






总体原则:高度可扩展,极致性能。
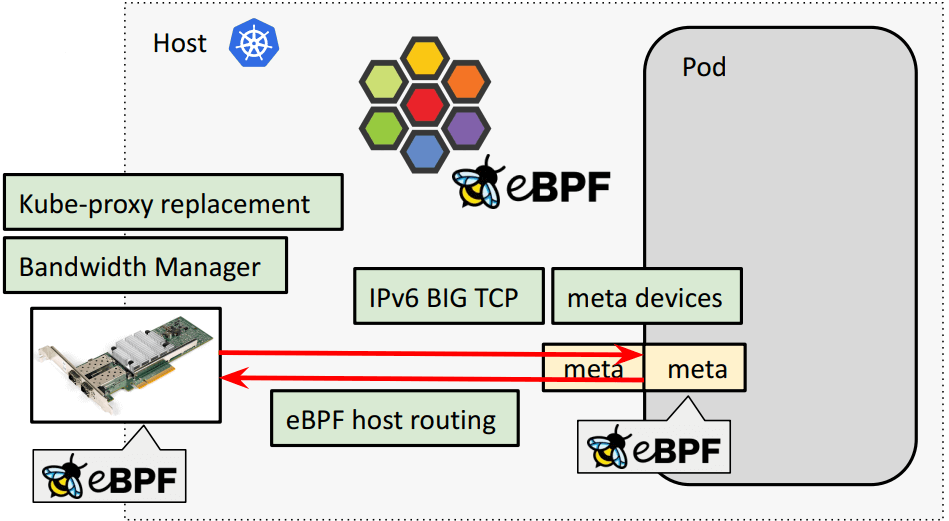
Cilium + BIG TCP
BIG TCP
设计目标
支持数据中心内的单个 socket 达到 100Gbps+ 带宽。
使用场景
大数据、AI、机器学习以及其他网络密集型应用。
BIG TCP 并不是一个适应于大部分场景的通用方案,而是针对数据密集型应用的优化,在这些场景下能显著提升网络性能。
技术原理
文档:
Going big with TCP packets, lwn.net, 2022来计算一下,如果以 MTU=1538 的配置,要达到 100Gbps 带宽,
100Gbit/s ÷ 1538Byte ÷ 8bit/Byte == 8.15Mpps (123ns/packet)可以看到,
每秒需要处理 815 万个包,或者说,
每个包的处理时间不能超过 123ns。对于内核协议栈这个庞然大物来说,这个性能是无法达到的,例如一次 cache miss 就会导致性能急剧下降。降低 pps 会使这个目标变得更容易,在总带宽不变的情况下,这就意味着要增大包长(packet length)。局域网里面使用超过 1.5K 的 MTU 大包已经是常规操作,经过适当的配置之后,可以用到最大 64KB/packet。后面会看到这个限制是怎么来的。
