










《机器学习技法》作业

这一题的思路,先bagging,再产生决策树,再平均。
1. 不知道bagging怎么取,用一棵树的随机森林替代。
from __future__ import division
from sklearn.ensemble import RandomForestClassifier
import numpy as np
data = np.loadtxt('hw3_train.dat') #直接读取成numpy.ndarray的形式
train_x = data[:,:-1]
train_y = data[:,-1]
total = 0
for i in range(30000):
clf = RandomForestClassifier(n_estimators=1, max_features=None)
clf = clf.fit(train_x, train_y)
err_in = 1 - clf.score(train_x, train_y)
total = total + err_in
print i, err_in
print total/300002. 大爷提醒,可以一次产生N的随机树,就取出来了。
from __future__ import division
from sklearn import tree
import numpy as np
import random
data = np.loadtxt('hw3_train.dat') #直接读取成numpy.ndarray的形式
train_x = data[:,:-1]
train_y = data[:,-1]
N = len(train_y)
total = 0
for i in range(30000):
r = np.random.randint(0, N, N)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(train_x[r,:], train_y[r])
err_in = 1 - clf.score(train_x, train_y)
total = total + err_in
print i, err_in
print total/30000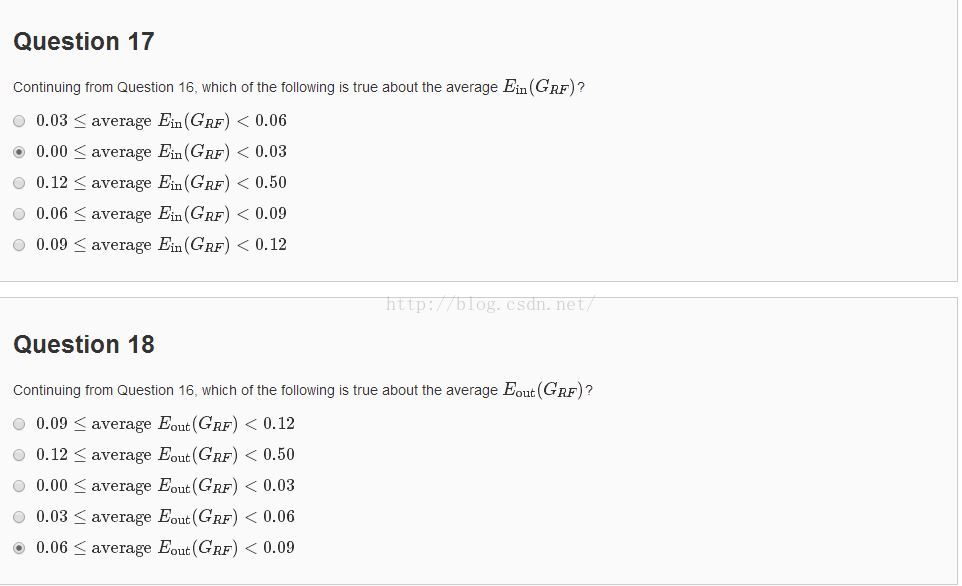
17、18算forest就好算多了。
from __future__ import division
from sklearn.ensemble import RandomForestClassifier
import numpy as np
data = np.loadtxt('hw3_train.dat') #直接读取成numpy.ndarray的形式
train_x = data[:,:-1]
train_y = data[:,-1]
data = np.loadtxt('hw3_test.dat') #直接读取成numpy.ndarray的形式
test_x = data[:,:-1]
test_y = data[:,-1]
total = 0
for i in range(100):
clf = RandomForestClassifier(n_estimators=300, max_features=None)
clf = clf.fit(train_x, train_y)
err_in = 1 - clf.score(test_x, test_y)
total = total + err_in
print i, err_in
print total/100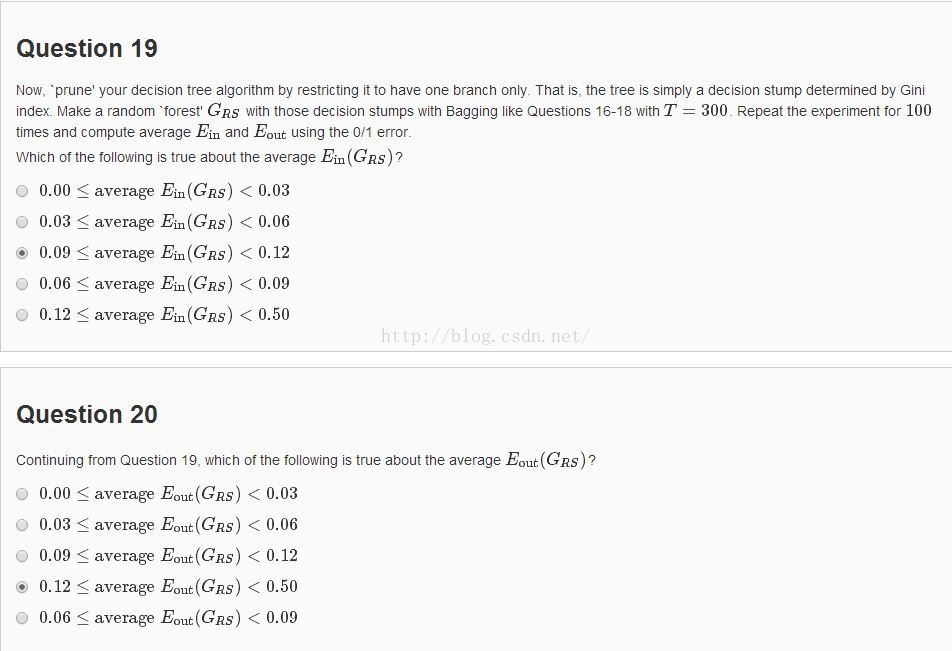
这个剪一下枝就好了。
from __future__ import division
from sklearn.ensemble import RandomForestClassifier
import numpy as np
data = np.loadtxt('hw3_train.dat') #直接读取成numpy.ndarray的形式
train_x = data[:,:-1]
train_y = data[:,-1]
data = np.loadtxt('hw3_test.dat') #直接读取成numpy.ndarray的形式
test_x = data[:,:-1]
test_y = data[:,-1]
total_in = 0
total_out = 0
for i in range(100):
clf = RandomForestClassifier(n_estimators=300, max_depth=1, max_features=None)
clf = clf.fit(train_x, train_y)
err_in = 1 - clf.score(train_x, train_y)
err_out = 1 - clf.score(test_x, test_y)
total_in = total_in + err_in
total_out = total_out + err_out
print i, "err_in:",err_in, "err_out:",err_out
print total_in/100
print total_out/100














 1756
1756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









