








原文请看摸我
这是有关注解代码生成技术系列博文的第二部分。在第一部分(摸我)中,我们介绍了注解的基本概念与用法。
在本篇博文中我们将介绍注解处理器的基本概念和使用运行方法。
介绍
注解功能强大。你可以使用注解来设置各类元数据或者配置信息,语法格式优雅并且功能强大。
从目前我们了解的知识来看,注解比起Javadoc来有很多优势,但是这些好像都不足以委员会将其加入java语言之中。那么,我们可以更好的利用和了解注解吗?当然可以啦:
- 在运行时刻,带有runtime retention policy的注解可以通过反射获得,Class类中的getAnnotation()和getAnnotations()方法可以做到这些。
- 在编译时刻,注解处理器可以处理在编译时发现的各类注解。
注解处理器API
当注解在Java 5 首次被引入时,注解处理器API还不是很成熟和规范化。处理注解需要一个单独的工具,叫做apt,注解处理工具;还需要Mirror API(com.sun.mirror),用于编写自定义处理器。
从java 6开始,注解处理通过JSR 269(2)被标准化,被集成进标准库并且apt无缝的集成到java编译器javac中。
因为我们只详细讲述Java 6 中的注解处理器相关API,你可以在这里和这里找到关于java 5中注解的更多信息,并在这里找到一些例子。
自定义注解处理器只是实现了javax.annotation.processing.Processor接口并准从指定的协议。为了我们的便利,自定义处理器一些常用的功能都由javax.annotation.processing.AbstractProcessor这个类给出了抽象实现。
自定义注解处理器可以使用到一下三个注解来配置自己:
- javax.annotation.processing.SupportedAnnotationTypes:这个注解用来注册注解处理器要处理的注解类型。有效值为完全限定名(就是带所在包名和路径的类全名)-通配符(此次英语原文为Wildcards,就是?这个符号代表的类型。比如说List<? extends String,想要深入了解,可以看一下这里)也可以。
- javax.annotation.processing.SupportedSourceVersion:这是用来注册注解处理器要处理的源代码版本。
- javax.annotation.processing.SupportedOptions:这个注解用来注册可能通过命令行传递给处理器的操作选项。
(译者语:对于android注解处理器,第一个注解比较有用,另外两个了解就可)
最后,我们提供process()方法的实现。
实现我们第一个注解处理器
让我们开始第一个注解处理器的实现。按照之前章节的知识,我们实现了下面这个类来处理第一篇博文中的Complexity注解:
package sdc.assets.annotations.processors;
import …
@SupportedAnnotationTypes("sdc.assets.annotations.Complexity")
@SupportedSourceVersion(SourceVersion.RELEASE_6)
public class ComplexityProcessor extends AbstractProcessor {
public ComplexityProcessor() {
super();
}
@Override
public boolean process(Set<? extends TypeElement> annotations,
RoundEnvironment roundEnv) {
return true;
}
} 这个未完全完成的类,尽管没有任何操作,但是注册可以支持处理sdc.assets.annotations.Complexity注解类型。因此,每次java编译器遇到一个被Complexity标记的类都有执行这个处理器,假设这个处理器在那个路径中可以被获得(具体原由之后会看到)。
process()方法会受到两个输入参数:
- Set
for (Element elem :roundEnv.getElementsAnnotatedWith(Complexity.class)) {
Complexity complexity = elem.getAnnotation(Complexity.class);
String message = "annotation found in " + elem.getSimpleName() + " with complexity " + complexity.value(); processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, message);
return true; // no further processing of this annotation type
}打包并且注册注解处理器
自定义注解处理器的最后一步就是打包并且向java编译器获取其他可以识别处理器的工具进行注册。
注册处理器的最简单方法就是使用标注java服务机制:
- 把你的注解处理器打包到jar文件中。
- 把jar文件加入到META-INF/services目录。
- 把javax.annotation.processing.Processor文件加入到目录。
把处理器的全限定名写入一个文件中,一个处理器名一行。
java编译器或者其他工具会搜索这个文件中标记的所有处理器,并且在注解处理过程中使用。
在我们这个例子中,目录结构和文件内容如下:
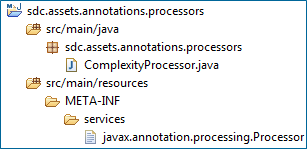

一旦打包完成,我们就准备使用它。
(译者语:关于android平台的自动打包和使用,可以参考butterknife的方法,就是使用AutoService,这个详细知识之后我会单独博文讲解)
使用javac运行处理器
想象一下你在一个项目中使用了一些自定义注解并且可以使用注解处理器。在java 5中,编译和注解处理是不同的两步,但是在java 6中,两个任务都集成到java编译器工具javac中。
如果你把注解处理器加入到javac的路径中并且他们使用服务机制进行了注册,他们就会被javac执行调用啦。
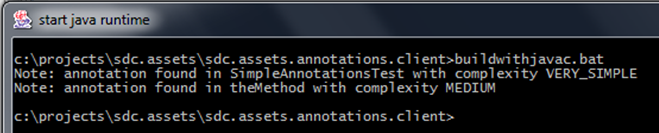
在我们这个例子中,下边这个命令会编译并且执行注解处理:
>javac -cp sdc.assets.annotations-1.0-SNAPSHOT.jar;
sdc.assets.annotations.processors-1.0-SNAPSHOT.jar
SimpleAnnotationsTest.java用于处理的java类文件内容如下:
package sdc.startupassets.annotations.base.client;
import ...
@Complexity(ComplexityLevel.VERY_SIMPLE)
public class SimpleAnnotationsTest {
public SimpleAnnotationsTest()
{
super();
}
@Complexity() // this annotation type applies also to methods // the default value 'ComplexityLevel.MEDIUM' is assumed
public void theMethod()
{
System.out.println("consoleut");
}
}上述执行结果如下:
有一些javac的选项可以在一些特殊的情况下使用:
- -Akey[=value]:用来传递选项值给处理器,处理器只会接收在通过SupportedOptions注解注册的选项。
- -proc:{none|only}:默认情况下,javac会运行注解处理并且编译源码。使用proc:none选项,将不执行注解处理;使用proc:only选项将只执行注解处理过程-当你在注解处理器中运行验证或者质量检查工具或者代码审查工具时。
- -processorpath path:用来确定注解处理器和它的依赖的位置
- -s dir:用来确定通过注解处理生成的源代码放置在哪个文件夹中。这个目录在执行命令行之前必须存在。
- -processor class1[,class2,class3…]:用来给出将要执行的注解处理器全限定名,当使用这个选项时,默认的通过服务机制寻找到的注解处理器将被替换,直接使用命令行给出的处理器进行处理。
(译者语:下边两个章节因为和主干内容没有太大关系,所以没有翻译,请感兴趣的朋友自行查阅)















 141
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