大包就需要批处理:GRO、TSO。如下图所示:
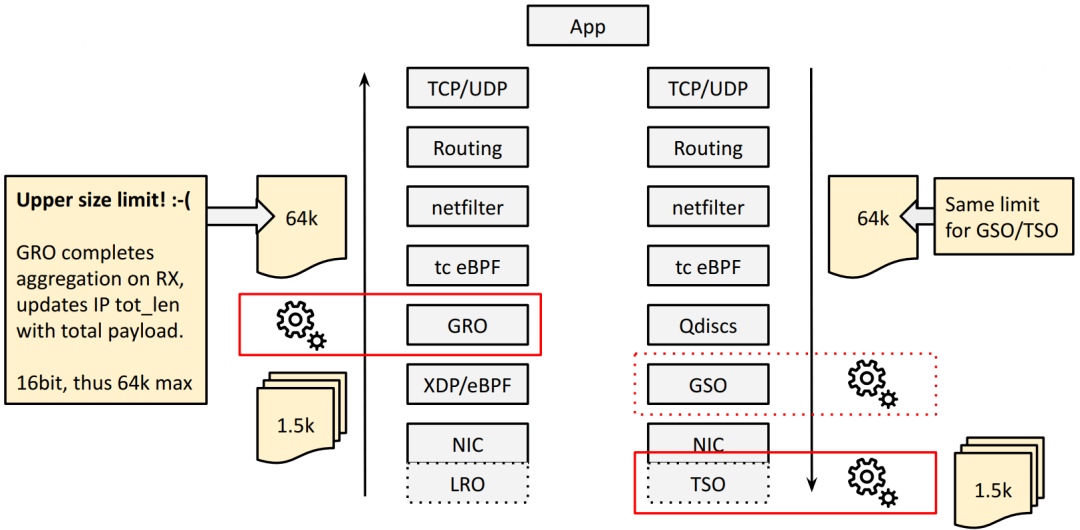
TSO 将超大的 TCP 包在 NIC/HW 上分段(segment),
GRO 在接收方向对分段的包进行重组,重新得到超大 TCP 包。
IPv4 限制:单个包最大 64KB 以 RX 方向的 GRO 为例,GRO 会将重组之后的 total payload 长度更新到 IPv4 头的 tot_len 字段,这是一个 16bit 整数,单位是字节,因此最大只能表示 64KB 的包。
TX 方向的 TSO 也有一样的限制。也就是说,使用 IPv4,我们在 TX/RX 方向最大只能支持 64KB 的大包。
内核能支持更大的 batch 吗?能,使用 IPv6。
解决方式:IPv6 HBH (Hop-By-Hop),单个包最大 4GB BIG TCP 的解决方式是在本地插入一个 Hop-By-Hop (HBH) IPv6 扩展头。“本地”的意思是“在这台 node 上”,也就是说 HBH 头不会发出去,只在本机内使用。
此外,还需要对应调整 MTU 大小。
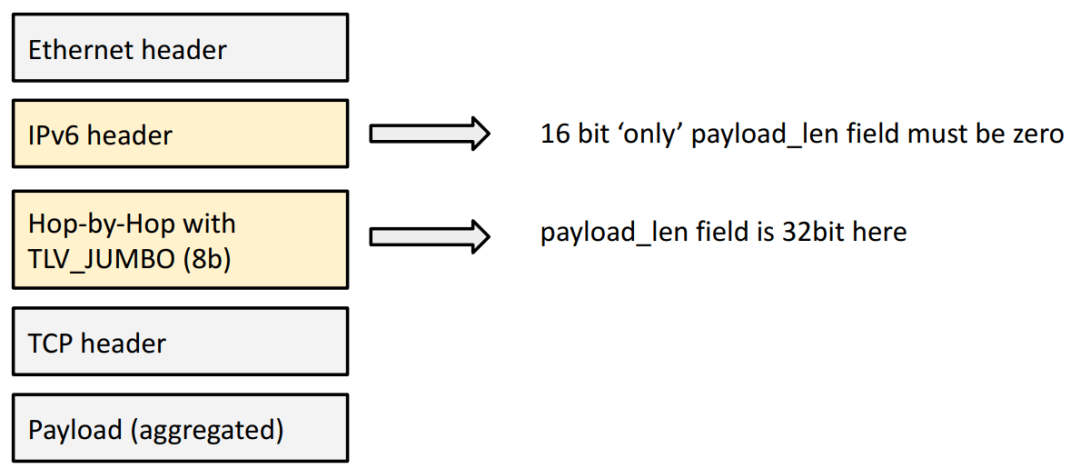
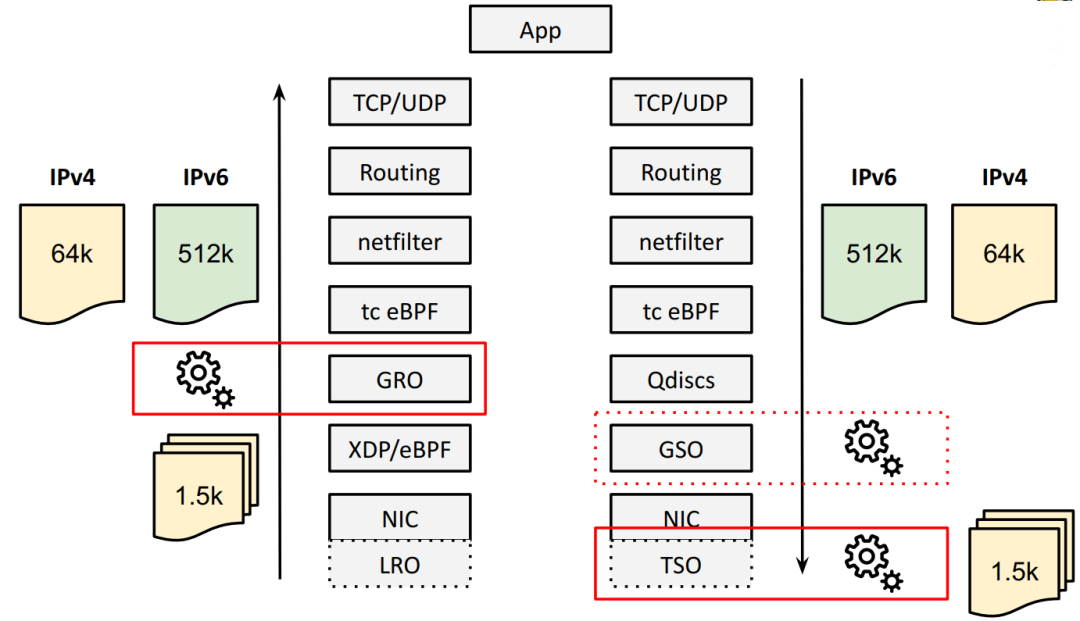
