







Scrapy
scrapy组件

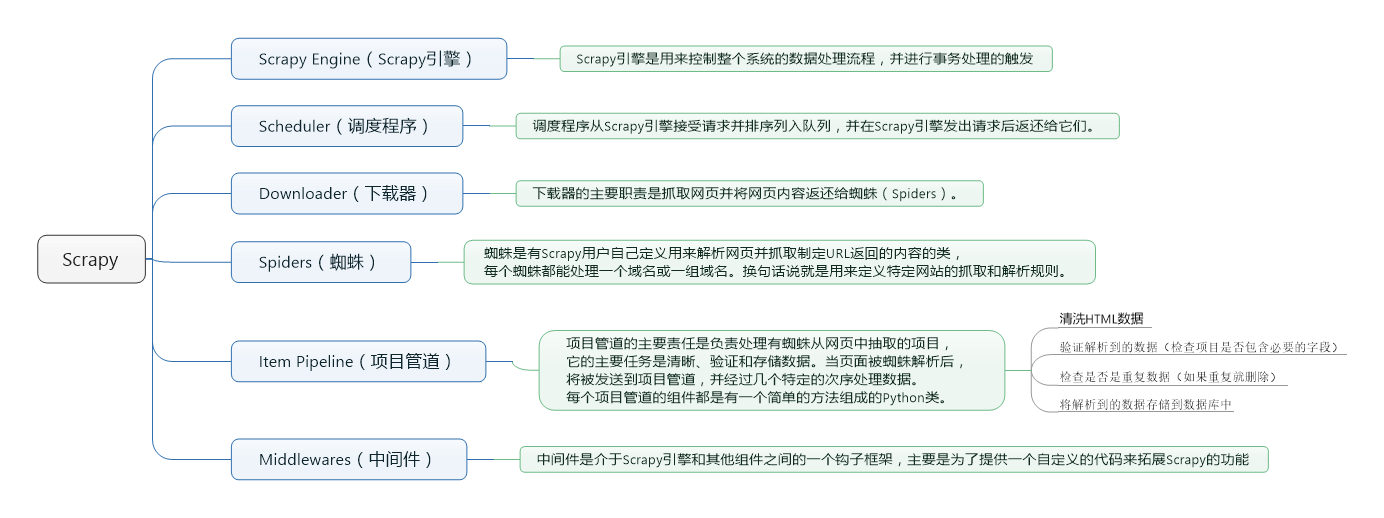
数据处理流程
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
- 引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
- 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
- 引擎从调度那获取接下来进行爬取的页面。
- 调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
- 当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
- 引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
- 蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
- 引擎将抓取到的项目项目管道,并向调度发送请求。
- 系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系
示例
创建一个scrapy项目
scrapy startproject mytest即可生成代码的基本框架
scrapy 的基本项目结构
F:.
│ items.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└─spiders
__init__.py
items.py
Items.py定义需要抓取并需要后期处理的数据。Item是用来装载抓取数据的容器,和Java里的实体类(Entity)比较像.里面是我们想要的数据的内容pipelines.py
pipeline.py用于存放执行后期数据处理的功能,从而使得数据的爬取和处理分开。settings.py
settings.py文件配置Scrapy,从而修改user-agent,设定爬取时间间隔,设置代理,配置各种中间件等等。
- Spider.py
Spider是用户自己编写的类,用来从一个域(或域组)中抓取信息。里面要定义用于下载的URL列表、跟踪链接的方案、解析网页内容的方式,以此来提取items中我们想要的数据。
要建立一个Spider,继承scrapy.Spider,并确定三个强制的属性:
- name:爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
- start_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
- parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL。
启动爬虫
scrapy crawl mytest 数据的解析
在Scrapy里,使用一种叫做 XPath selectors的机制,它基于 XPath表达式。
/html/head/title选择HTML文档元素下面的 标签。
/html/head/title/text() 选择前面提到的 元素下面的文本内容
//td: 选择所有 元素
//div[@class="mine"] 选择所有包含 class=”mine” 属性的div 标签元素
为了方便使用XPaths,Scrapy提供XPathSelector 类,有两种可以选择,HtmlXPathSelector(HTML数据解析)和XmlXPathSelector(XML数据解析)。
数据存储在items中
Spiders将其抓取的数据存放到Item对象中
# items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy import Field,Item
class MytestItem(Item):
title = Field()
movieInfo = Field()
star = Field()
quote = Field()
# mytest.py
__author__ = 'Nicholas'
import scrapy
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from mytest.items import MytestItem
from scrapy.http import Request
class MyTest(scrapy.Spider):
name="mytest"
redis_key = 'douban:start_urls'
start_urls = ['http://movie.douban.com/top250']
url = 'http://movie.douban.com/top250'
def parse(self, response):
item = MytestItem()
selector = Selector(response)
Movies = selector.xpath('//div[@class="info"]')
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
fullTitle = ''
for each in title:
fullTitle += each
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span/em/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
if quote:
quote = quote[0]
else:
quote = ''
item['title'] = fullTitle
item['movieInfo'] = ';'.join(movieInfo)
item['star'] = star
item['quote'] = quote
yield item
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextLink:
nextLink = nextLink[0]
print nextLink
yield Request(self.url + nextLink,callback=self.parse)数据持久化
Pipeline.py
scrapy crawl mytest -o items.json -t json #导出json
存储到mongod
首先在setting.py中配置
ITEM_PIPELINES={'mytest.pipelines.MytestPipeline':300}
# pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem
class MytestPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(host='127.0.0.1',port=27017)
db = connection.doubanmovie
self.collect = db.douban
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing %s of blogpost from %s" %(data, item['url']))
if valid:
new_moive=[{
"title":item['title'],
"star":item['star'],
"quote":item['quote'],
"movieInfo":item['movieInfo'].strip()
}]
self.collect.insert(new_moive)
return itemhttp://movie.douban.com/top250
# myspider.py
__author__ = 'Nicholas'
import scrapy
from scrapy.http import Request
from scrapy.selector import Selector
from mytest.items import MytestItem
class MyTest(scrapy.Spider):
name = "mytest"
start_urls = ['http://movie.douban.com/top250']
url = 'http://movie.douban.com/top250'
def parse(self, response):
item = MytestItem()
selector = Selector(response)
Movies = selector.xpath('//div[@class="info"]')
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
fullTitle = ''
for each in title:
fullTitle += each
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span/em/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
if quote:
quote = quote[0]
else:
quote = ''
item['title'] = fullTitle
item['movieInfo'] = ';'.join(movieInfo)
item['star'] = star
item['quote'] = quote
yield item
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
if nextLink:
nextLink = nextLink[0]
print nextLink
yield Request(self.url + nextLink,callback=self.parse)
# items.py
import scrapy
from scrapy import Field,Item
class MytestItem(Item):
title = Field()
movieInfo = Field()
star = Field()
quote = Field()
# main.py
__author__ = 'Nicholas'
from scrapy import cmdline
cmdline.execute("scrapy crawl mytest".split())















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









