







1. On-policy与Off-policy
On-policy:学习到的agent既是与环境互动的policy,也是我们需要学习的agent。
Off-policy:学习到的agent和与环境互动的policy是两个不同的agent
1.1 为什么会从On-policy到Off-policy?
在这篇文章中提到的算法是On-policy的,其所学习的agent在每一轮游戏完成之后,因为参数改变了,所以在下一轮中可能采取的行动也不同了,因此需要重新resample data。现在的目标是,专门用一个agent去sample data,另一个agent也就是我们需要训练的agent负责更新自己的参数,这样的话,数据就能够重复使用,不用每次都resample,可以节省时间。
1.1.1 Important Sampling
先介绍一种resample data 的方法,如果自变量
x
x
x服从一种分布,这种分布记为
p
p
p,先在要求关于
x
x
x的函数
f
(
x
)
f(x)
f(x)的期望值,有一种方法可以表示成:
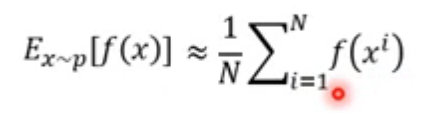
但是我们现在由于种种原因,只能从一个**分布
q
q
q**中取sample data,但是
q
q
q分布毕竟不是
p
p
p分布,那么,为了得到相同的
E
x
∼
p
[
f
(
x
)
]
E_{x\sim p}[f(x)]
Ex∼p[f(x)],我们需要将从
q
q
q中得到的sample data进行一个修正。
于是乎:
E
x
∼
p
[
f
(
x
)
]
=
∫
f
(
x
)
q
(
x
)
d
x
=
∫
f
(
x
)
p
(
x
)
q
(
x
)
q
(
x
)
d
x
=
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
\begin{aligned} E_{x\sim p}[f(x)] &= \int f(x)q(x) dx \\ &= \int f(x)\frac{p(x)}{q(x)}q(x)dx \\ &=E_{x\sim q}[f(x)\frac{p(x)}{q(x)}] \end{aligned}
Ex∼p[f(x)]=∫f(x)q(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
但是,仅仅是期望相同时不够的,从
p
p
p中resample 的数据,与从
q
q
q中resample的数据在方差上是有差的:
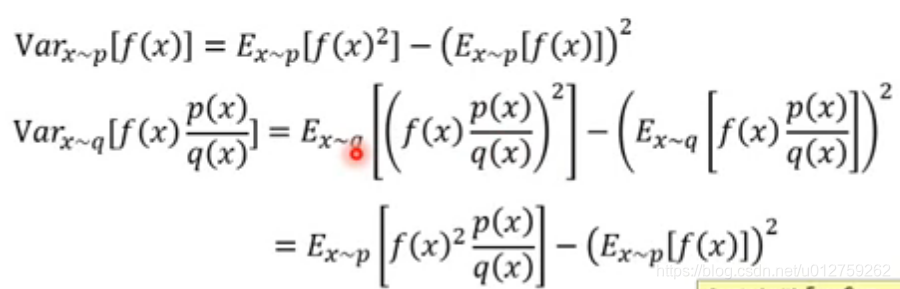
所以,
p
p
p与
q
q
q的差距不能太大,这里举了一个例子:
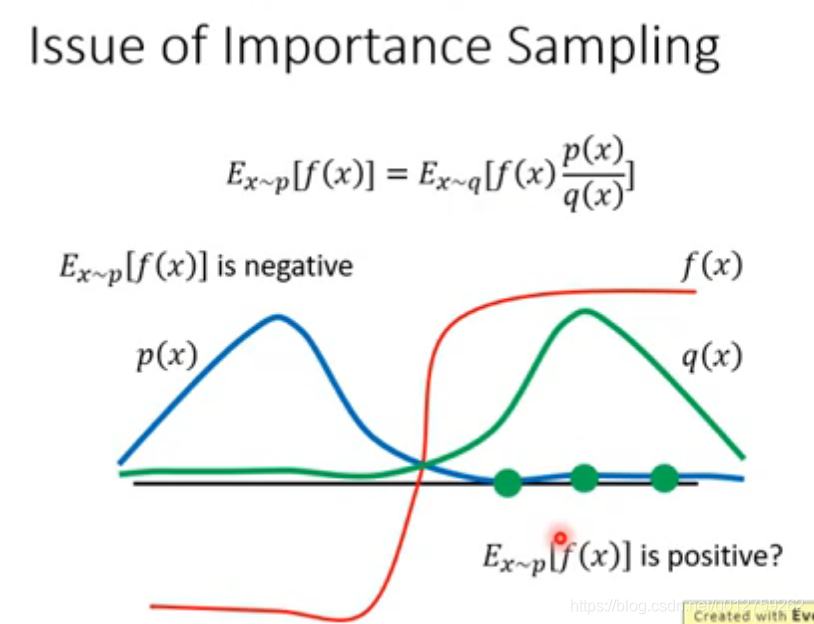
q
q
q的resample次数不够多,导致求出的期望可能是负的,但是实际上应该是正的,参见
p
p
p的概率分布图。因此,需要尽可能多的sample 数据。
1.1.2 Important Sampling 与 Off-policy
借助important sampling的思想,我们将agent分成两个,一个负责与环境交互,该agent参数为
θ
′
\theta'
θ′;另一个是我们需要学习的agent,其参数为
θ
\theta
θ。