目前这个上限是 512KB,但是未来需要时,很容易扩展。这个字段是 32bit,因此理论上最大能支持 4GB 的超大包(jumbo packets)。
内核支持(5.19+)
BIG TCP 合并到了内核 5.19+,
内核 patch:tcp: BIG TCP implementation, from Google, 2022 此外,它还需要网卡驱动的支持。
Cilium 支持(v1.13+)
BIG TCP 的支持将出现在 Cilium 1.13。
文档:Performance: tuning: IPv6 BIG TCP
Kernel: 5.19+
Supported NICs: mlx4, mlx5
实现:Add IPv6 BIG TCP support启用了开关之后,Cilium 将自动为 host/pod devices 设置 IPv6 BIG TCP,过程透明。
性能
延迟:
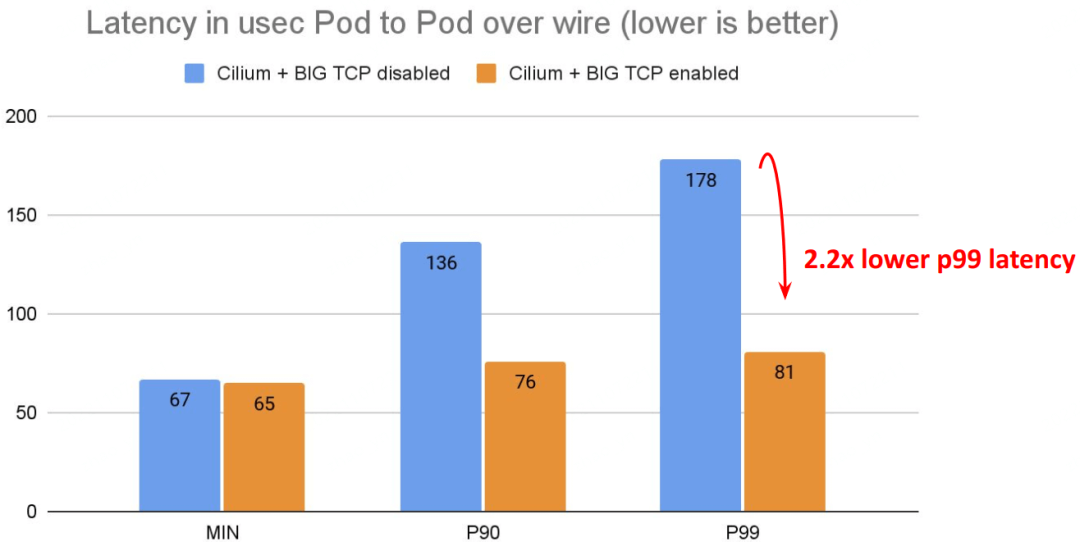
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver 78
$ netperf -t TCP_RR -H <remote pod> -- -r 80000,80000 -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUTTPS:
