









这个系列的目的是通过对OpenCV示例,进一步了解OpenCV函数的使用,不涉及具体原理。
目录
简介
Example运行截图
Example分析
Example代码
简介
本文记录了对OpenCV示例
kmeans
.cpp
的分析。
这个示例主要演示了如何使用
kmeans
对图像位置进行聚类。
示例涉及到
kmeans函数使用。
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
|
kmeans
函数原型:
CV_EXPORTS_W double kmeans( InputArray data, int K, InputOutputArray bestLabels,
TermCriteria criteria, int attempts,
int flags, OutputArray centers = noArray() );
参数说明:
data:
用于聚类的数据,是N维的数组类型(Mat型),必须浮点型;
K:
表示需要聚类的类别数;
bestLabels:
聚类后的标签数组,Mat型;
criteria:
迭代收敛准则(MAX_ITER最大迭代次数,EPS最高精度);
attempts:
表示尝试的次数,防止陷入局部最优;
flags:
表示聚类中心的选取方式(KMEANS_RANDOM_CENTERS 随机选取,KMEANS_P
P_CENTERS使用Arthur提供的算法,KMEANS_USE_INITIAL_LABELS使用初始标签
);
centers :
表示聚类后的类别中心。
注意,聚类指对data的值进行聚类,而非位置!如果需要对位置进行聚类,可以考虑将x,y坐标存入CV_32FC2的Mat
|
Example运行截图
| 鼠标点击次数 | 效果截图 |
|
1
|
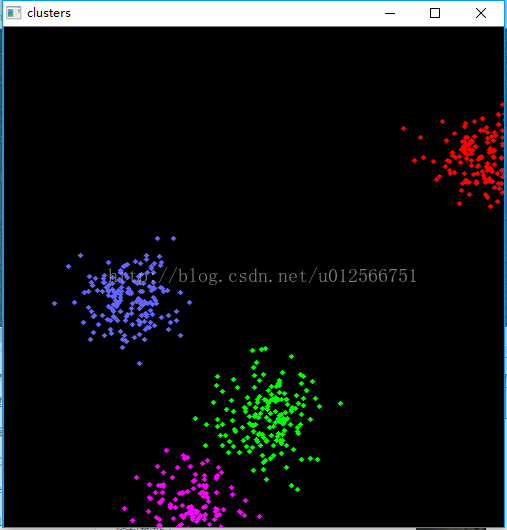
|
| 2 |
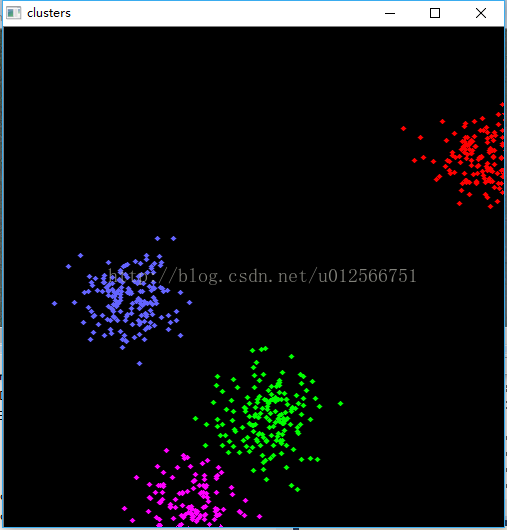
|
但是其实质是将随机位置存入一个N行2列(2列当然是x,y坐标
)的矩阵中,完成聚类后,再根据结果在原图中绘制。
Example分析
1.声明类簇的最大数量
const int MAX_CLUSTERS = 5;
2.声明绘制类
簇中点的颜色,用于区分不同的类簇
Scalar colorTab[] =
{
Scalar(0, 0, 255),
Scalar(0,255,0),
Scalar(255,100,100),
Scalar(255,0,255),
Scalar(0,255,255)
};
3.创建预览图
Mat img(500, 500, CV_8UC3);
4.声明随机数类
RNG rng(12345);
注意:
(1)
OpenCV中RNG类。它可以压缩一个64位的i整数并可以得到scalar和array的随机数。
目前的版本支持均匀分布随机数和Gaussian分布随机数。随机数的产生采用的是Multiply-With-Carry算法和Ziggurat算法。
其构造函数的初始化可以传入一个64位的整型参数作为随机数产生器的初值。
next可以取出下一个随机数,
uniform函数可以返回指定范围的随机数,
gaussian函数返回一个高斯随机数,
fill函数用随机数填充矩阵。
(2)
OpenCV中
还有一些随机数相关的函数,
比如randu可以产生一个均匀分布的随机数或者矩阵,
randn可以产生一个正态分布的随机数,
randShuffle可以随机打乱矩阵元素
5.使用循环反复观察K-means结果
for(;;)
{
...
