







一、Map接口
1、Map接口是一个单独的接口,和List接口没什么关系,至少在类的继承关系上是这样。
2、内部哈希
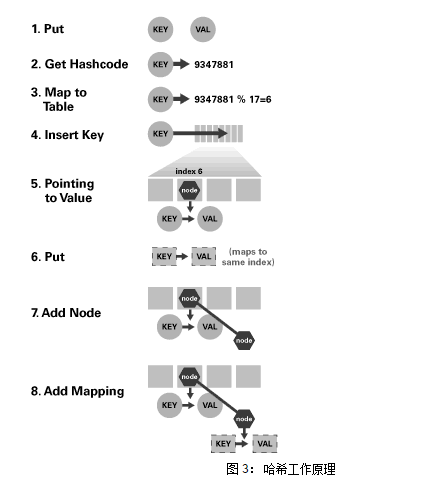
哈希映射结构由一个存储元素的内部数组组成。由于内部采用数组存储,因此必然存在一个用于确定任意键访问数组的索引机制。实际上,该机制需要提供一个小于数组大小的整数索引值。该机制称作哈希函数。在 Java 基于哈希的 Map 中,哈希函数将对象转换为一个适合内部数组的整数。每个对象都包含一个返回整数值的 hashCode() 方法。要将该值映射到数组,只需将其转换为一个正值,然后在将该值除以数组大小后取余数即可。
3、java 1.4之前,hash函数是这样的
4、java 1.4,hash函数是基于 util.concurrent包的int hashvalue = Maths.abs(key.hashCode()) % table.length;5、hash工作原理int hashvalue = (key.hashCode() & 0x7FFFFFFF) % table.length;
6、hash冲突
哈希函数将任意对象映射到一个数组位置,但如果两个不同的键映射到相同的位置,称作Hash冲突。Map 处理这些冲突的方法是在索引位置处插入一个链接列表,并简单地将元素添加到此链接列表
内部的put的可能实现
public Object put(Object key, Object value) { //我们的内部数组是一个 Entry 对象数组 //Entry[] table; //获取哈希码,并映射到一个索引 int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % table.length; //循环遍历位于 table[index] 处的链接列表,以查明 //我们是否拥有此键项 — 如果拥有,则覆盖它 for (Entry e = table[index] ; e != null ; e = e.next) { //必须检查键是否相等,原因是不同的键对象 //可能拥有相同的哈希 if ((e.hash == hash) && e.key.equals(key)) { //这是相同键,覆盖该值 //并从该方法返回 old 值 Object old = e.value; e.value = value; return old; } } //仍然在此处,因此它是一个新键,只需添加一个新 Entry //Entry 对象包含 key 对象、 value 对象、一个整型的 hash、 //和一个指向列表中的下一个 Entry 的 next Entry //创建一个指向上一个列表开头的新 Entry, //并将此新 Entry 插入表中 Entry e = new Entry(hash, key, value, table[index]); table[index] = e; return null; }
二、HashMap
1、HashMap是非线程安全的,HashTable是线程安全的。
2、HashMap的键和值都允许有null值存在,而HashTable则不行。
3、因为线程安全的问题,HashMap效率比HashTable的要高
4、如何让HashMap同步?
Map m = Collections.synchronizeMap(hashMap);
三、HashTable
四、ConcurrentHashMap1、HashTable不允许有null值的存在
2、HashTable中调用put方法时,如果key为null,直接抛出NullPointerException
3、HashTable是同步的,效率很低
4、sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
1、Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
2、ConcurrentHashMap是线程安全的HashMap的实现。ConcurrentHashMap是实现ConcurrentMap接口,ConcurrentMap接口是继承Map接口
public interface ConcurrentMap<K, V> extends Map<K, V>
五、HashTable和ConcurrentHashMap的同步区别3、如何实现同步?采用了多个锁。
1、HashTable的同步是使用synchronize关键字
2、ConcurrentHashMap使用锁机制
六、ConcurrentSkipListMap锁分离 (Lock Stripping)
HashTable是一个过时的容器类,通过使用synchronized来保证线程安全,在线程竞争激烈的情况下HashTable的效率非常低下。原因是所有访问HashTable的线程都必须竞争同一把锁。那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。
ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。同样当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable
ConcurrentSkipListMap继承AbstractMap,实现ConcurrentMap
1、SkipList跳表 参考这里
Skip List是一种随机化的数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表(因此得名)。所有操作都以对数随机化的时间进行。Skip List可以很好解决有序链表查找特定值的困难。
2、ConcurrentSkipListMap
ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够在O(log(n))时间内完成查找、插入、删除操作。调用ConcurrentSkipListMap的size时,由于多个线程可以同时对映射表进行操作,所以映射表需要遍历整个链表才能返回元素个数,这个操作是个O(log(n))的操作。















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