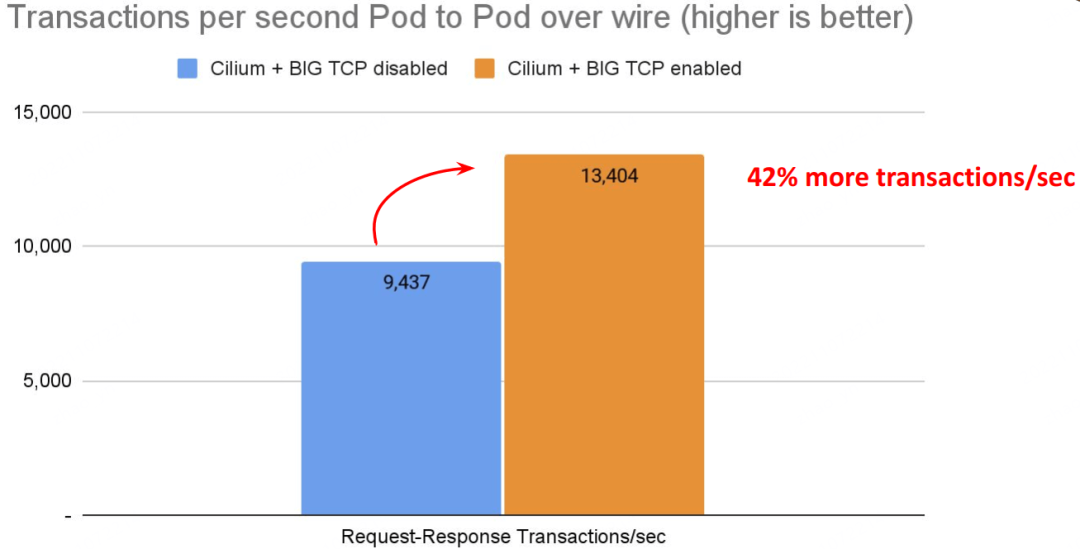
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver 79
$ netperf -t TCP_RR -H <remote pod> -- -r 80000,80000 -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT带宽:
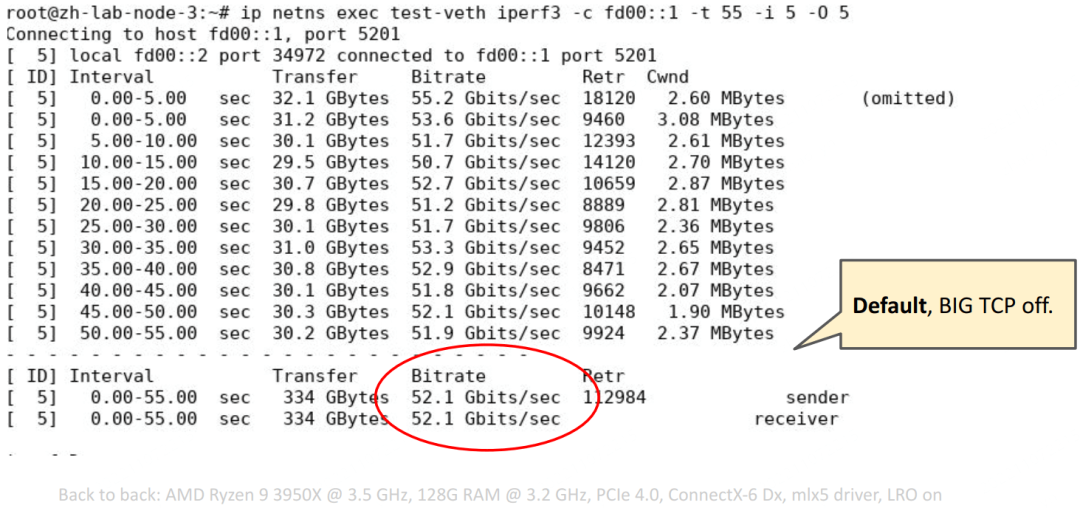
iperf3 不支持 mmap()’ed TCP. 在这里的测试中,最大的开销就是 copy from/to userspace,因此最大速度卡在了 60Gbps,

Cilium 作为独立网关节点(standalone GW)
提供的能力:
基于 eBPF/XDP 的 L4LB,可通过 API 编程控制转发规则;
支持 weighted Maglev 一致性哈希
支持 DSR:支持 IPIP/IP6IP6 等 DSR 封装格式,支持 backend RSS fanout
Backend 优雅终止和退出(Termination/Quarantining),可手动通过 CLI/API 操作
Stateful NAT46/64 Gateway
