







基于Window窗口的转化操作
基于窗口的操作会在一个比StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
滑动窗口转换操作的计算过程如下图所示,我们可以事先设定一个滑动窗口的长度(也就是窗口的持续时间),并且设定滑动窗口的时间间隔(每隔多长时间执行一次计算),然后,就可以让窗口按照指定时间间隔在源DStream上滑动,每次窗口停放的位置上,都会有一部分DStream的数据被框入窗口内,形成一个小段的DStream,这时,就可以启动对这个小段DStream的计算。
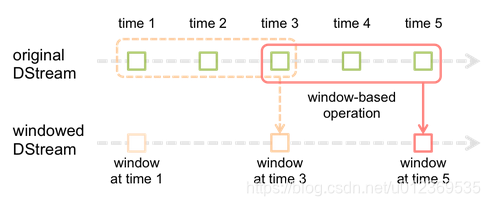
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是
StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的windowDuration/batchInterval 个批次。如果有一个以10 秒为批次间隔的源DStream,要创建一个最近30 秒的时间窗口(即最近3 个批次),就应当把windowDuration设为30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的DStream 进行计算的间隔。如果源DStream 批次间隔为10 秒,并且我们只希望每两个批次计算一次窗口结果,就应该把滑动步长设置为20 秒。
对DStream 可以用的最简单窗口操作是window(),它返回一个新的DStream 来表示所请求的窗口操作的结果数据。换句话说,window() 生成的DStream 中的每个RDD 会包含多个批次中的数据,可以对这些数据进行count()、transform() 等操作。
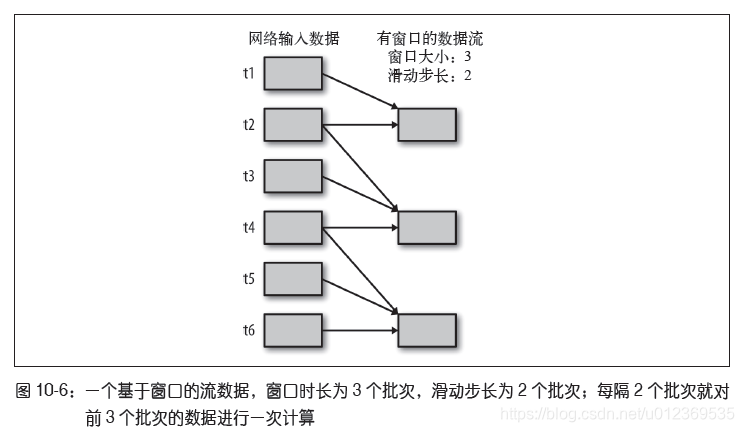
如上图,假设批次的时间间隔为t1,第一列为输入DStream,第二列为经过窗口操作的DStream,每次掉落在窗口内的批次数据(RDD),会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。当时间为t2时,已经过了两个批次,此时将最近2个批次的数据聚合起来进行窗口操作;从t2又经过了两个批次后来到t4,此时将最近的3个批次即t2、t3和t4的数据聚合起来进行窗口操作;从t4又经过两个批次后来到t6,将最近的t4、t5和t6批次的数据聚合经窗口操作形成新的window DStream,最后window DStream包含3个RDD。
val accessLogsWindow = accessLogsDStream.window(Seconds(30), Seconds(10))
val windowCounts = accessLogsWindow.count() // 统计windowDStream中每个RDD的元素数量
尽管可以使用window() 写出所有的窗口操作,Spark Streaming 还是提供了一些其他的窗口操作,让用户可以高效而方便地使用。
首先,reduceByWindow() 和reduceByKeyAndWindow()让我们可以对每个窗口更高效地进行归约操作。它们接收一个归约函数,在整个窗口上执行,比如+。reduceByWindow()操作的示意图如下:窗口时长为4,滑动时长为1
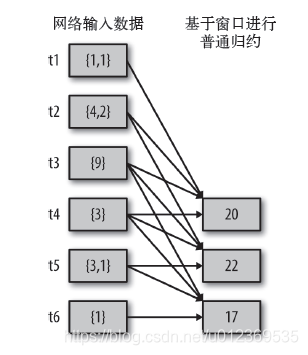
reduceByKeyAndWindow实现热点搜索词滑动统计
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数。
案例:热点搜索词滑动统计,每隔10s,统计最近60s内搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及其出现次数
package com.spark_streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object windowHotWord {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("windowHotWord")
val ssc = new StreamingContext(conf, Seconds(5))
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val searchLogDStream = ssc.socketTextStream("master", 9999)
val searchWordDStream = searchLogDStream.map(_.split(" ")(1))
val searchWordPairsDStream = searchWordDStream.map((_, 1))
// 计算window内搜索词出现的次数
val searchWordCountDStream = searchWordPairsDStream.reduceByKeyAndWindow(
(a:Int, b:Int) => a + b,
Seconds(60),
Seconds(10))
// 计算window内排名前3
searchWordCountDStream.foreachRDD(searchWordCountRdd => {
val countSearchWordRDD = searchWordCountRdd.map(tuple => (tuple._2, tuple._1)) //Tuple(Int, String)
val sortedSearcWordRDD = countSearchWordRDD.sortByKey(false)
val sortedWordCountRDD = sortedSearcWordRDD.map(tuple => (tuple._2, tuple._1))
val top3HotWordRDD = sortedWordCountRDD.take(3)
println("-----top start----")
for(tuple <- top3HotWordRDD)
println(tuple)
println("-----top end -----")
})
ssc.start()
ssc.awaitTermination()
}
}
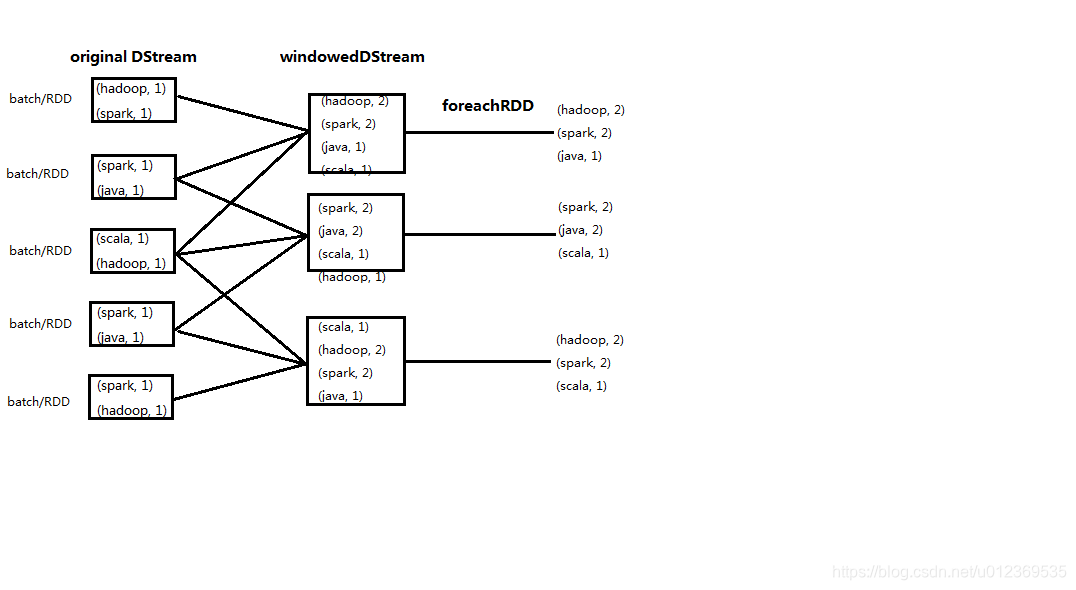
在使用reduceByKeyAndWindow()计算出搜索词的出现次数后使用了一个输出操作foreachRDD(),它用来对DStream中的RDD运行任意计算。在foreachRDD()中,可以重用在Spark core中的所有行动操作,这里是对RDD内的数据作排序取出前三。
输入测试数据:
[root@master ~]# nc -lk 9999
