









基本概念
这里将 PushbackInputStream 和 PushbackReader 放到一起讨论主要是二者的原理机制几乎一模一样,掌握其一即可。它们分别表示 字节推回流、字符推回流。
退回:其实就是将从流读取的数据再推回到流中。实现原理也很简单,通过一个缓冲数组来存放推回的数据,每次操作时先从缓冲数组开始,然后再操作流对象。
继承关系:


实例探究
比如下面的代码中将[ a,b,c,d] 推回流,也可以将 [x,y,z,u] 推回流,那么下一次的读取结果就变成了 [x,y,z,u,h,i,j]。
public class Test {
// 英文字母
private static final byte[] ArrayLetters = {
0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67,
0x68, 0x69, 0x6A, 0x6B, 0x6C, 0x6D, 0x6E,
0x6F, 0x70, 0x71, 0x72, 0x73, 0x74, 0x75,
0x76, 0x77, 0x78, 0x79,0x7A };
public static void main(String args[]) throws Exception {
read();
}
private static void read() throws IOException {
//创建字节推回流,缓冲区大小为 7
PushbackInputStream pis = new PushbackInputStream(new ByteArrayInputStream(ArrayLetters),7);
byte[] buffer = new byte[7];
//从流中将7个字节读入数组,如 a,b,c,d,e,f,g
pis.read(buffer);
System.out.println(new String(buffer));
//从数组的第一个位置开始,推回 4 个字节到流中,即推回 a,b,c,d
pis.unread(buffer,0,4);
//重新从流中将字节读取数组,输出 a,b,c,d,h,i,j
pis.read(buffer);
System.out.println(new String(buffer));
}
}原理讲解
①创建字节推回流,推回缓冲区指定大小为 7;要从字节输入流读取字节到 buffer 数组
- 缓冲区

- 输入流,这里以上面的代码为例子,字节数组输入流中有 26 个字节(偷懒只画 8 个)

- buffer 数组
②从流中读取 7 个字节到 buffer数组
- 缓冲区
- 输入流

- buffer 数组

③现在要从 buffer 的 0 下标(第一个位置)开始,推回 4 个字节到流中去(实质是推回到缓冲数组中去)。
- 缓冲区,字节被推回到缓冲区,从末端开始存放

- 输入流
- buffer 数组
④再次进行读取操作,首先从缓冲区开始读取,再对流进行操作
- 缓冲区
- 输入流 ,后面的数据没有画出来
- buffer 数组