Stateless NAT46/64 Gateway
支持 IPv6-only K8s
Cilium 作为 k8s 网络方案
eBPF kube-proxy replacement,支持 XDP / socket-level-LB
eBPF host routing:物理网卡通过 BPF 直通 pod 虚拟网卡(veth pair),低延迟转发
带宽管理基础设施:Cilium:基于 BPF+EDT+FQ+BBR 更好地带宽网络管理(KubeCon, 2022)[译] 流量控制(TC)五十年:从基于缓冲队列(Queue)到基于时间戳(EDT)的演进
EDT rate-limiting via eBPF and MQ/FQ
Pacing and BBR support for Pods
Disabling TCP slow start after idle
IPv6 BIG TCP support
eBPF meta driver for Pods as veth device replacement:下面单独介绍。
meta device vs. veth pair
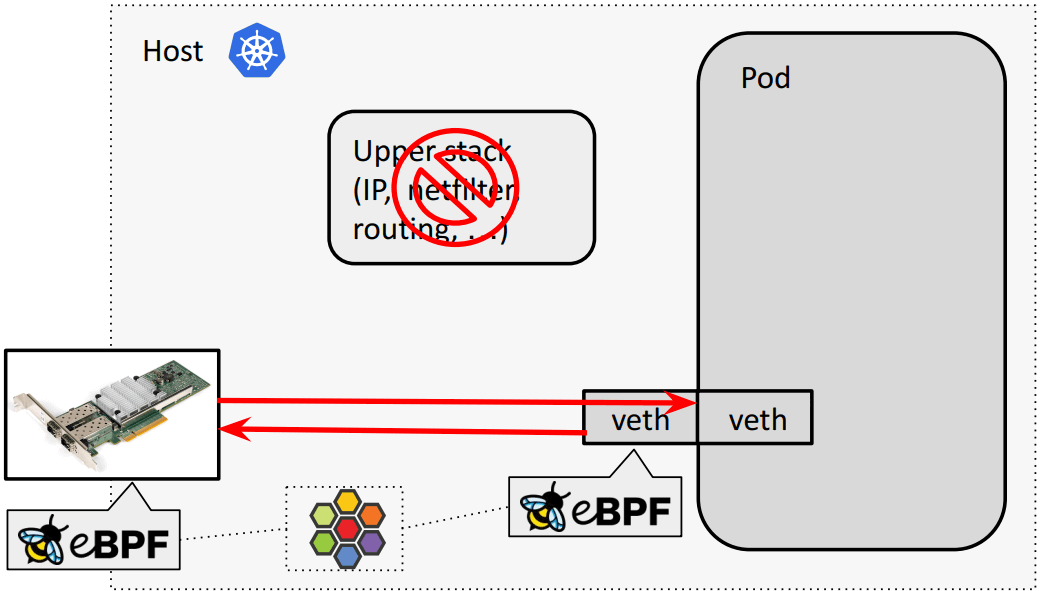
veth pair default/bpf-host-routing 模式转发路径 常规(默认):物理网卡和容器虚拟网卡之间要经过内核网络栈,
