






 本文详细介绍了如何使用SSD(Single Shot MultiBox Detector)模型进行目标检测任务的训练流程,包括准备训练数据、生成lmdb数据库、调整模型参数以适应不同分类数量等关键步骤。
本文详细介绍了如何使用SSD(Single Shot MultiBox Detector)模型进行目标检测任务的训练流程,包括准备训练数据、生成lmdb数据库、调整模型参数以适应不同分类数量等关键步骤。
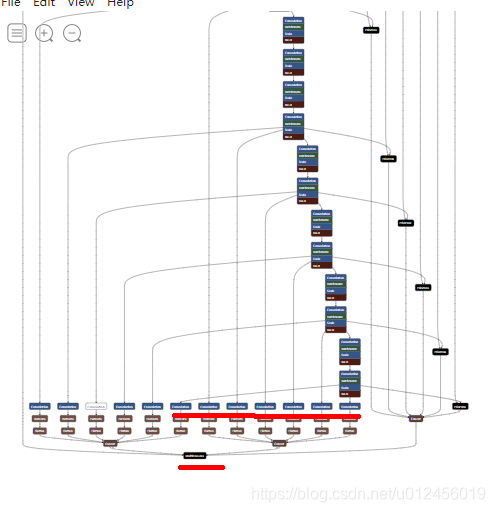
需要修改的地方是红线部分,根据分类数量进行修改,原版的开源是21个分类(包括background),所以是63(213),126(213*2),如果class_num为5,则为15,30
1、首先准备好自己的训练数据,包括,Annotations和JPEGImages,ImageSets通过如下python脚本和前面两个文件生成:
# _*_ coding:UTF-8 _*_
#开发作者 : ZhangRong
#开发时间 : 2020/4/21 10:18
#文件名称 : process.py
#开发工具 : PyCharm
#Description:
import os
import random
trainval_percent = 0.66
train_percent = 0.8
xmlfilepath = '/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit/MyDataSet/Annotations'
txtsavepath = '/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdeckit/MyDataSet/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit/MyDataSet/ImageSets/Main/trainval.txt', 'w')
ftest = open('/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit/MyDataSet/ImageSets/Main/test.txt', 'w')
ftrain = open('/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit/MyDataSet/ImageSets/Main/train.txt', 'w')
fval = open('/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit/MyDataSet/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
2、生成lmdb,如下两个脚本
create_list.sh
#!/usr/local/bin/bash
root_dir=/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit/ # 修改成自己的路径
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in MyDataSet # 也需要修改
do
if [[ $dataset == "test" && $name == "VOC2012" ]]
then
continue
fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name\/JPEGImages\//g" $img_file
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name\/Annotations\//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
$bash_dir/../../build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
fi
# Shuffle trainval file.
if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file | perl -MList::Util=shuffle -e 'print shuffle(<STDIN>);' > $rand_file
mv $rand_file $dst_file
fi
done
crea_data.sh
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir="/data/zhangrong/caffe/caffe-ssd/caffe"
cd $root_dir
redo=1
data_root_dir="/data/zhangrong/caffe/caffe-ssd/caffe/data/VOCdevkit"
dataset_name="MyDataSet"
mapfile="$root_dir/data/$dataset_name/labelmap_voc.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=300 #resize大小
height=300
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/$dataset_name/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
done
3、训练脚本
train.sh
#!/usr/local/bin/bash
if ! test -f MobileNetSSD_train.prototxt ;then
echo "error: train.prototxt does not exist."
exit 1
fi
echo $(ls -t snapshot/voc/*.caffemodel | head -n 1)
#set your caffe path, such as '/home/work/caffe_ssd/build/tools/caffe'
/data/zhangrong/caffe/caffe-ssd/caffe/build/tools/caffe train --solver="solver.prototxt" \
--weights=$(ls -t backup/*.caffemodel | head -n 1) \
--gpu 0 2>&1 | tee backup/MobileNetSSD_voc.log

















 429
429



 到【灌水乐园】发言
到【灌水乐园】发言







