







概述
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
一个简单的示例
下面以一个简单的例子开始spark streaming的学习之旅!我们会从本机的7777端口源源不断地收到以换行符分隔的文本数据流
// 在本地启动名为SimpleDemo的SparkStreaming应用
// 该应用拥有两个线程,其批处理时间间隔为1s
// 创建SparkConf
val conf = new SparkConf().setMaster("local[2]").setAppName("SimpleDemo")
// 从SparkConf创建StreamingContext并指定1秒钟的批处理大小
val ssc = new StreamingContext(conf, Seconds(1))
// 创建ReceiverInputDStream,该InputDStream的Receiver监听本地机器的7777端口
val lines = ssc.socketTextStream("localhost", 7777) // 类型是ReceiverInputDStream
// 从DStream中筛选出包含字符串"error"的行,构造出了
// lines -> errorLines -> .print()这样一个DStreamGraph
val errorLines = lines.filter(_.contains("error"))
// 打印出含有"error"的行
errorLines.print()
让我们从创建StreamingContext 开始,它是流计算功能的主要入口。StreamingContext 会在底层创建出SparkContext,用来处理数据。其构造函数还接收用来指定多长时间处理一次新数据的批次间隔(batch interval)作为输入,这里我们把它设为1 秒。
接着,调用socketTextStream() 来创建出基于本地7777端口上收到的文本数据的DStream。然后把DStream 通过filter() 进行转化,只得到包含“error”的行。最后,使用输出操作print() 把一些筛选出来的行打印出来。
到此时只是设定好了要进行的计算步骤,系统收到数据时计算就会开始。要开始接收数据,必须显式调用StreamingContext 的start() 方法。这样,Spark Streaming 就会开始把Spark 作业不断交给下面的SparkContext 去调度执行。执行会在另一个线程中进行,所以需要调用awaitTermination 来等待流计算完成,来防止应用退出。
// 启动流计算环境StreamingContext并等待它"完成"
ssc.start()
// 等待作业完成
ssc.awaitTermination()
下面结合代码逐一分析SparkStreaming应用执行的过程
初始化StreamingContext以及产生输入DStream
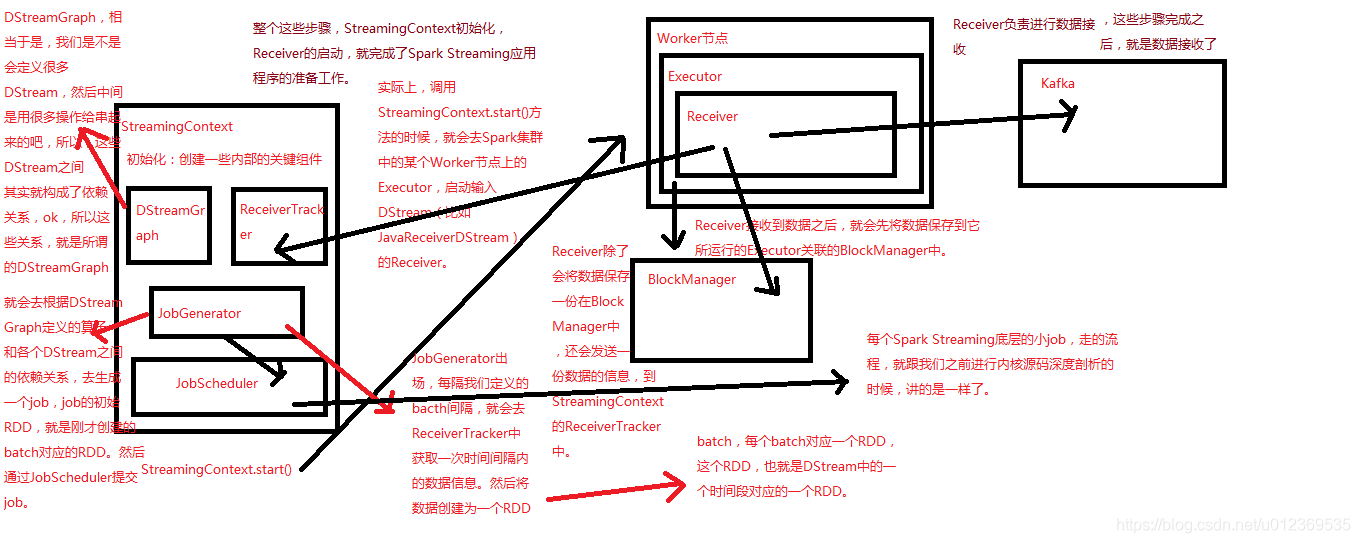
在Driver端中,StreamingContext初始化时会创建一些内部的关键组件如DStreamGraph、ReceiverTracker、JobGenerator和JobScheduler等。实际上,调用StreamingContext.start()方法的时候,就会在Spark集群中的某个Worker节点上的Executor,启动输入DStream的Receiver。
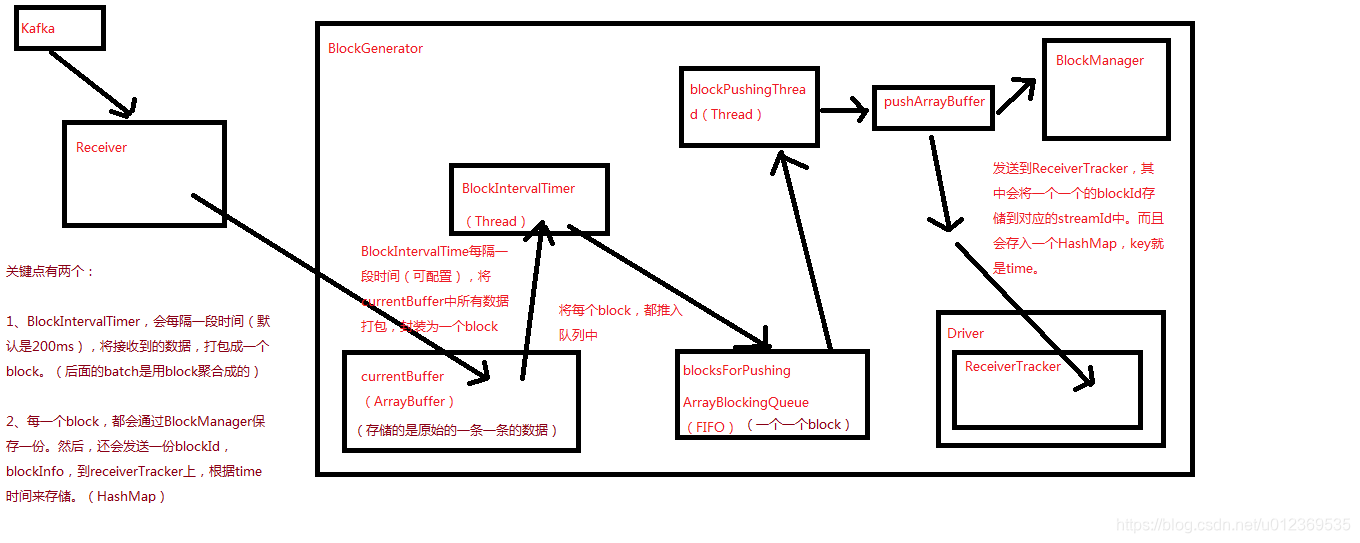
