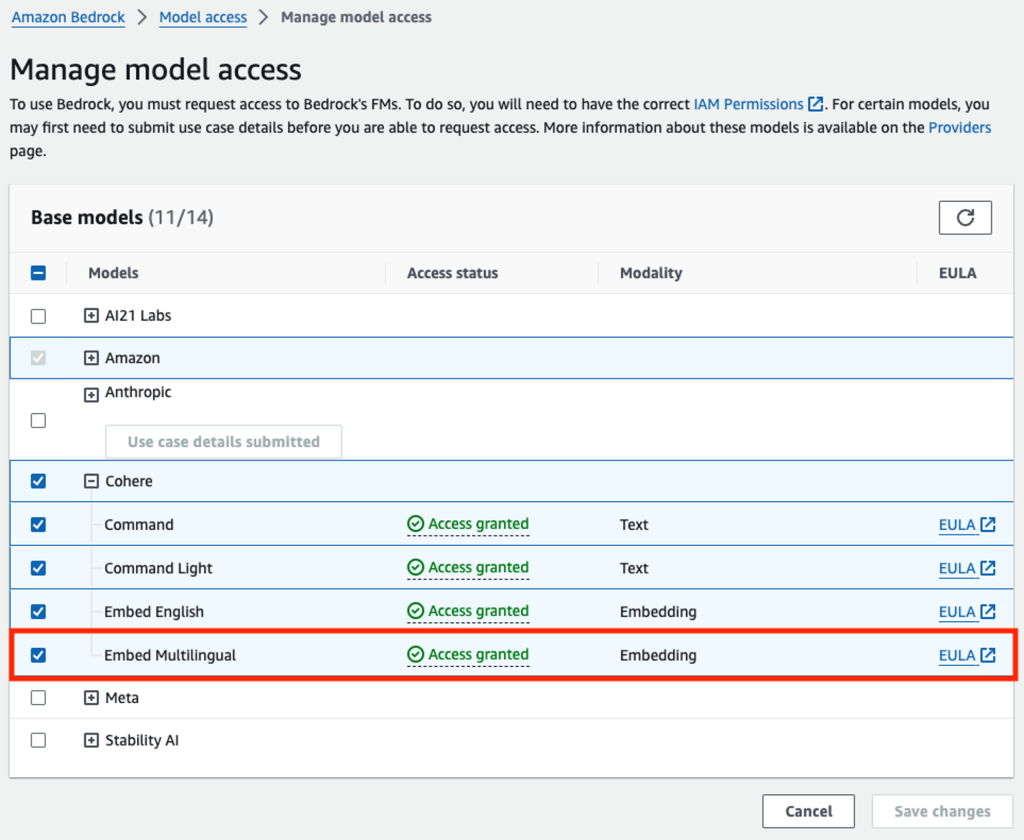
通过 Amazon Bedrock 启用模型访问
Amazon Bedrock 用户需要请求访问模型以使其可用。要请求访问其他模型,请在 Amazon Bedrock 控制台的导航窗格中选择模型访问。有关更多信息,请参阅模型访问。对于本次实践,您需要请求访问 Cohere Embed Multilingual 模型。
Amazon Bedrock 控制台
https://console.aws.amazon.com/bedrock
模型访问
https://docs.aws.amazon.com/bedrock/latest/userguide/model-access.html
安装软件包并导入模块
首先,我们安装必要的软件包并导入本示例中将使用的模块:
!pip install --upgrade cohere-aws hnswlib translate
import pandas as pd
import cohere_aws
import hnswlib
import os
import re
import boto3左右滑动查看完整示意
导入文档
我们使用一个数据集(MultiFIN),其中包含 15 种语言(英语、土耳其语、丹麦语、西班牙语、波兰语、希腊语、芬兰语、希伯来语、日语、匈牙利语、挪威语、俄语、意大利语、冰岛语和瑞典语)的真实文章标题列表。这是一个为金融自然语言处理(NLP)而策划的开源数据集,可在 GitHub 存储库上获得。
GitHub 存储库
https://github.com/RasmusKaer/MultiFin
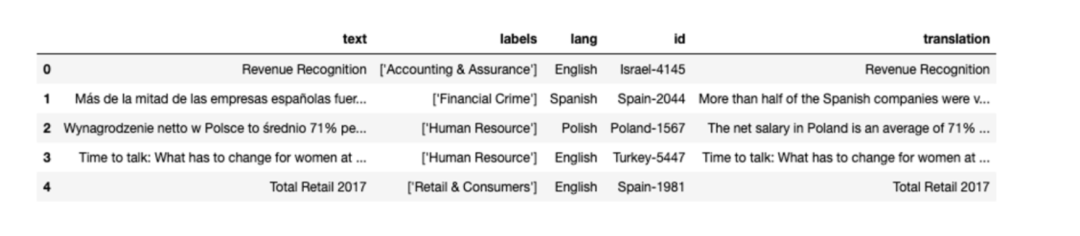
在我们的例子中,我们创建了一个 .csv 文件,其中包含 MultiFIN 的数据以及一个包含翻译的列。我们不使用该列来为模型提供数据,而是使用它来帮助我们跟踪打印的结果,这样不熟悉丹麦语或西班牙语的用户也能理解。我们指向该 .csv 文件来创建数据框:
url = "https://raw.githubusercontent.com/cohere-ai/cohere-aws/main/notebooks/bedrock/multiFIN_train.csv"
df = pd.read_csv(url)
# 检查数据集
df.head(5)左右滑动查看完整示意
选择要查询的文档列表
MultiFIN 包含 15 种不同语言的 6,000 多条记录。对于我们的用例示例,我们关注三种语言:英语、西班牙语和丹麦语。我们还按长度对标题进行排序,并选择最长的标题。
由于我们选择了最长的文章,我们要确保长度不是由于重复序列造成的。以下代码显示了一个这种情况的示例。我们将对此进行清理。
con los Objetivos de Desarrollo Sostenible comprometidas con los Objetivos de
Desarrollo Sostenible'
# 确保标题中没有重复文本
def remove_duplicates(text):
return re.sub(r'((\b\w+\b.{1,2}\w+\b)+).+\1', r'\1', text, flags=re.I)
df['text'] = df['text'].apply(remove_duplicates)
# 只保留选定的语言
languages = ['English', 'Spanish', 'Danish']
df = df.loc[df['lang'].isin(languages)]
# 选取最长的80篇文章
df['text_length'] = df['text'].str.len()
df.sort_values(by=['text_length'], ascending=False, inplace=True)
top_80_df = df[:80]
# 语言分布
top_80_df['lang'].value_counts()左右滑动查看完整示意
我们的文档列表很好地分布在这三种语言中:
lang
Spanish 33
English 29
Danish 18
Name: count, dtype: int64以下是我们数据集中最长的文章标题:
top_80_df['text'].iloc[0]