char key = (char)waitKey();
if( key == 27 || key == 'q' || key == 'Q' ) // 'ESC'
break;
}
注意:
(1)这样的方式常用于批量样本测试,或使用随机量反复观察
6.具体分析for循环中代码
6.1通过随机数获取类簇的数量(数量在2到5之间)
int k, clusterCount = rng.uniform(2, MAX_CLUSTERS+1);
注意:
(1)cv::
RNG 的uniform取随机值区间为[a
,b),前闭后开,因此类似此处取2至5应该使用参数[2,6)
6.2通过随机数获取样本数量(数量在1到1000之间)
int i, sampleCount = rng.uniform(1, 1001);
6.3创建测试聚类样本矩阵,行数为样本数量,列数为1
Mat points(sampleCount, 1, CV_32FC2), labels;
注意:
(1)聚类算法是对Mat的值进行聚类,因此使用行/列矩阵就可以,很多初学者以为是对图像的位置进行聚类,那是错的。
如果希望对图像的位置进行聚类,只能将其位置信息作为值重新装入一个Mat,再进行聚类。
(2)因为是将位置存入Mat进行聚类,包含x,y信息,所以此处当然选用
CV_32FC2
。
6.4根据样本数量和预设类簇数量进行检测,如果样本数量小于类簇数量,则修改类簇数量
clusterCount = MIN(clusterCount, sampleCount);
6.5中心点(为了确保采用K-Means算法能够找到预期的聚类,因此随机点是根据中心值波动的)
Mat centers;
6.6根据类簇数量绘制随机样本(如前文提到为了确保采用K-Means算法能够找到预期的聚类,因此随机点是根据中心值波动的,并且有多少预设类簇就有多少中心点)
/* generate random sample from multigaussian distribution */
for( k = 0; k < clusterCount; k++ )
{
Point center;
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
Mat pointChunk = points.rowRange(k*sampleCount/clusterCount,
k == clusterCount - 1 ? sampleCount :
(k+1)*sampleCount/clusterCount);
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));
}
此处流程:
(1)遍历每一个类簇,k
(2)在图像中随机选取一个中心点center,其坐标随机
(3)根据当前类簇对测试样本获取其制定区域(行)pointChunk ,算法为
a.将这个样本平均分为clusterCount分区,起始值为第k个分区起始位置;
b.判断 k 为最后一个分区(总之为了取得平均分区的区域)
b.1.如果是,末尾位置为最后一行;
b.2.如果不是,末尾位置为当前分区的终止位置。
(4)对pointChunk 进行随机填充(根据中心值波动,并且波动值很小)
注意:
(1)Mat::
rowRange,
取example中特定范围的行列构成矩阵
(2)RNG::fill,对Mat的值进行范围内随机填充(随机是指值随机,而不是位置随机,Mat中的每一个元素都会有一个随机值)
6.7随机打乱矩阵元素
randShuffle(points, 1, &rng);
6.8调用kmeans
kmeans(points, clusterCount, labels,
TermCriteria( TermCriteria::EPS+TermCriteria::COUNT, 10, 1.0),
3, KMEANS_PP_CENTERS, centers);
6.9预览图背景为黑色
img = Scalar::all(0);
6.10根据points中存储位置,和labels中存储的分类,对结果采用不同颜色进行绘制区分
for( i = 0; i < sampleCount; i++ )
{
int clusterIdx = labels.at<int>(i);
Point ipt = points.at<Point2f>(i);
circle( img, ipt, 2, colorTab[clusterIdx], FILLED, LINE_AA );
}
6.11显示预览图
imshow("clusters", img);
Example代码
#include "opencv2/highgui.hpp"
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace cv;
using namespace std;
// static void help()
// {
// cout << "\nThis program demonstrates kmeans clustering.\n"
// "It generates an image with random points, then assigns a random number of cluster\n"
// "centers and uses kmeans to move those cluster centers to their representitive location\n"
// "Call\n"
// "./kmeans\n" << endl;
// }
int main( int /*argc*/, char** /*argv*/ )
{
const int MAX_CLUSTERS = 5;
Scalar colorTab[] =
{
Scalar(0, 0, 255),
Scalar(0,255,0),
Scalar(255,100,100),
Scalar(255,0,255),
Scalar(0,255,255)
};
Mat img(500, 500, CV_8UC3);
RNG rng(12345);
for(;;)
{
int k, clusterCount = rng.uniform(2, MAX_CLUSTERS+1);
int i, sampleCount = rng.uniform(1, 1001);
Mat points(sampleCount, 1, CV_32FC2), labels;
clusterCount = MIN(clusterCount, sampleCount);
Mat centers;
/* generate random sample from multigaussian distribution */
for( k = 0; k < clusterCount; k++ )
{
Point center;
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
Mat pointChunk = points.rowRange(k*sampleCount/clusterCount,
k == clusterCount - 1 ? sampleCount :
(k+1)*sampleCount/clusterCount);
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));
}
randShuffle(points, 1, &rng);
kmeans(points, clusterCount, labels,
TermCriteria( TermCriteria::EPS+TermCriteria::COUNT, 10, 1.0),
3, KMEANS_PP_CENTERS, centers);
img = Scalar::all(0);
for( i = 0; i < sampleCount; i++ )
{
int clusterIdx = labels.at<int>(i);
Point ipt = points.at<Point2f>(i);
circle( img, ipt, 2, colorTab[clusterIdx], FILLED, LINE_AA );
}
imshow("clusters", img);
char key = (char)waitKey();
if( key == 27 || key == 'q' || key == 'Q' ) // 'ESC'
break;
}
return 0;
}
参考资料:














 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









