







1.Kafka Stream?
Kafka Streams是一套处理分析Kafka中存储数据的客户端类库,处理完的数据或者写回Kafka,或者发送给外部系统。它构建在一些重要的流处理概念之上:区分事件时间和处理时间、开窗的支持、简单有效的状态管理等。Kafka Streams入门的门槛很低:很容易编写单机的示例程序,然后通过在多台机器上运行多个实例即可水平扩展从而达到高吞吐量。Kafka Streams利用Kafka的并发模型以实现透明的负载均衡。
一些亮点:
• 设计成简单和轻量级的客户端类库,可以和现有Java应用、部署工具轻松整合。
• 除了Kafka自身外不依赖其他外部系统。利用Kafka的分区模型来实现水平扩展并保证有序处理。
• 支持容错的本地状态,这使得快速高效处理一些有状态的操作(如连接和开窗聚合)成为可能。
• 支持一次一条记录的处理方式以实现低延迟,也支持基于事件时间的开窗操作。
• 提供了两套流处理原语:高层的流DSL和低层的处理器API。
核心概念
2. Stream Processing Topology(流处理拓扑)
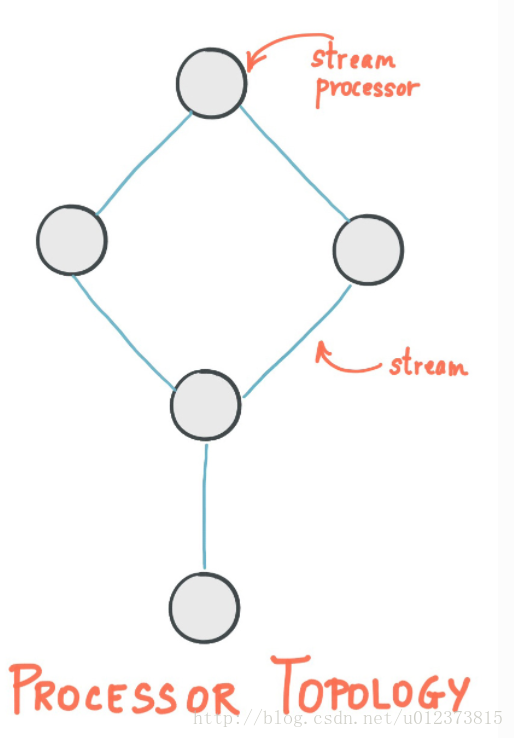
1、stream是Kafka Stream最重要的抽象,它代表了一个无限持续的数据集。stream是有序的、可重放消息、对不可变数据集支持故障转移
2、一个流处理应用程序通过一或多个“处理器拓扑(processor topology)”来定义其计算逻辑,一个processor topology就是一张以流处理器(stream processor、节点)和流[streams](边)构成的图。(实际为DAG,太熟悉了吧,多么类似spark Streaming)
3、一个stream processor是processor topology中的一个节点,它代表一个在stream中的处理步骤:从上游processors接受数据、进行一些处理、最后发送一到多条数据到下游processors
Kafka Stream提供两种开发流处理拓扑(stream processing topology)的API
- 1、high-level Stream DSL:提供通用的数据操作,如map和fileter
- 2、lower-level Processor API:提供定义和连接自定义processor,同时跟state store(下文会介绍)交互
3. 时间