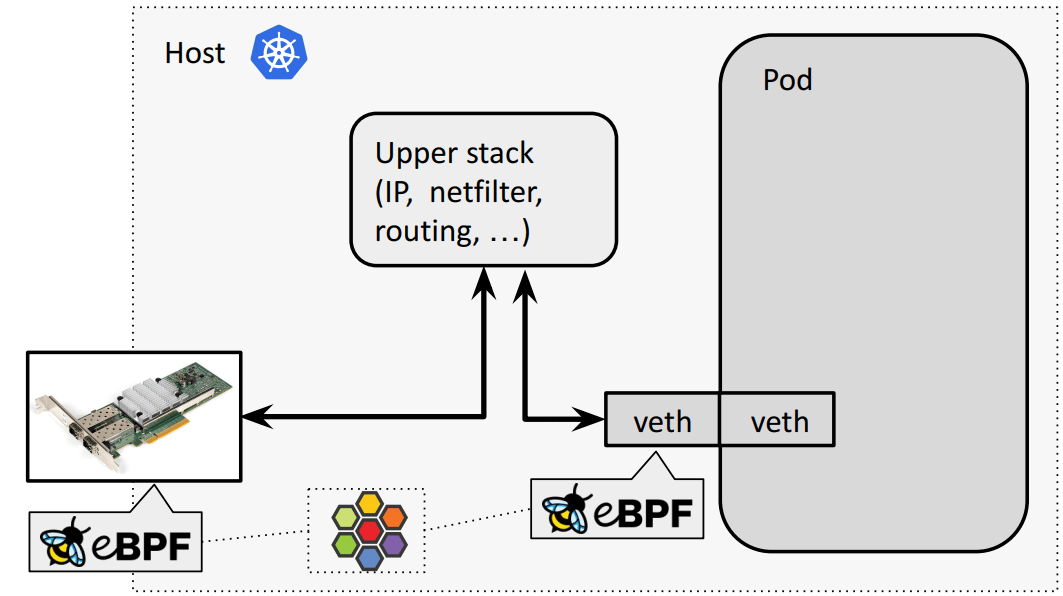
eBPF host routing:物理网卡通过 bpf_redirect_{peer,neigh} 直通 veth pair:
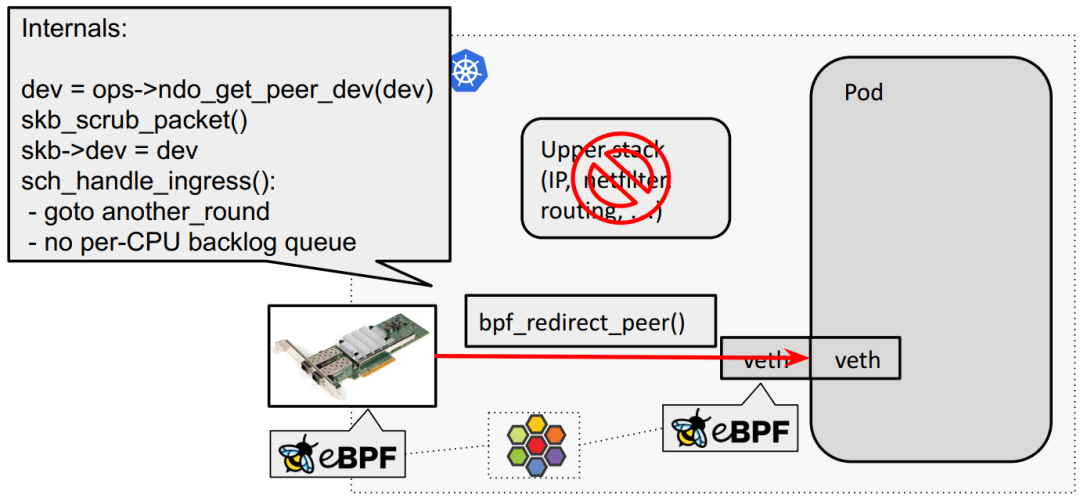
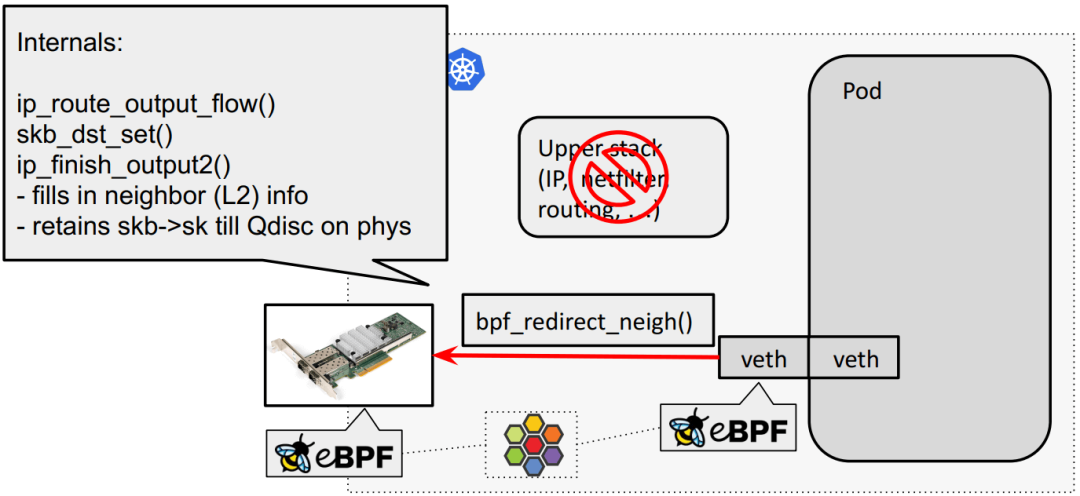
meta device 转发路径
以上 eBPF host routing 双向转发效果:
现在我们正在开发一个称为 meta device 的虚拟设备,替换 veth pair:
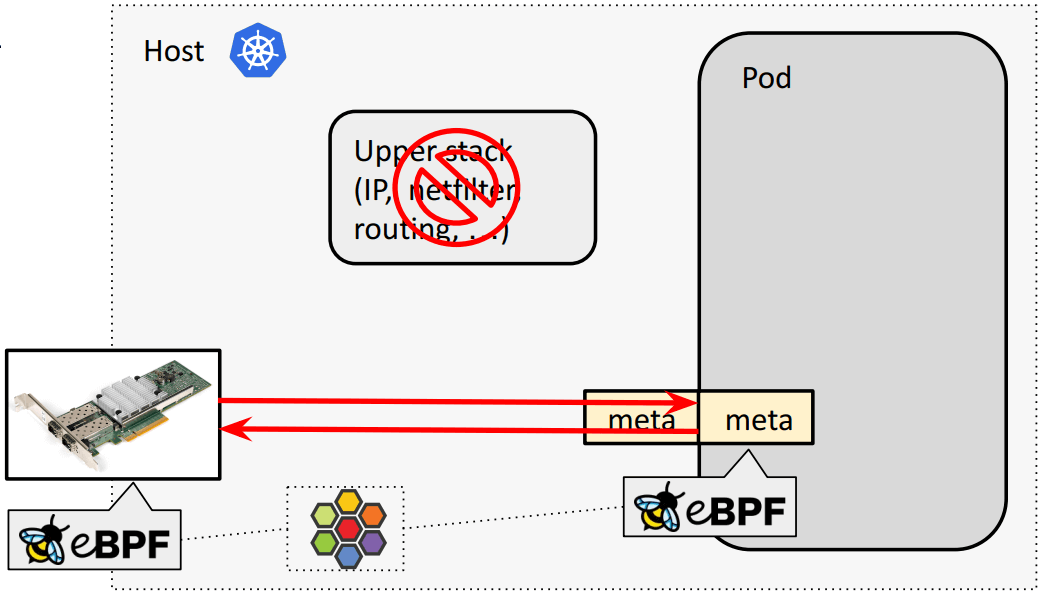
为什么引入 meta:将 pod-specific BPF 程序从 tc bpf 移动到 meta layer。对于 meta device 来说,eBPF 程序成为了 pod 内的 device 自身的一部分。但不会由 pod 来修改或 unload eBPF 程序,而仍然由宿主机 namespace 内的 cilium 来统一管理。
meta device 好处:延迟更低
延迟更低,pod 的网络延迟已经接近 host network 应用的延迟。