Receiver负责从外部数据源接收数据,Receiver接收到数据之后,会启动一个BlockGenerator,其会每隔一段时间(可配置,默认是200ms)将Receiver接收到的数据,打包成一个block,每个block除了会保存到所运行的Executor关联的BlockManager中之外,还会发送一份block信息如blockId到Driver端的ReceiverTracker上,其会将一个一个的block信息存入一个HashMap中,key就是时间。
记下来,JobGenerator会每隔我们定义的batch时间间隔,就会去ReceiverTracker中获取经过这个batch时间间隔内的数据信息blocks,将这些block聚合成一个batch,然后这个batch会被创建为一个RDD。
这样每隔一个batch时间间隔,都会将在这个时间间隔内接收的数据形成一个RDD,这样就会产生一个RDD序列,每个RDD代表数据流中一个时间间隔内的数据。正是这个RDD序列,形成SparkStreaming应用的输入DStream。
从宏观来说,Spark Streaming 使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming 从各种输入源中读取数据,并把数据分组为小的batch。新的batch按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的batch就创建出来,在该区间内收到的数据都会被添加到这个batch中。在时间区间结束时,batch停止增长。时间区间的大小是由batch间隔这个参数决定的。batch间隔一般设在500 毫秒到几秒之间,由应用开发者配置。每个输入batch都形成一个RDD,以Spark 作业的方式处理并生成其他的RDD。处理的结果可以以批处理的方式传给外部系统。

StreamingContext初始化后,包括Receiver启动后,再到生成输入DStream,就完成了SparkStreaming应用程序的准备工作。
DStream的转化操作
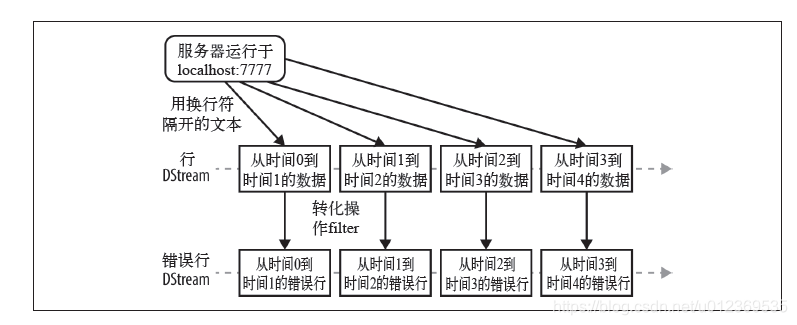
在创建好输入DStream后,对其调用了filter()算子,filter()算子是转化操作,会将操作应用到DStream的每一个RDD。
一些常见的转化操作如下图

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream 在内部是由许多RDD(批次)组成,且这些转化操作是分别应用到每个RDD 上的。例如,filter()会对DStream内的每个时间区间的数据(RDD)进行过滤,reduceByKey() 会归约每个RDD中的数据,但不会归约不同区间之间的数据。
对于本文的示例,对输入DStream作filter操作后生成新的DStream的过程如下:
DStream的输出操作
Spark Streaming允许DStream的数据输出到外部系统,如数据库或文件系统,输出的数据可以被外部系统所使用,该操作类似于RDD的输出操作。
在Spark核心中,作业是由一系列具有依赖关系的RDD及作用于这些RDD上的算子函数所组成的操作链。在遇到行动操作时触发运行,向DAGScheduler提交并运行作业。Spark Streaming中作业的生成与Spark核心类似,对DStream进行的各种操作让它们之间构建起依赖关系。
当遇到DStream使用输出操作时,这些依赖关系以及它们之间的操作会被记录到名为DStreamGraph的对象中表示一个job。这些job注册到DStreamGraph并不会立即运行,而是等到Spark Streaming启动后,到达批处理时间时,才根据DSteamGraph生成job处理该批处理时间内接收的数据。在Spark Streaming如果应用程序中存在多个输出操作,那么在批处理中会产生多个job。
