










本文是我的匹配模型合集的其中一期,如果你想了解更多的匹配模型,欢迎参阅我的另一篇博文匹配模型合集
所有的模型均采用tensorflow进行了实现,欢迎start,[代码地址]https://github.com/terrifyzhao/text_matching
简介
ESIM模型主要是用来做文本推理的,给定一个前提premise p p p 推导出假设hypothesis h h h,其损失函数的目标是判断 p p p与 h h h是否有关联,即是否可以由 p p p推导出 h h h,因此,该模型也可以做文本匹配,只是损失函数的目标是两个序列是否是同义句。接下来我们就从模型的结构开始讲解其原理。
结构
ESIM的论文中,作者提出了两种结构,如下图所示,左边是自然语言理解模型ESIM,右边是基于语法树结构的HIM,我的代码实现主要以ESIM为主,本文也主要讲解ESIM的结构,大家如果对HIM感兴趣的话可以阅读原论文。
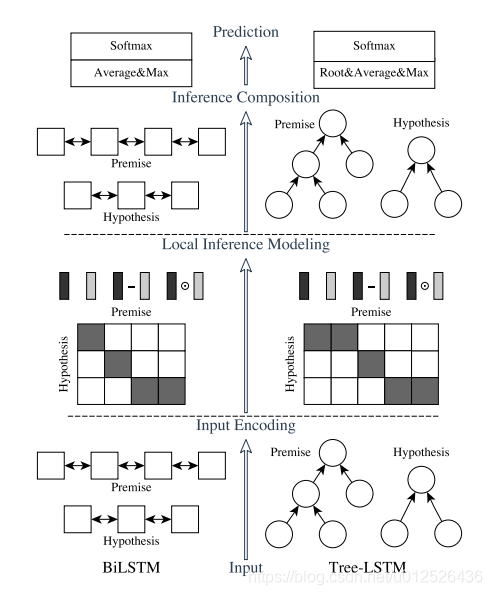
ESIM一共包含四部分,Input Encoding、Local Inference Modeling、 Inference Composition、Prediction,接下来会分别对这四部分进行讲解。
Input Encoding
我们先看一下这一层结构的输入内容,输入一般可以采用预训练好的词向量或者添加embedding层,在我的代码中采用的是embedding层。接下来就是一个双向的LSTM,起作用主要在于对输入值做encoding,也可以理解为在做特征提取,最后把其隐藏状态的值保留下来,分别记为 a i ˉ \bar{a_i} aiˉ与 b j ˉ \bar{b_j} bjˉ,其中i与j分别表示的是不同的时刻,a与b表示的是上文提到的p与h。
a i ˉ = B i L S T M ( a , i ) , i ∈ [ 1 , . . . , l a ] \bar{a_i} = BiLSTM(a,i),i\in[1,...,l_a] aiˉ=BiLSTM(a,i),i∈[1,...,la]
b j ˉ = B i L S T M ( b , j ) , j ∈ [ 1 , . . . , l b ] \bar{b_j} = BiLSTM(b,j),j\in[1,...,l_b] bjˉ=BiLSTM(b,j),j∈[1,...,lb]
Local Inference Modeling
这一层的任务主要是把上一轮拿到的特征值做差异性计算。这里作者采用了attention机制,其中attention weight的计算方法如下:
e i j = a i ˉ T b j ˉ e_{ij} = \bar{a_i}^T\bar{b_j} eij=aiˉTbjˉ
然后根据attention weight计算出a与b的权重加权后的值,计算方法如下:
a i ~ = ∑ j = 1 l b e x p ( e i j ) ∑ k = 1 l b e x p ( e i k ) b j ˉ , i ∈ [ 1 , . . . , l a ] \tilde{a_i} = \sum_{j=1}^{l_b} \frac{exp(e_{ij})}{\sum_{k=1}^{l_b} exp(e_{ik})}\bar{b_j},i \in [1,...,l_a] ai~=j=1∑lb∑k=1lbexp(eik)exp(eij)bjˉ,i∈[1,...,la]
b j ~ = ∑ i = 1 l a e x p ( e i j ) ∑ k = 1 l a e x p ( e k j ) a i ˉ , j ∈ [ 1 , . . . , l b ] \tilde{b_j} = \sum_{i=1}^{l_a} \frac{exp(e_{ij})}{\sum_{k=1}^{l_a} exp(e_{kj})}\bar{a_i},j \in [1,...,l_b] bj~=i=1∑la∑k=1laexp(ekj)exp(eij)aiˉ,j∈[1,...,lb]
注意,这里计算 a i ~ \tilde{a_i} ai~的时候,其计算方法是与 b j ˉ \bar{b_j} bjˉ做加权,而不是 a i ˉ \bar{a_i} aiˉ本身, b j ~ \tilde{b_j} bj~同理。
得到encoding值与加权encoding值之后,下一步是分别对这两个值做差异性计算,作者认为这样的操作有助于模型效果的提升,论文有有两种计算方法,分别是对位相减与对位相乘,最后把encoding两个状态的值与相减、相乘的值拼接起来。
m a = [ a ˉ ; a ~ ; a ˉ − a ~ ; a ˉ ⊙ a ~ ] m_a = [\bar{a};\tilde{a};\bar{a}-\tilde{a};\bar{a}\odot\tilde{a}] ma=[aˉ;a~;aˉ−a~;aˉ⊙a~]
m b = [ b ˉ ; b ~ ; b ˉ − b ~ ; b ˉ ⊙ b ~ ] m_b = [\bar{b};\tilde{b};\bar{b}-\tilde{b};\bar{b}\odot\tilde{b}] mb=[bˉ;b~;bˉ−b~;bˉ⊙b~]
Inference Composition
在这一层中,把之前的值再一次送到了BiLSTM中,这里的BiLSTM的作用和之前的并不一样,这里主要是用于捕获局部推理信息 m a m_a ma和 m b m_b mb及其上下文,以便进行推理组合。
最后把BiLSTM得到的值进行池化操作,分别是最大池化与平均池化,并把池化之后的值再一次的拼接起来。
V a , a v e = ∑ i = 1 l a V a , i l a , V a , m a x = m a x i = 1 l a V a , i V_{a,ave} = \sum_{i=1}^{l_a} \frac{V_a,i}{l_a},V_{a,max}=max_{i=1}^{l_a}V_{a,i} Va,ave=i=1∑lalaVa,i,Va,max=maxi=1laVa,i
V b , a v e = ∑ j = 1 l b V b , j l b , V b , m a x = m a x j = 1 l b V b , j V_{b,ave} = \sum_{j=1}^{l_b} \frac{V_b,j}{l_b},V_{b,max}=max_{j=1}^{l_b}V_{b,j} Vb,ave=j=1∑lblbVb,j,Vb,max=maxj=1lbVb,j
V = [ V a , a v e ; V a , m a x ; V b , a v e ; V b , m a x ] V = [V_{a,ave};V_{a,max};V_{b,ave};V_{b,max}] V=[Va,ave;Va,max;Vb,ave;Vb,max]
Prediction
最后把 V V V送入到全连接层,激活函数采用的是 t a n h tanh tanh,得到的结果送到softmax层。
小结
ESIM与BiMPM在相似度匹配任务中都是使用较多的模型,但是ESIM训练速度快,效果也并没有逊色太多,如果加入了语法树,其最终效果也能进一步的提升。














 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