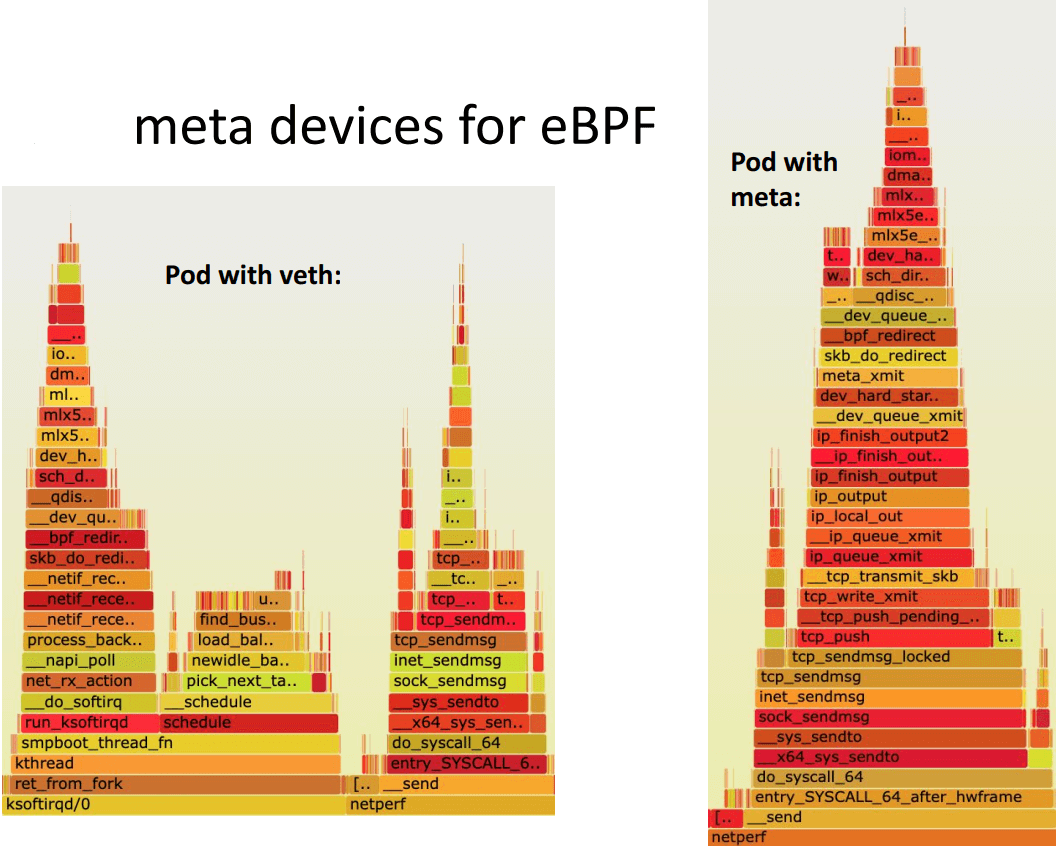
4.3.4 meta device vs. veth pair:实现区别 Internals for veth (today):
veth_xmit()
scrubs packet meta data
enques to per-CPU backlog queue
net_rx_action picks up packets from queue in host
deferral can happen to ksoftirqd
Cilium’s eBPF prog called only on tc ingress to redirect to phys dev
Internals for meta (new):
meta_xmit()
scrubs packet meta data
switches netns to host
Cilium’s eBPF prog called for meta
Redirect to phys dev directly without backlog queue 代码:
https://github.com/cilium/linux/commits/pr/dev-metameta device 性能
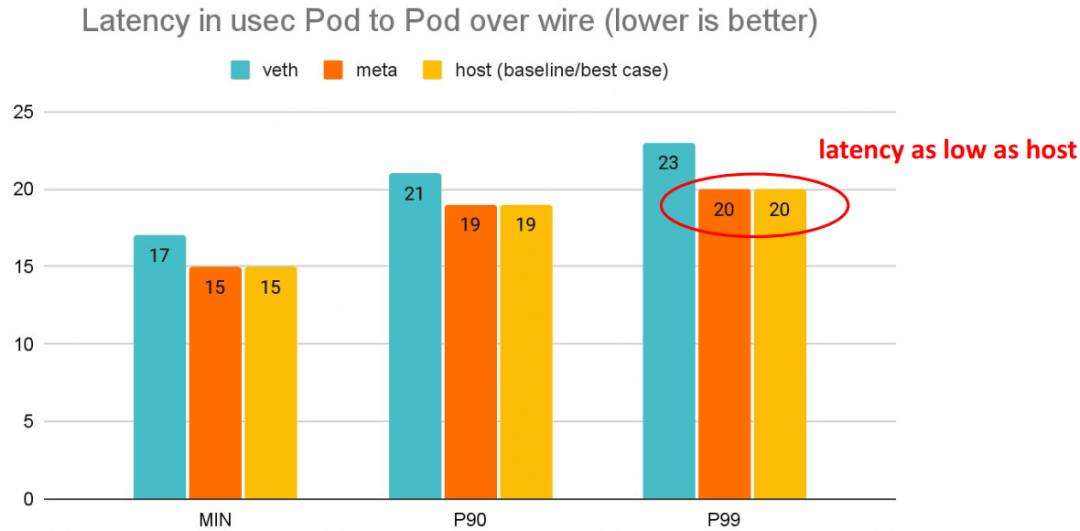