时间的概念在流处理中很关键,比如开窗这种操作就是根据时间边界来定义的。上面也提到过两个常见概念:
• 事件时间:事件或数据记录发生的时刻。
• 处理时间:事件或数据记录被流处理应用开始处理的时刻,比如记录开始被消费。处理时间可能比事件时间晚几毫秒到几天不等。
• 摄取时间:数据记录由KafkaBroker保存到 kafka topic对应分区的时间点。摄取时间类似事件时间,都是一个嵌入在数据记录中的时间戳字段。不同的是,摄取时间是由Kafka Broker附加在目标Topic上的,而不是附加在事件源上的。如果事件处理速度足够快,事件产生时间和写入Kafka的时间差就会非常小,这主要取决于具体的使用情况。因此,无法在摄取时间和事件时间之间进行二选一,两个语义是完全不同的。同时,数据还有可能没有摄取时间,比如旧版本的Kafka或者生产者不能直接生成时间戳(比如无法访问本地时钟。)。
事件时间和摄取时间的选择是通过在Kafka(不是KafkaStreams)上进行配置实现的。从Kafka 0.10.X起,时间戳会被自动嵌入到Kafka的Message中,可以根据配置选择事件时间或者摄取时间。配置可以在broker或者topic中指定。Kafka Streams默认提供的时间抽取器会将这些嵌入的时间戳恢复原样。
Kafka Stream 使用TimestampExtractor 接口为每个消息分配一个timestamp,具体的实现可以是从消息中的某个时间字段获取timestamp以提供event-time的语义或者返回处理时的时钟时间,从而将processing-time的语义留给开发者的处理程序。开发者甚至可以强制使用其他不同的时间概念来进行定义event-time和processing time。
注意:Kafka Streams中的摄取时间和其他流处理系统略有不同,其他流处理系统中的摄取时间指的是从数据源中获取到数据的时间,而kafka Streams中,摄取时间是指记录被追加到Kakfa topic中的时间。
3. 状态
有些stream应用不需要state,因为每条消息的处理都是独立的。然而维护stream处理的状态对于复杂的应用是非常有用的,比如可以对stream中的数据进行join、group和aggreagte,Kafka Stream DSL提供了这个功能。
