






目录
1.基础入门
准备好动手体验 Kibana 了吗? 本教程将会引导您体验如下内容:
在开始之前,请确保您已安装 Kibana 并已成功连接至 Elasticsearch 。
1.1.加载示例数据
本节内容依赖以下数据:
- 威廉·莎士比亚全集,解析成合适的字段。点击这里下载这个数据集: shakespeare.json.
- 一组虚构的账户与随机生成的数据。点击这里下载这个数据集: accounts.zip.
- 一组随机生成的日志文件。点击这里下载这个数据集: logs.jsonl.gz.
其中有两个数据集是压缩文件,可使用以下命令解压缩文件:
unzip accounts.zip
gunzip logs.jsonl.gz莎士比亚数据集的组织方式如下:
{
"line_id": INT,
"play_name": "String",
"speech_number": INT,
"line_number": "String",
"speaker": "String",
"text_entry": "String",
}帐户数据集的组织方式如下:
{
"account_number": INT,
"balance": INT,
"firstname": "String",
"lastname": "String",
"age": INT,
"gender": "M or F",
"address": "String",
"employer": "String",
"email": "String",
"city": "String",
"state": "String"
}日志数据集的结构有许多不同的字段,以下是其中比较重要的字段:
{
"memory": INT,
"geo.coordinates": "geo_point"
"@timestamp": "date"
}在莎士比亚和日志数据集加载之前,我们需要为字段设置 映射。 映射把索引中的文档按逻辑分组并指定了字段的属性,比如字段的可搜索性或者该字段是否是 tokenized ,或分解成单独的单词。
使用以下命令在终端(如 bash )建立一个莎士比亚数据集的映射:
PUT /shakespeare
{
"mappings": {
"doc": {
"properties": {
"speaker": {"type": "keyword"},
"play_name": {"type": "keyword"},
"line_id": {"type": "integer"},
"speech_number": {"type": "integer"}
}
}
}
}这个映射指定了数据集的以下特点:
- 因为 speaker 和 play_name 字段是关键字字段,它们不需要分析。字符串即使包含多个词也仍被视为一个整体。
- line_id 和 speech_number 字段是整数。
日志数据集映射需要利用 geo_point 类型来标记经度/纬度地理位置字段。
使用下面的命令来为日志建立 geo_point 映射:
PUT /logstash-2015.05.18
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}PUT /logstash-2015.05.19
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}PUT /logstash-2015.05.20
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}账户数据集不需要任何映射,基于这一点我们准备用 Elasticsearch bulk API 来加载数据集,命令如下:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/doc/_bulk?pretty' --data-binary @shakespeare_6.0.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl执行这些命令可能需要一段时间,取决于可用的计算资源。
使用下面的命令来验证加载是否成功:
GET /_cat/indices?v您应该会看到类似下面的输出:
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open bank 5 1 1000 0 418.2kb 418.2kb
yellow open shakespeare 5 1 111396 0 17.6mb 17.6mb
yellow open logstash-2015.05.18 5 1 4631 0 15.6mb 15.6mb
yellow open logstash-2015.05.19 5 1 4624 0 15.7mb 15.7mb
yellow open logstash-2015.05.20 5 1 4750 0 16.4mb 16.4mb1.2.定义自己的索引模式
加载到 Elasticsearch 的每组数据都有一个索引模式(Index Pattern)。 在上一节中,为莎士比亚数据集创建了名为 shakespeare 的索引,为 accounts 数据集创建了名为 bank 的索引。一个 索引模式 是可以匹配多个索引的带可选通配符的字符串。例如一般在通用日志记录中,一个典型的索引名称一般包含类似 YYYY.MM.DD 格式的日期信息。例如一个包含五月数据的索引模式: logstash-2015.05* 。
在本手册中,我们加载的索引只要名称匹配都可以正常工作。打开浏览器,访问 localhost:5601 。单击 Management 选项,然后单击 Index Patterns 选项。点击 Add New 定义一个新的索引模式。共有两个样本数据集,莎士比亚戏剧和金融账户,不包含时间序列数据。当您为这些数据集创建索引模式时,请确保 Index contains time-based events 没有被选中。指定 shakes* 作为 Shakespeare 数据集的索引模式,然后点击 Create 创建索引模式,然后同样的方法再创建一个名为 ba* 的索引模式
Logstash 数据集会包含时间序列数据,所以点击 Add New 来定义这个数据集的索引,确保 Index contains time-based events 被选中,并从 Time-field name 下拉列表中选择 @timestamp 字段。
定义索引模式时,匹配该模式的索引必须在 Elasticsearch 中存在。并且那些索引必须包含数据。1.3.探索您的数据
单击侧面导航中的 Discover 进入 Kibana 的数据探索功能:

在查询框里,您可以输入 Elasticsearch 查询语句 来搜索您的数据。您可以在 Discover 页面下查看搜索结果并在 Visualize 页面下生成已保存搜索的可视化效果。
当前索引模式显示在查询栏下面。索引模式决定了当您提交查询时搜索哪些索引。要搜索一组不同的索引,可以从下拉菜单中选择不同的模式。要添加索引模式,请到 Management/Kibana/Index Patterns界面下点击 Add New 。
您可以把您感兴趣的字段名称和值当做搜索的条件,对于数字字段您可以使用比较运算符,例如大于(>)、小于(<)或等于(=)。您可以使用逻辑运算符 AND,OR 和 NOT 连接搜索条件,这些运算符需要全部大写。
尝试选择 ba* 索引模式并在查询栏中输入以下字符串:
account_number:<100 AND balance:>47500此查询返回0到99之间所有余额超过47,500的账户号码。搜索银行样本数据时,它返回5个结果:帐户号码8,32,78,85和97。

每个匹配的文档默认显示所有字段。可以将鼠标悬停在可用字段上并点击您想要展示字段旁边的 add 按钮来添加需要展示的字段。例如,如果您仅仅添加 account_number ,就只会显示5个简单的账户号码的列表:

1.4.可视化数据
在侧边导航栏点击 Visualize 开始视化您的数据。
Visualize 工具能让您通过多种方式浏览您的数据。例如:我们使用饼图这个重要的可视化控件来查看银行账户样本数据中的账户余额。点击屏幕中间的 Create a visualization 蓝色按钮开始。
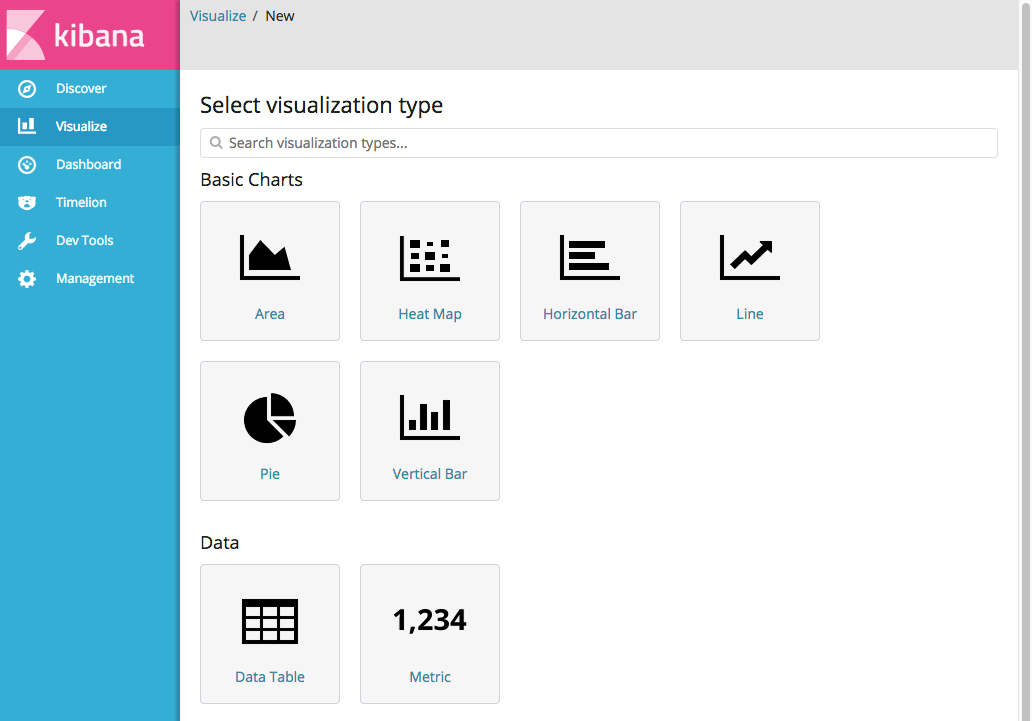
有很多种可视化控件可供选择。我们点击其中一个名为 Pie 的。
您可以为已保存的搜索建立可视化效果,或者输入新的搜索条件。使用后者时,首先需要选择一个索引模式来指定搜索哪些索引。我们希望搜索账户数据,所以选择 ba* 这个索引模式。

