









一、 场景描述
实时监控文件目录,将目录中的实时产生的数据文件(文件内容非动态)写入动态分区,分区为3级(设备ID/文件产生日期/文件产生的时间(h)).文件名格式如下(日期+时间+产品ID.txt)
二、 主要存在的难点
由于flume只支持传入一些简单的参数变量(时间/日期/文件名等),所以这里我们如果想动态的识别我们的文件名并直接生成sink的路径及相应文件名有困难。
三、 解决方法
这里我们依然选用hdfs sink来作数据消费,但要稍微改变一部分源码,来达到我们通过识别文件名来确定输出路径的目的,步骤如下:
(1) 下载apache-flume-1.7.0-src源码 (官网直接下载)
(2) 打开cmd编译源码(这里用的mvn版本号为3.3.9,最好用3.3版本以上的版本,我自己用3.2出啦点问题)
编译小提示:
maven确实是一个好东西,但是在国内下载官方仓库的jar却是个大问题,速度不敢恭维,现在oschina的国内maven镜像服务已关闭,无奈之下只能另寻门路。
今天突然发现了阿里云maven国内镜像,修改完以后速度飞一般的感觉。
修改方法:在~/.m2目录下的settings.xml文件中,(如果该文件不存在,则需要从maven/conf目录下拷贝一份),找到<mirrors>标签,添加如下子标签:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
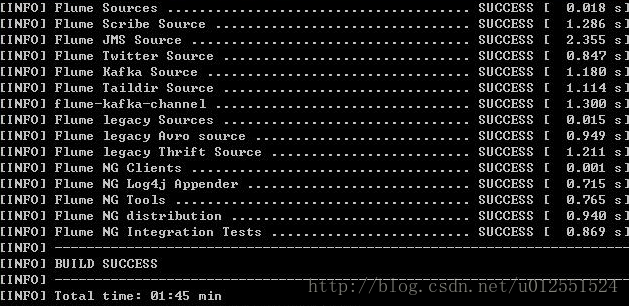
编译成功后如下:
(3) 把项目导入eclipse做修改
下图为修改后代码并且在环境上执行通过并写入后的代码,主要修改flume-hdfs-sink下的HDFSEentSink.java文件,主要修改process()方法,我们通过识别文件名来拼出hdfs的文件路径来达到动态识别文件名并创建动态hdfs路径的目的:
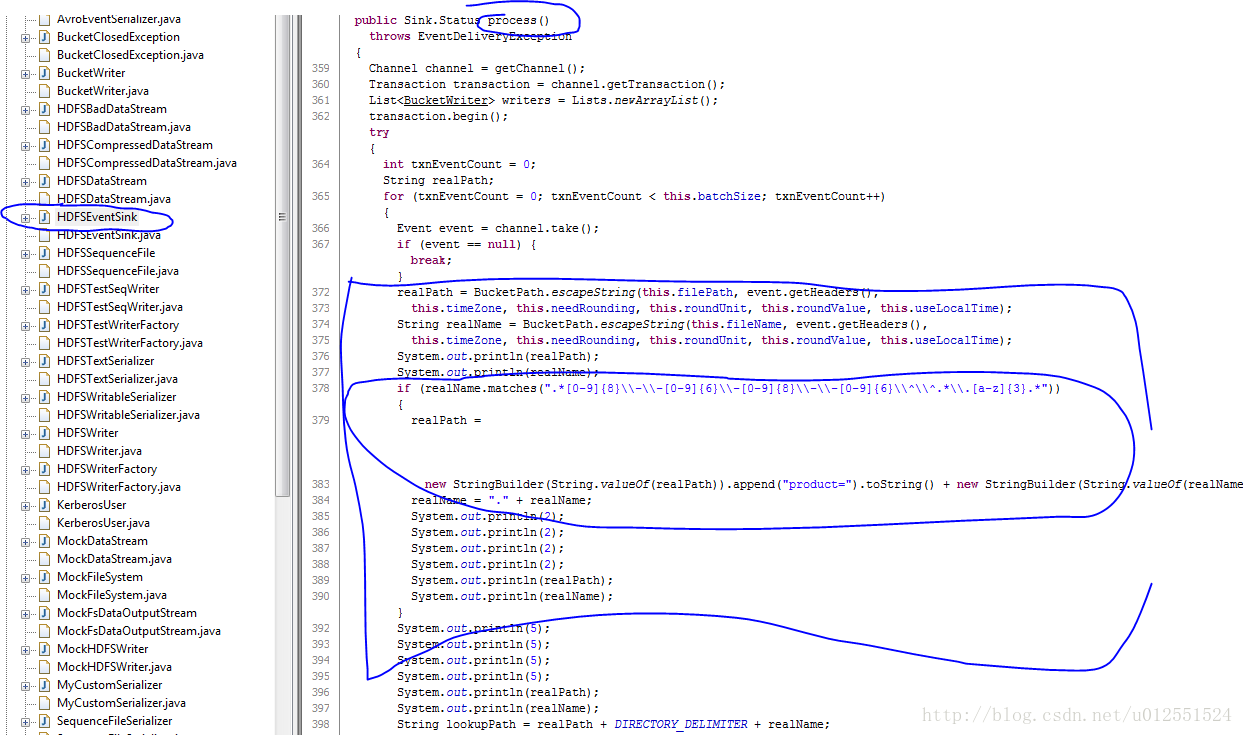
修改之后直接重新将子项目flume-hdfs-sink打包为flume-hdfs-sink-1.7.0.jar,最后直接去环境下替换掉原来的jar包(路径如下,记得将原来的jar包做备份):