Kafka Stream使用state stores(状态仓库)提供基于stream的数据存储和数据查询状态数据,每个Kafka Stream内嵌了多个state store,可以通过API存取数据,这些state store的实现可以是持久化的KV存储引擎、内存HashMap或者其他数据结构。Kafka Stream提供了local state store的故障转移和自动发现。
4. KStream和KTable(流和表的双重性)
Kafka Stream定义了两种基本抽象:KStream 和 KTable,区别来自于key-value对值如何被解释,
4.1KStream:
一个纯粹的流就是所有的更新都被解释成INSERT语句(因为没有记录会替换已有的记录)的表。
在一个流中(KStream),每个key-value是一个独立的信息片断,比如,用户购买流是:alice->黄油,bob->面包,alice->奶酪面包,我们知道alice既买了黄油,又买了奶酪面包。
4.2KTable(changelog流):
KTable 一张表就是一个所有的改变都被解释成UPDATE的流(因为所有使用同样的key的已存在的行都会被覆盖)。
对于一个表table( KTable),是代表一个变化日志,如果表包含两对同样key的key-value值,后者会覆盖前面的记录,因为key值一样的,比如用户地址表:alice -> 纽约, bob -> 旧金山, alice -> 芝加哥,意味着Alice从纽约迁移到芝加哥,而不是同时居住在两个地方。
KTable 还提供了通过key查找数据值得功能,该查找功能可以用在Join等功能上。
这两个概念之间有一个二元性,一个流能被看成表,而一个表也可以看成流。
5.低层处理器API
5.1处理器
开发着通过实现Processor接口并实现process和punctuate方法,每条消息都会调用process方法,punctuate方法会周期性的被调用
5.2处理器拓扑
有了在处理器API中自定义的处理器,然后就可以使用TopologyBuilder来将处理器连接到一起从而构建处理器拓扑:
5.3本地状态仓库
处理器API不仅可以处理当前到达的记录,也可以管理本地状态仓库以使得已到达的记录都可用于有状态的处理操作中(如聚合或开窗连接)。为利用本地状态仓库的优势,可使用TopologyBuilder.addStateStore方法以便在创建处理器拓扑时创建一个相应的本地状态仓库;或将一个已创建的本地状态仓库与现有处理器节点连接,通过TopologyBuilder.connectProcessorAndStateStores方法。
6.高层流DSL