默认搜索匹配所有的文档。初始饼图没有分区:

您可以使用 Elasticsearch 桶聚合 指定图表中显示哪些信息。桶聚合简单的把符合您搜索条件的文档分成不同类别,又叫做 buckets 。例如:包含每个账户的余额数据。通过使用桶聚合,您可以建立多个账户余额区间并找到每个区间内包含多少账户。
定义每个区间桶:
- 点击 Split Slices 桶类别。
- 从 Aggregation 列表中选择 Range 。
- 从 Field 列表中选择 balance 字段。
- 点击四次 Add Range 把区间总数增加到6个。
-
定义以下区间:
0 999 1000 2999 3000 6999 7000 14999 15000 30999 31000 50000 - 点击 Apply changes
 更新图表。
更新图表。
现在您可以看到1000个账户根据余额区间划分的比例情况。

让我们看以下数据的另一方面:账户拥有者的年龄。通过添加另一个桶聚合,您可以看到每个余额区间的账户拥有者的年龄:
- 点击桶列表中的 Add sub-buckets 。
- 点击桶类型列表中的 Split Slices 。
- 在聚合列表中选择 Terms 。
- 在字段列表中选择 age 。
- 点击 Apply changes 。
现在您可以看到根据账户持有者的年龄划分的环形结构显示在余额区间外侧。

点击 Save 然后输入名称 Pie Example 来保存这个图表供以后使用。
下一步,我们来看一下莎士比亚数据集中的数据。让我们找出每部剧中的台词数,然后通过柱状图来显示这些数据:
- 点击 New 然后选择 Vertical bar chart 。
- 选择
shakes*索引模式。因为目前并没有定义任何桶,您将会看到唯一的一个柱形,它代表着匹配默认通配请求的所有文档数。

- 为了在y轴上显示每部剧里面的台词数,您需要通过 指标聚合 配置y轴。指标聚合以搜索结果中提取出来的值为基础计算出相应的指标。为了得到每部剧中的台词数,选择 Unique Count 聚合然后从字段列表中选择 speaker 。您也可以给这个轴加上标签,例如 Speaking Parts 。
- 为了在x轴上显示不同的剧目,选择X轴桶种类,然后在聚合列表中选择 Terms ,并从字段列表中选择 play_name 。选择 Ascending 使得剧目名称按照字母顺序排列。您也可以给这个轴加上标签,例如 Play Name 。
- 点击 Apply changes 来显示结果。