到这里我们对flume的一些小改动基本结束。
四、 测试
(1)创建flume配置文件,简单的flume配置文件如下:
#agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#Spooling Directory是监控指定文件夹中新文件的变化,一旦新文件出现,就解析该文件内容,然后写入到channle。写入完成后,标记该文件已完成或者删除该文件。
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tracy/flume_test
agent1.sources.source1.basenameHeader=true
agent1.sources.source1.basenameHeaderKey=fileName
agent1.sources.source1.deletePolicy=immediate
#batchSize是针对Source和Sink提出的一个概念,它用来限制source和sink对event批量处理的
agent1.sources.source1.batchSize=1000
#channel存event的最大数量
a1.channels.c1.capacity = 1000
#每次从source到channel或从channel到sink的event最大的吞吐量
a1.channels.c1.transactionCapacity = 100
#channle满载的情况下30s后抛出异常
agent1.channels.ch1.keep-alive = 30
agent1.sources.source1.request-timeout=2000
agent1.sources.source1.connect-timeout=3000
agent1.sources.source1.channels=channel1
#加拦截器
#agent1.sources.source1.interceptors = i1
#时间戳拦截器
#agent1.sources.source1.interceptors.i1.type = timestamp
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/tracy/flume_test1
agent1.channels.channel1.dataDirs=/tracy/flume_test2
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoop.nameNode1:9000/user/hive/warehouse/test.db/info_flume_data_dt1/
#DataStream类似于textfile
agent1.sinks.sink1.hdfs.fileType=DataStream
#只写入event的body部分
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.batchSize = 1
agent1.sinks.sink1.hdfs.rollInterval = 1
agent1.sinks.sink1.hdfs.rollcount = 1
agent1.sinks.sink1.hdfs.rollsize = 0
agent1.sinks.sink1.hdfs.inUsePrefix=t
agent1.sinks.sink1.hdfs.inUseSuffix=.temp
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%{fileName}
(2)事先在Hive建最终要落地的分区表如下:
DROP TABLE IF EXISTS INFO_FLUME_DATA_DT1;
CREATE TABLE IF NOT EXISTS INFO_FLUME_DATA_DT1(
t_date string comment '时间',
detail string comment '参数'
) PARTITIONED BY (product string,l_date date,houra string)
--clustered by (t_date) sorted by(detail) into 4 buckets
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
(4) 启动我们的单节点flume进行测试:
./flume-ng agent -n agent1 -c ../conf -f ../conf/flume-conf-hdfs.properties -Dflume.root.logger=DEBUG,console
(5) 往flume监控的目录放入文件:
Flume控制台输出如下:
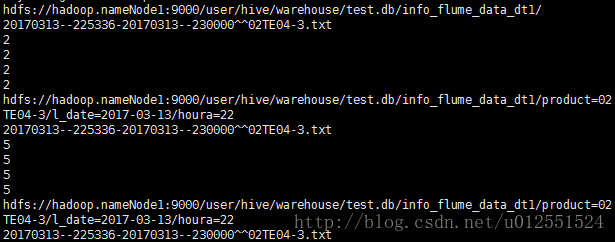
这里可以看到我们代码中打桩的位置,路径文件名没什么问题,再去hdfs路径下看下文件是否写入:
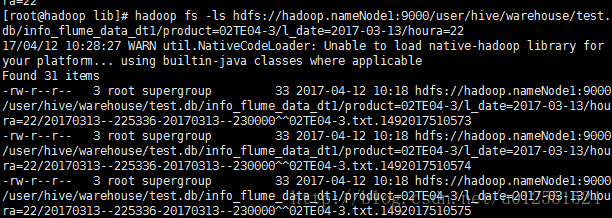
没问题
(6) 查看hive表数据情况:
这里我们要注意,要想我们在hdfs的数据在hive表可见,我们首先要alter一下分区:
ALTER TABLE INFO_FLUME_DATA_DT1
ADD PARTITION (product='02TE04-3',l_date='2017-03-13',houra='22');
最后去hive表看数据:
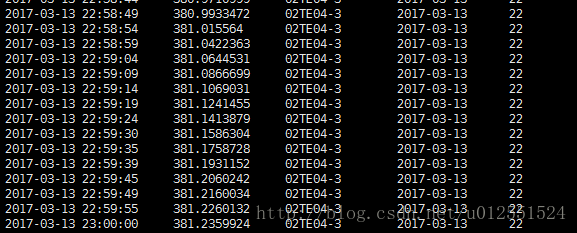
没问题。
实际情境下我们不可能每天手动去添加分区,每天跑个脚本把分区添加好就ok,如下(举例):
# !/bin/sh
for((i=0;i<24;i++))
do
beeline -u jdbc:hive2:// --verbose=true -e "ALTER TABLE test.INFO_FLUME_DATA_DT1 ADD PARTITION (product='02TE04-4',l_date='`date +"%Y-%m-%d"`',houra='$i')"
echo $i
done














 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