"CFOdirect: Resultater fra PwC's Employee Engagement Landscape Survey, herunder hvordan
man skaber mere engagement blandt medarbejdere. Læs desuden om de regnskabsmæssige
konsekvenser for indkomstskat ifbm. Brexit"左右滑动查看完整示意
嵌入和索引文档
现在,我们想要嵌入我们的文档并存储嵌入。嵌入是非常大的向量,它们封装了文档的语义含义。特别是,我们使用 Cohere 的 embed-multilingual-v3.0 模型,它创建了 1024 维的嵌入。
当传递查询时,我们还会嵌入查询并使用 hnswlib 库来找到最近邻。
只需几行代码即可建立 Cohere 客户端、嵌入文档并创建搜索索引。我们还可以跟踪文档的语言和翻译,以丰富结果的显示。
# 建立Cohere客户端
co = cohere_aws.Client(mode=cohere_aws.Mode.BEDROCK)
model_id = "cohere.embed-multilingual-v3"
# 嵌入文档
docs = top_80_df['text'].to_list()
docs_lang = top_80_df['lang'].to_list()
translated_docs = top_80_df['translated_text'].to_list() #用于在返回非英语结果时参考
doc_embs = co.embed(texts=docs, model_id=model_id, input_type='search_document').embeddings
# 创建搜索索引
index = hnswlib.Index(space='ip', dim=1024)
index.init_index(max_elements=len(doc_embs), ef_construction=512, M=64)
index.add_items(doc_embs, list(range(len(doc_embs))))左右滑动查看完整示意
构建检索系统
接下来,我们构建一个函数,它将查询作为输入。嵌入它,即可找到与之最相关的四个标题:
# 检索与查询最相关的4个文档
def retrieval(query):
# 嵌入查询并检索结果
query_emb = co.embed(texts=[query], model_id=model_id, input_type="search_query").embeddings
doc_ids = index.knn_query(query_emb, k=3)[0][0] # 我们将检索4个最近邻
# 打印并附加结果
print(f"QUERY: {query.upper()} \n")
retrieved_docs, translated_retrieved_docs = [], []
for doc_id in doc_ids:
# 附加结果
retrieved_docs.append(docs[doc_id])
translated_retrieved_docs.append(translated_docs[doc_id])
# 打印结果
print(f"ORIGINAL ({docs_lang[doc_id]}): {docs[doc_id]}")
if docs_lang[doc_id] != "English":
print(f"TRANSLATION: {translated_docs[doc_id]} \n----")
else:
print("----")
print("END OF RESULTS \n\n")
return retrieved_docs, translated_retrieved_docs左右滑动查看完整示意
查询检索系统
让我们探索一下我们的系统对几个不同查询的处理情况。我们从英语开始:
queries = [
"Are businessees meeting sustainability goals?",
"Can data science help meet sustainability goals?"
