







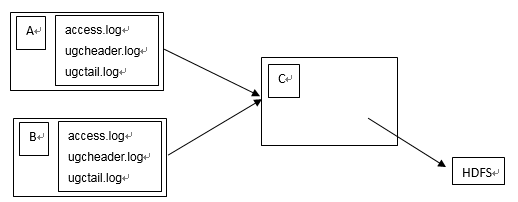
1、业务背景:
A、B两台机器上实时生产日志文件:access.log、ugcheader.log、ugctail.log
现在要求:
把A、B 机器中的 access.log、ugcheader.log、ugctail.log 汇总到C机器上统一收集到hdfs中。
但是在hdfs中要求的目录为:
/source/access/20160101/**
/source/ugcheader/20160101/**
/source/ugctail/20160101/**
2、过程
3、机器
A:hadoop1
B:hadoop2
C:hadoop3
4、首先安装hadoop 集群
http://blog.csdn.net/u012689336/article/details/52857921
5、安装flume
本文使用的是:apache-flume-1.5.0-bin.tar.gz
解压
[sparkadmin@hadoop1 ~]$ tar -zxvf apache-flume-1.5.0-bin.tar.gz
进行外关联
[sparkadmin@hadoop1 ~]$ ln -s apache-flume-1.5.0-bin flume
[sparkadmin@hadoop1 ~]$ cd flume/conf/
[sparkadmin@hadoop1 conf]$ mv flume-env.sh.template flume-env.sh
[sparkadmin@hadoop1 conf]$ vim flume-env.sh
JAVA_HOME=/usr/java/jdk1.7.0_79
6、编写配置文件
A机器:配置文件名称为a.conf:
[sparkadmin@hadoop1 conf]$ vim a.conf
#agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /cloud/data/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
#静态的添加一个key为type value为access的键值对到header里
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r1.channels = c1
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /cloud/data/ugchead.log
a1.sources.r2.interceptors = i1
a1.sources.r2.interceptors.i1.type = static
a1.sources.r2.interceptors.i1.key = type
a1.sources.r2.interceptors.i1.value = ugchead
a1.sources.r2.channels = c1
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /cloud/data/ugctail.log
a1.sources.r3.interceptors = i1
a1.sources.r3.interceptors.i1.type = static
a1.sources.r3.interceptors.i1.key = type
a1.sources.r3.interceptors.i1.value = ugctail
a1.sources.r3.channels = c1
#sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop3
a1.sinks.k1.port = 44444
a1.sinks.k1.channel = c1
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 10000
B机器:配置文件名称为b.conf:
[sparkadmin@hadoop2 conf]$ vim b.conf
#agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /cloud/data/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
#静态的添加一个key为type value为access的键值对到header里
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r1.channels = c1
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /cloud/data/ugchead.log
a1.sources.r2.interceptors = i1
a1.sources.r2.interceptors.i1.type = static
a1.sources.r2.interceptors.i1.key = type
a1.sources.r2.interceptors.i1.value = ugchead
a1.sources.r2.channels = c1
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /cloud/data/ugctail.log
a1.sources.r3.interceptors = i1
a1.sources.r3.interceptors.i1.type = static
a1.sources.r3.interceptors.i1.key = type
a1.sources.r3.interceptors.i1.value = ugctail
a1.sources.r3.channels = c1
#sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop3
a1.sinks.k1.port = 44444
a1.sinks.k1.channel = c1
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 10000
C机器:配置文件名称 c.conf
[sparkadmin@hadoop3 conf]$ vim c.conf
#agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop3
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
# source r1定义拦截器,为消息添加时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop1:8020/source/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
#a1.sinks.k1.hdfs.fileType = CompressedStream
#a1.sinks.k1.hdfs.codeC = gzip
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
#如果压缩存储的话HDFS上的文件达到64M时生成一个文件注意是压缩前大小为64生成一个文件,然后压缩存储。
a1.sinks.k1.hdfs.rollSize = 67108864
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.channel = c1
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
启动hadoop3上启动flume
[sparkadmin@hadoop3 flume]$ bin/flume-ng agent --conf conf/ --conf-file conf/c.conf --name a1 -Dflume.root.logger=INFO,console &
[1] 29875
然后启动hadoop1、hadoop2上面的flume
[sparkadmin@hadoop1 flume]$ bin/flume-ng agent --conf conf/ --conf-file conf/b.conf --name a1 &
[sparkadmin@hadoop2 flume]$ bin/flume-ng agent --conf conf/ --conf-file conf/b.conf --name a1 &
验证:
[sparkadmin@hadoop3 ~]$ hadoop fs -ls /source
Found 3 items
drwxr-xr-x - sparkadmin supergroup 0 2016-10-19 14:16 /source/access
drwxr-xr-x - sparkadmin supergroup 0 2016-10-19 14:16 /source/ugchead
drwxr-xr-x - sparkadmin supergroup 0 2016-10-19 14:16 /source/ugctail
[sparkadmin@hadoop3 ~]$ hadoop fs -ls /source/access
Found 1 items
drwxr-xr-x - sparkadmin supergroup 0 2016-10-19 14:16 /source/access/20161019
[sparkadmin@hadoop3 ~]$ hadoop fs -ls /source/access/20161019
Found 1 items
-rw-r--r-- 3 sparkadmin supergroup 29 2016-10-19 14:16 /source/access/20161019/events-.1476857773516.tmp















 7669
7669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