与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。
常用的一种调试性输出操作是print(),它会在每个批次中抓取DStream的前十个元素打印出来。
一些常用的输出操作如下

Spark Streamin运行架构
总体来说,Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是Spark Streaming将输入数据按照batch interval(如5秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对DSteam内各个RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备
假设batchInterval = 5s, SparkStreaming启动之后,0-5s内一直接受数据,假设SparkStreaming处理这一个批次数据的时间是3s,那么5-8s内一边接收新数据(开始第二批次),同时会触发DStream的job执行,这时会启动另一个线程处理第一批次的数据;8-10s内只是接收数据(还是第二批次);10-13s内一边接收新数据(开始第三批次),一边处理第二批次的数据,然后13-15s只是接收数据(还是第三批次),如此往复进行数据的接收与处理。
Spark Streaming相对其他流处理系统最大的优势在于流处理引擎和数据处理在同一个软件栈,其中Spark Streaming功能主要包括流处理引擎的数据接收与存储以及批处理作业的生成与管理,而Spark核心负责处理Spark Streaming发送过来的作业。
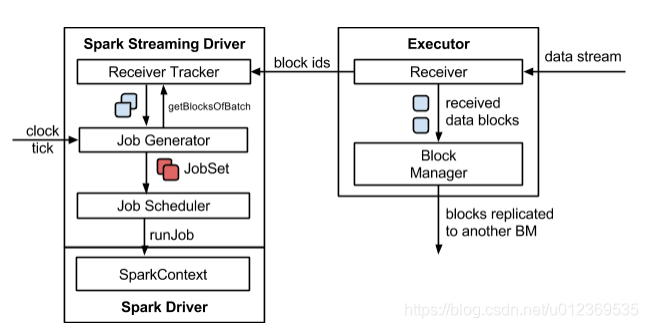
Spark Streaming分为Driver端和Client端,运行在Driver端为StreamingContext实例。该实例包括DStreamGraph和JobScheduler(包括ReceiverTracker和JobGenerator)等,而Client包括ReceiverSupervisor和Receiver等。
SparkStreaming进行流数据处理大致可以分为:启动流处理引擎、接收及存储流数据、处理流数据和输出处理结果等4个步骤,其运行架构如下
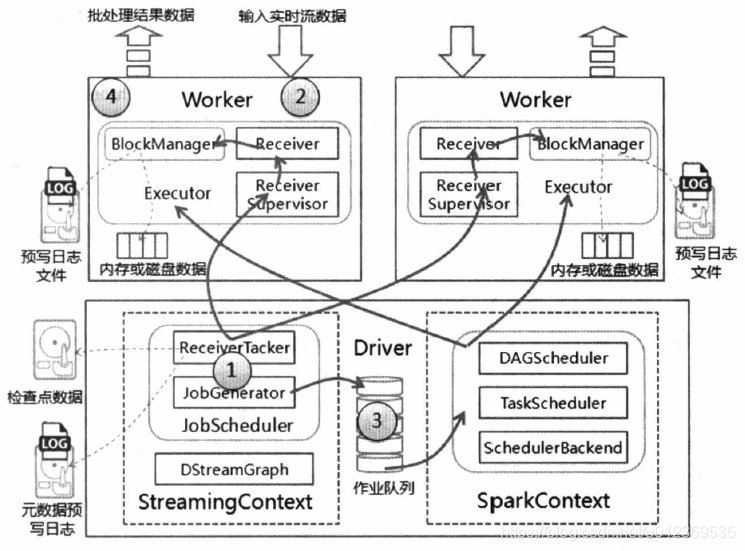
(1) 初始化StreamingContext对象,在该对象启动过程中实例化DStreamGraph和JobScheduler,其中DStreamGraph用于存放DStream以及DStream之间的依赖关系等信息,而JobScheduler中包括ReceiverTracker和JobGenerator。其中ReceiverTracker为Driver端流数据接收器(Receiver)的管理者,JobGenerator为批处理作业生成器。在ReceiverTracker启动过程中,根据流数据接收器分发策略通知对应的Executor中的流数据接收管理器(ReceiverSupervisor)启动,再由ReceiverSupervisor启动流数据接收器Receiver。