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver
$ netperf -t TCP_RR -H <remote pod> -- -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT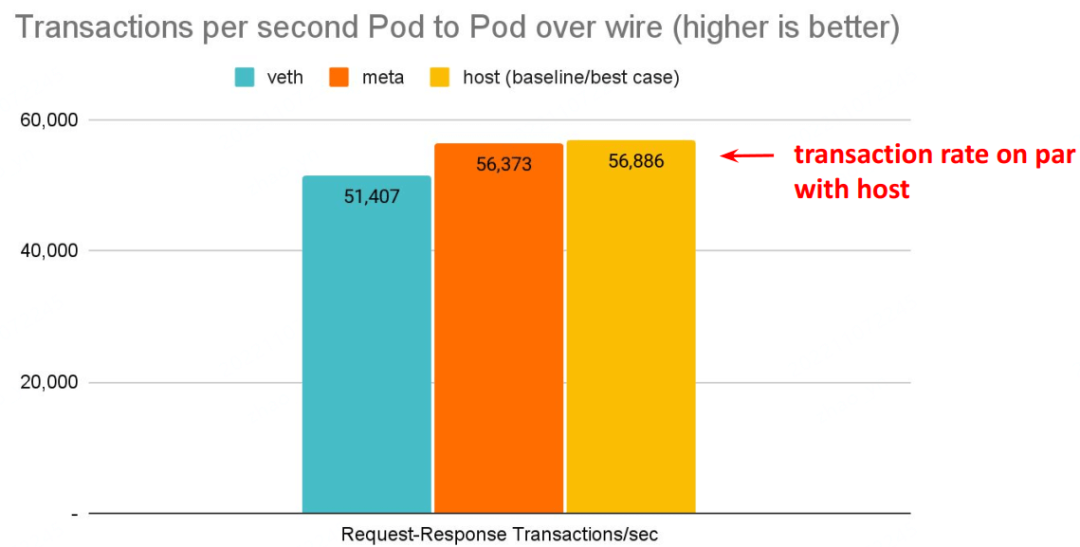
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver
$ netperf -t TCP_RR -H <remote pod> -- -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT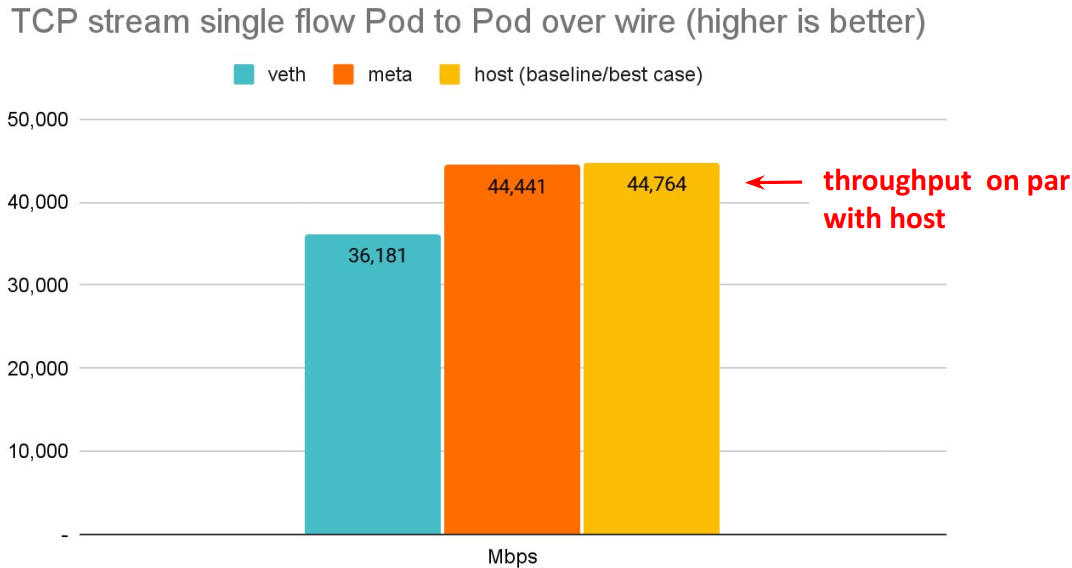
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver
$ netperf -t TCP_STREAM -H <remote pod> -l 60推荐
随手关注或者”在看“,诚挚感谢!















 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