源码分析
1.PushbackInputStream
类结构图
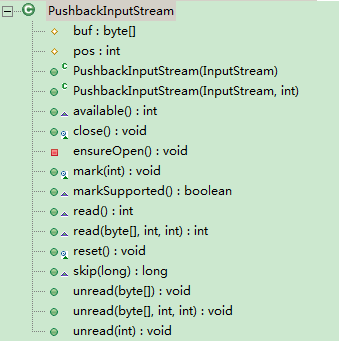
成员变量
// 推回缓冲区,推回流的字节会被保存在这里
protected byte[] buf;
// 推回缓冲区中的索引位置,默认从 buf.length 开始,即从数组末尾写入数据
protected int pos;构造函数,它真正只做了两件事:
获取要操作(要过滤)的流
创建推回缓冲数组
//①构造函数,创建指定大小的退回缓冲区
public PushbackInputStream(InputStream in, int size) {
//获取要操作的流
super(in);
if (size <= 0) {
throw new IllegalArgumentException("size <= 0");
}
//创建推回缓冲区,索引位置默认为 size;
this.buf = new byte[size];
this.pos = size;
}
//②构造函数,创建默认大小为 1 的退回缓冲区
public PushbackInputStream(InputStream in) {
this(in, 1);
}read 方法,这里只定义了两种读取方式。
// ①从此输入流中读取下一个数据字节
public int read() throws IOException {
// 确保要操作的流不为空(即没有关闭),下面会提到
ensureOpen();
// 上面说一开始这两个参数相等,不相等说明缓冲数组有数据,即表明了进行过推回操作
if (pos < buf.length) {
// 默认先从缓冲数组读取数据
return buf[pos++] & 0xff;
}
//调用流本身的读取方法
return super.read();
}
// ②从此输入流将最多 len 个数据字节读入 byte 数组
public int read(byte[] b, int off, int len) throws IOException {
ensureOpen();
//判断参数的合法性
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
//判断 avail 是否为 0,不为 0 表示缓冲数组有推回的字节
int avail = buf.length - pos;
//缓冲区有数据,默认从缓冲区先读取
if (avail > 0) {
//判断要读取的字节数量是否小于缓冲区的字节数量
if (len < avail) {
avail = len;
}
//利用数组复制,将缓冲区的数据读入该数组
System.arraycopy(buf, pos, b, off, avail);
pos += avail;
off += avail;
len -= avail;
}
//如果要读取的字节数量超出缓冲数组的字节数量,继续从流读取剩余的字节
if (len > 0) {
len = super.read(b, off, len);
//提前到达 I/O 流末尾,则返回
if (len == -1) {
return avail == 0 ? -1 : avail;
}
//返回读取的字节数量 = 从缓冲区读取的字节数 + 从流读取的字节数
return avail + len;
}
return avail;
}
//确保要操作的流不为空(即没有关闭)
private void ensureOpen() throws IOException {
if (in == null) {
throw new IOException("Stream closed");
}
}unread 方法,即推回操作,这里定义了 3 种推回方式。
// ①推回一个字节
public void unread(int b) throws IOException {
ensureOpen();
//上面说过从数组末尾写入数据,为 0,表示缓冲区已满
if (pos == 0) {
throw new IOException("Push back buffer is full");
}
//往缓冲区添加字节,并减少索引位置
buf[--pos] = (byte) b;
}
// ②推回 byte 数组的某一部分
public void unread(byte[] b, int off, int len) throws IOException {
ensureOpen();
//判断要推回的字节数量大于剩余缓冲容量
if (len > pos) {
throw new IOException("Push back buffer is full");
}
//修改缓冲区的索引位置
pos -= len;
//通过数组复制方式,将数组中的字节 "推回" 到缓冲区
System.arraycopy(b, off, buf, pos, len);
}
// ③推回一个 byte 数组
public void unread(byte[] b) throws IOException {
unread(b, 0, b.length);
}skip 方法
public long skip(long n) throws IOException {
ensureOpen();
if (n <= 0) {
return 0;
}
long pskip = buf.length - pos;
//先判断缓冲区是否有字节数据可以跳过
if (pskip > 0) {
if (n < pskip) {
pskip = n;
}
pos += pskip;
n -= pskip;
}
//n 比换缓冲的字节数大的话,继续从流里面跳跃
if (n > 0) {
pskip += super.skip(n);
}
return pskip;
}剩余方法
public int available() throws IOException {
ensureOpen();
//还要加上推回缓冲区的字节
return (buf.length - pos) + super.available();
}
public boolean markSupported() {
return false;
}
public synchronized void mark(int readlimit) {
}
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
public synchronized void close() throws IOException {
if (in == null) {
return;
}
in.close();
in = null;
buf = null;
}2.PushbackReader
类结构图,观察结构图我们可以发现与 PushbackInputStream 的结构几乎一致。不同的是
将字节数组换乘字符数组
ready 方法对应 PushbackInputStream 的 available 方法
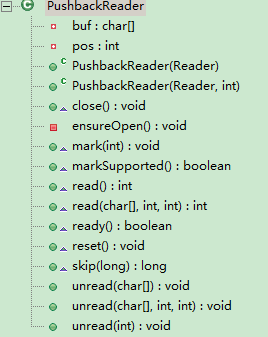
因为实现原理一致,这里不做探究。唯一有较大不同的是 read 和 unread该类中加了同步代码块,只允许单线程访问。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