zhang scala
li hadoop
wang spark
li jaav
zhang hadoop
li java
wang spark
sun spark
zhao hadoop
wang java
li scala
zhang java
qian spak
wang hadoop
zhnag java
zhang spark
liu scala
输出结果:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
19/06/22 17:06:13 INFO SparkContext: Running Spark version 2.0.2
19/06/22 17:06:16 INFO SecurityManager: Changing view acls to: zby
19/06/22 17:06:16 INFO SecurityManager: Changing modify acls to: zby
19/06/22 17:06:16 INFO SecurityManager: Changing view acls groups to:
19/06/22 17:06:16 INFO SecurityManager: Changing modify acls groups to:
19/06/22 17:06:16 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(zby); groups with view permissions: Set(); users with modify permissions: Set(zby); groups with modify permissions: Set()
19/06/22 17:06:17 INFO Utils: Successfully started service 'sparkDriver' on port 51328.
19/06/22 17:06:17 INFO SparkEnv: Registering MapOutputTracker
19/06/22 17:06:17 INFO SparkEnv: Registering BlockManagerMaster
19/06/22 17:06:17 INFO DiskBlockManager: Created local directory at C:\Users\zby\AppData\Local\Temp\blockmgr-fe6e9b7c-0564-497d-a1a5-37adaa45581d
19/06/22 17:06:17 INFO MemoryStore: MemoryStore started with capacity 867.6 MB
19/06/22 17:06:17 INFO SparkEnv: Registering OutputCommitCoordinator
19/06/22 17:06:18 INFO Utils: Successfully started service 'SparkUI' on port 4040.
19/06/22 17:06:18 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.47.1:4040
19/06/22 17:06:18 INFO Executor: Starting executor ID driver on host localhost
19/06/22 17:06:18 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 51341.
19/06/22 17:06:18 INFO NettyBlockTransferService: Server created on 192.168.47.1:51341
19/06/22 17:06:18 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.47.1, 51341)
19/06/22 17:06:18 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.47.1:51341 with 867.6 MB RAM, BlockManagerId(driver, 192.168.47.1, 51341)
19/06/22 17:06:18 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.47.1, 51341)
-----top start----
-----top end -----
-----top start----
-----top end -----
-----top start----
(scala,1)
-----top end -----
-----top start----
(scala,1)
(jaav,1)
(spark,1)
-----top end -----
-----top start----
(spark,3)
(hadoop,2)
(scala,1)
-----top end -----
-----top start----
(spark,3)
(hadoop,3)
(scala,2)
-----top end -----
-----top start----
(java,3)
(spark,3)
(hadoop,3)
-----top end -----
-----top start----
(java,4)
(spark,4)
(hadoop,4)
-----top end -----
-----top start----
(java,4)
(spark,4)
(hadoop,4)
-----top end -----
-----top start----
(java,4)
(spark,3)
(hadoop,3)
-----top end -----
-----top start----
(java,3)
(scala,2)
(hadoop,2)
-----top end -----
-----top start----
(java,2)
(scala,1)
(spak,1)
-----top end -----
-----top start----
(scala,1)
(java,1)
(spark,1)
-----top end -----
-----top start----
(scala,1)
-----top end -----
-----top start----
-----top end -----
Process finished with exit code 1














 8466
8466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