为使用流DSL来创建处理器拓扑,可使用KStreamBuilder类,其扩展自TopologyBuilder类。Kafka的源代码中在streams/examples包中提供了一个示例。
6.1从Kafka创建源端流
Kafka Streams为高层流定义了两种基本抽象:记录流(定义为KStream)可从一或多个Kafka topic源来创建,更新日志流(定义为KTable)可从一个Kafka topic源来创建。
KStream可以从多个kafka topic中创建,而KTable只能单个topic
KStreamBuilder builder = new KStreamBuilder();
KStream source1 = builder.stream("topic1", "topic2");
KTable source2 = builder.table("topic3"); 6.2转换一个流
KStream和KTable相应地都提供了一系列转换操作。每个操作可产生一或多个KStream和KTable对象,可被翻译成一或多个相连的处理器。所有这些转换方法连接在一起形成一个复杂的处理器拓扑。因为KStream和KTable是强类型的,这些转换操作都被定义为泛类型,使得用户可指定输入和输出数据类型。
这些转换中,filter、map、mapValues等是无状态的,可用于KStream和KTable两者,通常用户会传一个自定义函数给这些函数作为参数,例如Predicate给filter,KeyValueMapper给map等:
无状态的转换不依赖于处理的状态,因此不需要状态仓库。有状态的转换则需要存取相应状态以处理和生成结果。例如,在join和aggregate操作里,一个窗口状态用于保存当前预定义窗口中收到的记录。于是转换可以获取状态仓库中累积的记录,并执行计算。
6.3 写回到kafka(Write streams back to Kafka)
最后,开发者可以将最终的结果stream写回到kafka,通过 KStream.to and KTable.to
joined.to("topic4"); 如果应用希望继续读取写回到kafka中的数据,方法之一是构造一个新的stream并读取kafka topic,Kafka Stream提供了另一种更方便的方法:through
joined.to("topic4");
materialized = builder.stream("topic4");