]
for query in queries:
retrieval(query)左右滑动查看完整示意
结果如下:
QUERY: ARE BUSINESSES MEETING SUSTAINABILITY GOALS?
ORIGINAL (English): Quality of business reporting on the Sustainable Development Goals
improves, but has a long way to go to meet and drive targets.
----
ORIGINAL (English): Only 10 years to achieve Sustainable Development Goals but
businesses remain on starting blocks for integration and progress
----
ORIGINAL (Spanish): Integrar los criterios ESG y el propósito en la estrategia
principal reto de los Consejos de las empresas españolas en el mundo post-COVID
TRANSLATION: Integrate ESG criteria and purpose into the main challenge strategy
of the Boards of Spanish companies in the post-COVID world
----
END OF RESULTS
QUERY: CAN DATA SCIENCE HELP MEET SUSTAINABILITY GOALS?
ORIGINAL (English): Using AI to better manage the environment could reduce greenhouse
gas emissions, boost global GDP by up to 38m jobs by 2030
----
ORIGINAL (English): Quality of business reporting on the Sustainable Development Goals
improves, but has a long way to go to meet and drive targets.
----
ORIGINAL (English): Only 10 years to achieve Sustainable Development Goals but
businesses remain on starting blocks for integration and progress
----
END OF RESULTS左右滑动查看完整示意
注意以下几点:
我们提出的是相关但略有不同的问题,模型足够细致,能够在顶部呈现最相关的结果。
我们的模型不执行基于关键词的搜索,而是语义搜索。即使我们使用“数据科学”这样的术语而不是“人工智能”,我们的模型也能够理解所提出的问题,并在顶部返回最相关的结果。
那么丹麦语的查询呢?让我们看看以下查询:
query = "Hvor kan jeg finde den seneste danske boligplan?" # "在哪里可以找到最新的丹麦房地产计划?"
retrieved_docs, translated_retrieved_docs = retrieval(query)
QUERY: HVOR KAN JEG FINDE DEN SENESTE DANSKE BOLIGPLAN?
ORIGINAL (Danish): Nyt fra CFOdirect: Ny PP&E-guide, FAQs om den nye leasingstandard,
podcast om udfordringerne ved implementering af leasingstandarden og meget mere
TRANSLATION: New from CFOdirect: New PP&E guide, FAQs on the new leasing standard,
podcast on the challenges of implementing the leasing standard and much more
----
ORIGINAL (Danish): Lovforslag fremlagt om rentefri lån, udskudt frist for
lønsumsafgift, førtidig udbetaling af skattekredit og loft på indestående på
skattekontoen
TRANSLATION: Legislative proposal presented on interest-free loans, deferred payroll
tax deadline, early payment of tax credit and ceiling on deposits in the tax account
----
ORIGINAL (Danish): Nyt fra CFOdirect: Shareholder-spørgsmål til ledelsen, SEC
cybersikkerhedsguide, den amerikanske skattereform og meget mere
TRANSLATION: New from CFOdirect: Shareholder questions for management, the SEC
cybersecurity guide, US tax reform and more
----
END OF RESULTS左右滑动查看完整示意
在上面的示例中,英文缩写“PP&E”代表“property,plant and equipment”(房地产、厂房和设备),我们的模型能够将其与我们的查询联系起来。
在这种情况下,所有返回的结果都是丹麦语,但如果其他语言的文档的语义含义更接近,模型也可以返回其他语言的文档。我们拥有完全的灵活性,只需几行代码,就可以指定模型是只查看查询语言的文档,还是查看所有文档。
使用 Cohere Rerank 改善结果
嵌入功能非常强大。我们现在看看如何使用经过训练,以评分文档与查询的相关性的 Cohere Rerank 端点,进一步优化我们的结果。
Rerank 的另一个优点是它可以在传统的关键词搜索引擎之上工作,可以在 Amazon SageMaker 中使用。您不必改为使用向量数据库或对基础设施进行重大更改,只需几行代码即可。
Amazon SageMaker
https://aws.amazon.com/sagemaker/
让我们尝试一个新的查询。这次我们使用 Amazon SageMaker:
query = "Are companies ready for the next down market?"