注意每部剧名显示为整个短语,而不是以单词的形式分开。是因为我们在教程开始的时候做了映射的缘故,把 play_name 字段标记为 not analyzed 。
鼠标悬停在每个柱形图上可以以提示信息的形式显示每部剧中的台词数。为了关闭提示信息并配置其它选项,选择可视化编辑器的 Options 选项。
现在,您已经拥有一个莎士比亚戏剧的最小演员表,您也许会想通过显示某部剧里面的最大台词数来了解哪部剧对一个演员要求最高。
- 点击 Add metrics 来添加一个Y轴聚合。
- 选择 Max 聚合然后选择 speech_number 字段。
- 选择 Options 然后把 Bar Mode 改为 grouped 。
- 点击 Apply changes 。您的图表应该如下所示:

如您所见,与其他剧目相比 Love’s Labours Lost 有着最高的台词数,因此也最考验演员的记忆力。
请注意 Number of speaking parts Y轴从0开始,但是柱形从18才开始有差别。为了让这种差别更明显,我们让Y轴从最接近最小值的数据开始,打开选项然后选择 Scale Y-Axis to data bounds 。
保存这个图表并命名为 Bar Example 。
下一步,我们使用地图来可视化日志样本数据集中的地理标识信息。
- 点击 New 。
- 选择 Coordinate map 。
- 选择
logstash-*索引模式。 - 设置我们要查看的事件的时间窗口:
- 在 Kibana 工具栏中点击时间控件选择。
- 点击 Absolute 。
-
设置开始时间为 May 18, 2015,结束时间为 May 20, 2015。

- 设置好时间范围后,点击 Go 按键并点击右下角向上的小箭头关闭时间控件。
因为目前没有定义任何桶,您将只会看到一幅世界地图:

选择 Geo Coordinates 作为桶,并点击 Apply changes 来显示日志文件中对应的地理坐标。您的图表应该如下所示:

您可以通过点击和拖动来浏览地图,通过  按钮放大缩小,或者点击 Fit Data Bounds
按钮放大缩小,或者点击 Fit Data Bounds  缩放到最低水平来显示所有部位。您也可以通过点击 Latitude/Longitude Filter
缩放到最低水平来显示所有部位。您也可以通过点击 Latitude/Longitude Filter  并在地图上画框来包含或去除某个矩形区域。已被应用的过滤器显示在查询栏下方。鼠标悬停在过滤器上方可以显示切换、固定、反转和删除该过滤器的控制选项。
并在地图上画框来包含或去除某个矩形区域。已被应用的过滤器显示在查询栏下方。鼠标悬停在过滤器上方可以显示切换、固定、反转和删除该过滤器的控制选项。

保存这个地图并命名为 Map Example 。
最后,创建一个 Markdown 控件来显示其他信息:
- 点击 New 。
- 选择 Markdown widget 。
-
在输入框中输入如下内容:
# This is a tutorial dashboard!
The Markdown widget uses **markdown** syntax.
> Blockquotes in Markdown use the > character.- 点击 Apply changes 在预览框中显示该 Markdown 。


1.5.使用仪表板汇总数据
仪表板可用于集中管理和分享可视化控件集合。构建一个仪表板用以包含您在本教程中已保存的可视化控件,方法如下
- 在侧边导航栏点击 Dashboard 。
- 点击 Add 显示已保存的可视化控件列表。
- 单击 Markdown Example 、 Pie Example 、 Bar Example 和 Map Example ,然后通过点击列表底部向上的小箭头关闭可视化控件列表。
将鼠标悬停在一个可视化控件上可以显示允许您编辑、移动、删除和调整它的控制器。
您的样本仪表板最终看起来应该大概像这样:

要获取分享链接或将仪表板嵌入到网页中的 HTML 代码,请保存仪表板并点击 Share 。
1.6.总结
现在您已经掌握了基本技能,可以开始使用 Kibana 探索您自己的数据了。
- 点击 Discover 查看更多关于搜索和过滤数据的信息。
- 点击 Visualize 查看所有 Kibana 提供的可视化控件种类。
- 点击 Management 查看如何配置 Kibana 和管理已保存的对象。
- 点击 Console 查看如何使用交互控制台向 Elasticsearch 提交 REST 请求。















 2705
2705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