(2) 当流数据接收器Receiver启动后,持续不断地接收实时流数据,根据传过来数据的大小进行判断,如果数据量很小,则攒多条数据成一块,然后再进行块存储;如果数据量大,则直接进行块存储。对于这些数据Receiver直接交给ReceiverSupervisor,由其进行数据转储操作。块存储根据是否设置预写日志分为两种,一种是使用非预写日志BlockManagerBasedBlockHandler方法直接写到Worker的内存或磁盘中,另一种是进行预写日志WriteAheadLogBasedBlockHandler方法,即在预写日志同时把数据写入到Worker的内存或磁盘中。数据存储完毕后,ReceiverSupervisor会把数据存储的元信息上报给ReceiverTracker,ReceiverTracker再把这些信息转发给ReceiverBlockTracker,由它负责管理收到的数据块的元信息。
(3) 在StreamingContext的JobGenerator中维护一个定时器,该定时器在批处理时间到来时会进行生成作业的操作。在该操作中进行如下操作:
- 通知ReceiverTracker将接收到的数据进行提交,在提交时采用synchronized关键字进行处理,保证每条数据被划入一个且只被划入一个批次中。
- 要求DStreamGraph根据DSream依赖关系生成作业序列Seq[Job]。
- 从第一步中ReceiverTracker获取本批次数据的元数据。
- 把批处理时间time、作业序列Seq[Job]和本批次数据的元数据包装为JobSet,调用JobScheduler.submitJobSet(JobSet)提交给JobScheduler,JobScheduler将把这些作业发送给Spark核心进行处理,由于该执行为异步,因此本步执行速度将非常快。
- 只要提交结束(不管作业是否被执行),SparkStreaming对整个系统做一个检查点(Checkpoint)。
(4) 在Spark核心的作业队数据进行处理,处理完毕后输出到外部系统,如数据库或文件系统,输出的数据可以被外部系统所使用。由于实时流数据的数据源源不断地流入,Spark会周而复始地进行数据处理,相应地也会持续不断地输出结果。
注意事项
1、local模式下需要启动至少两个线程,因为只开启了一条线程(这里只有接收数据的线程,却没有处理数据的线程),所以local模式下SparkStreaming必须至少设置两个线程
new SparkConf().setMaster("local[2]").setAppName("SimpleDemo");
2、Durations时间的设置–接收数据划分批次的时间间隔,多久触发一次job
new StreamingContext(conf, Seconds(1))
3、业务逻辑完成后,需要有一个输出操作,将SparkStreaming处理后的数据输出到外部存储系统
4、关于 StreamingContext 的 start()和 stop()
StreamingContext.start() //Spark Streaming应用启动之后是不能再添加业务逻辑
StreamingContext.stop() //无参的stop方法会将SparkContext一同关闭,解决办法:stop(false)
StreamingContext.stop() //停止之后是不能在调用start()
5、DStreams(Discretized Streams–离散的流),应用在每个DStream的算子操作,会应用在DStream内的各个RDD,进而应用在RDD的各个Partition,应用在Partition中的一条条数据,最终应用到每一条记录上
参考
《Spark快速大数据分析》
《图解Spark核心技术与案例实战》














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