retrieved_docs, translated_retrieved_docs = retrieval(query)
QUERY: ARE COMPANIES READY FOR THE NEXT DOWN MARKET?
ORIGINAL (Spanish): El valor en bolsa de las 100 mayores empresas cotizadas cae un 15%
entre enero y marzo pero aguanta el embate del COVID-19
TRANSLATION: The stock market value of the 100 largest listed companies falls 15%
between January and March but withstands the onslaught of COVID-19
----
ORIGINAL (English): 69% of business leaders have experienced a corporate crisis in the
last five years yet 29% of companies have no staff dedicated to crisis preparedness
----
ORIGINAL (English): As work sites slowly start to reopen, CFOs are concerned about the
global economy and a potential new COVID-19 wave - PwC survey
----
END OF RESULTS左右滑动查看完整示意
在这种情况下,语义搜索能够检索到我们的答案并将其显示在结果中,但它不在顶部。然而,当我们再次将查询传递给 Rerank 端点并提供检索到的文档列表时,Rerank 能够将最相关的文档置于顶部。
首先,我们创建客户端和 Rerank 端点:
# 映射模型包ARN
import boto3
cohere_package = "cohere-rerank-multilingual-v2--8b26a507962f3adb98ea9ac44cb70be1" # 替换为您的信息
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:865070037744:model-package/{cohere_package}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{cohere_package}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{cohere_package}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{cohere_package}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{cohere_package}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{cohere_package}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{cohere_package}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{cohere_package}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{cohere_package}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{cohere_package}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{cohere_package}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{cohere_package}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{cohere_package}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{cohere_package}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{cohere_package}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{cohere_package}",
}
region = boto3.Session().region_name
if region not in model_package_map.keys():
raise Exception(f"Current boto3 session region {region} is not supported.")
model_package_arn = model_package_map[region]
co = cohere_aws.Client(region_name=region)
co.create_endpoint(arn=model_package_arn, endpoint_name="cohere-rerank-multilingual", instance_type="ml.g4dn.xlarge", n_instances=1)左右滑动查看完整示意
当我们将文档传递给 Rerank 时,模型能够准确地选择最相关的文档:
results = co.rerank(query=query, documents=retrieved_docs, top_n=1)
for hit in results:
print(hit.document['text'])
69% of business leaders have experienced a corporate crisis in the last five years yet
29% of companies have no staff dedicated to crisis preparedness左右滑动查看完整示意
总结
本文介绍了如何在金融服务领域使用 Amazon Bedrock 中的 Cohere 多语种嵌入模型。通过演示了一个多语种金融文章搜索应用程序的示例,我们看到嵌入模型如何实现信息的高效准确发现,从而提高分析师的生产力和输出质量。
Cohere 的多语种嵌入模型支持超过 100 种语言。它消除了构建需要处理不同语言文档语料库的应用程序的复杂性。Cohere Embed 模型经过训练,可在实际应用中提供结果。它可以处理噪声数据输入,适应复杂的 RAG 系统,并通过其压缩感知训练方法提供成本效益。
立即在 Amazon Bedrock 中使用 Cohere 的多语种嵌入模型构建应用程序吧!
https://aws.amazon.com/cn/bedrock/cohere-command-embed/
本篇作者

James Yi
亚马逊云科技人工智能与机器学习高级合作伙伴解决方案架构师。

Gonzalo Betegon
Cohere 解决方案架构师。

Meor Amer
Cohere 开发者大使。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!
















 9251
9251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