KStream materialized = joined.through("topic4"); 7.窗口
一个流处理器可能需要将数据划分为多个时间段,这就是流上窗口。这通常在Join或者aggregation聚合等保存本地状态的处理程序中使用。
Kafka StreamsDSL API提供了可用的窗口操作,用户可以指定数据在窗口中的保存期限。这就允许Kafka Streams在窗口中保留一段时间的旧数据以等待其它晚到的数据。如果保留期过了之后数据才到达,这条消息就不能被处理,会被丢掉。
实时的流处理系统中,数据乱序总是存在的,这主要取决于数据在有效时间内如何进行处理。对于在正处于处理期的时间内的数据,如果数据乱序,延迟到达,在语义上就可以被正常处理,如果数据到达时候,已经不在处理期,那么这种数据就不适合处理期的语义,只能被丢弃掉。
8. Join
Join操作负责在Key上对两个流的记录进行合并,并产生新流。一个基于流上的Join通常是基于窗口的,否则所有数据就都会被保存,记录就会无限增长。
KafkaStreams DSL支持不同的Join操作,比如KStram和KStream之间的Join,以及KStream和KTable之间的Join。
9. Aggregations
聚合操作需要一个输入流,并且以多个输入记录为单位组合成单个记录并产生新流。常见的聚合操作有count和sum。流上的聚合也必须基于窗口进行,否则数据和join一样都会无限制增长。
在Kafka Streams的DSL中,一个聚合输入流可以是KStream形式或者KTable形式,但是输出流永远都是KTable。这就使得Kafka Streams的输出结果会被不断更新,这样,当有数据乱序到达之后,数据也可以被及时更新,因为最终输出是KTable,新key会覆盖旧值。
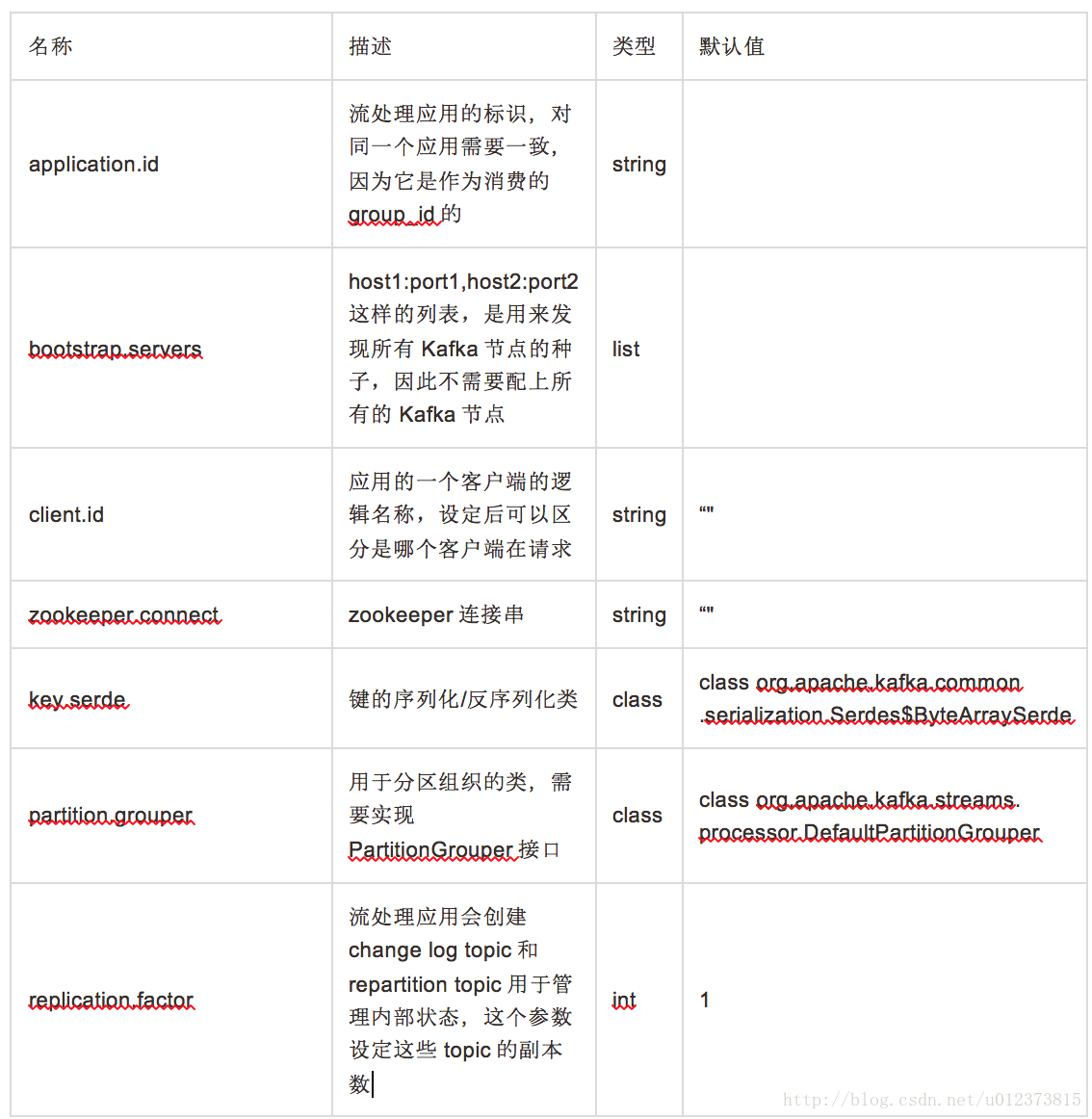
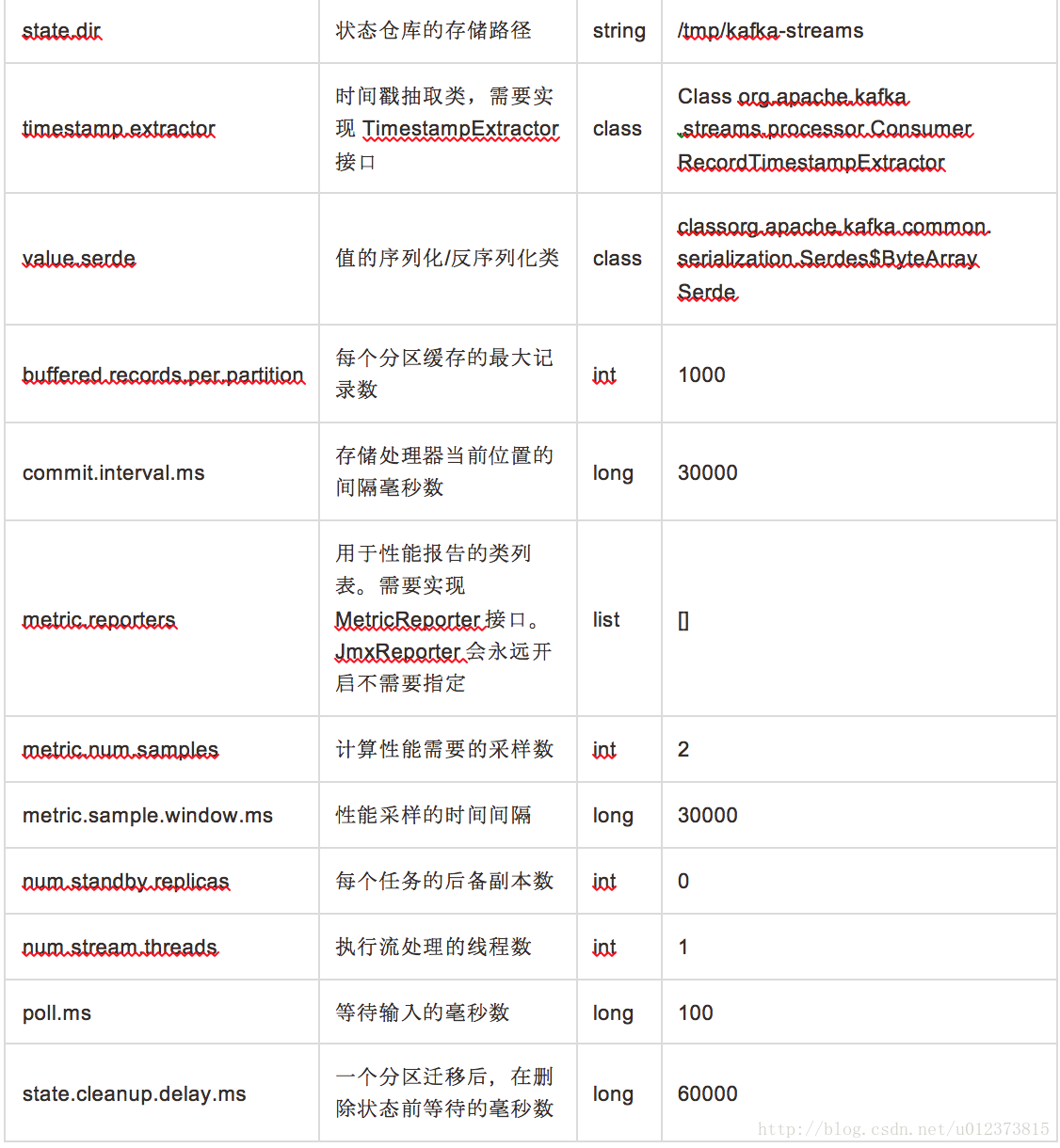
配置参数
参考文章:http://blog.csdn.net/mayp1/article/details/51626643
http://blog.csdn.net/ransom0512/article/details/52038548














 6827
6827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