下面,将优化的函数抽象表达一下,将
R
(
τ
n
)
−
b
R(\tau^n)-b
R(τn)−b抽象表达为
A
θ
(
s
t
,
a
t
)
A^{\theta}(s_t, a_t)
Aθ(st,at):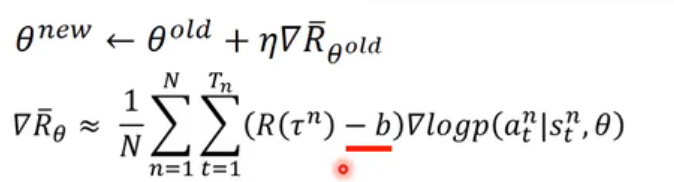
与important sampling相结合,就有

注意,其中的
A
θ
(
s
t
,
a
t
)
A^{\theta}(s_t, a_t)
Aθ(st,at)代表的意义其实是:学习agent与环境交互之后得到的累积奖励,但是,在off-policy中,真正与环境交互的其实是
θ
′
\theta'
θ′的agent。
接下来,将两个agent的联合分布进行拆解,写成如下形式:
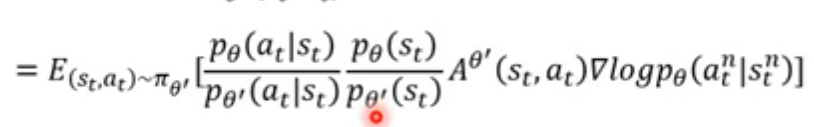
在此进行一个假设:两个agent看到的状态都是一样的,所以:
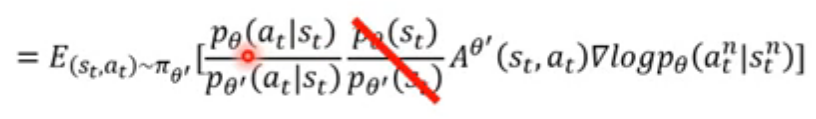
考虑公式:
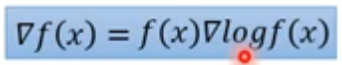
那么,目标函数变为
=
E
(
s
t
,
a
t
)
∼
π
θ
[
(
p
θ
(
a
t
n
∣
s
t
n
)
)
(
p
θ
′
(
a
t
n
∣
s
t
n
)
)
A
θ
(
s
t
,
a
t
)
▽
log
(
p
θ
(
a
t
n
∣
s
t
n
)
)
]
=
E
(
s
t
,
a
t
)
∼
π
θ
[
(
▽
p
θ
(
a
t
n
∣
s
t
n
)
)
(
p
θ
′
(
a
t
n
∣
s
t
n
)
)
A
θ
(
s
t
,
a
t
)
]
\begin{aligned} =&E_{(s_t,a_t)\sim \pi_{\theta}}[ \frac{(p_{\theta}(a^n_t|s^n_t))}{(p_{\theta'}(a^n_t|s^n_t))}A^{\theta}(s_t,a_t) \bigtriangledown \log(p_{\theta}(a^n_t|s^n_t))] \\ =&E_{(s_t,a_t)\sim \pi_{\theta}}[ \frac{(\bigtriangledown p_{\theta}(a^n_t|s^n_t))}{(p_{\theta'}(a^n_t|s^n_t))}A^{\theta}(s_t,a_t) ] \end{aligned}
==E(st,at)∼πθ[(pθ′(atn∣stn))(pθ(atn∣stn))Aθ(st,at)▽log(pθ(atn∣stn))]E(st,at)∼πθ[(pθ′(atn∣stn))(▽pθ(atn∣stn))Aθ(st,at)]
还原回求导之前的样子,所以,得到了一个新的目标函数,也就是我们需要最大化的那个参数 :
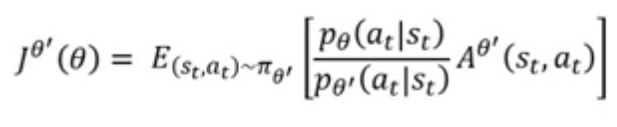
由于,在important sampling中存在一个问题,就是
p
p
p与
q
q
q分布不能差太多,因此,PPO加上了一个限制:

附加项
β
K
L
(
θ
,
θ
′
)
\beta KL(\theta, \theta')
βKL(θ,θ′)的目的就是衡量两套参数有多像,不是参数上的距离,是代入一个state,输出action之间的差距。不最小化两套参数的原因是因为:不同的参数在面对相同场景的时候可能产生一样的action,但是相近的参数在面对同样的场景是,输出的action可能有很大差距。
具体算法为:

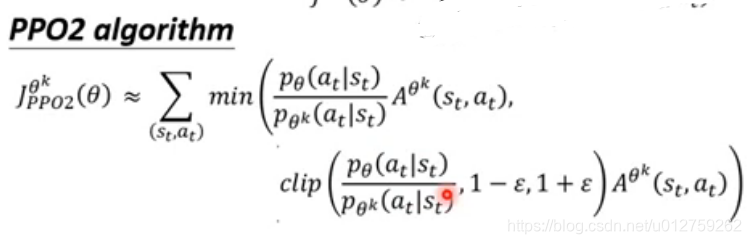
在上式中,有两个函数,
min
\min
min取两项中的小值,
c
l
i
p
clip
clip裁剪,
p
θ
(
a
t
∣
s
t
)
p
θ
k
(
a
t
∣
s
t
)
\frac{p_{\theta}(a_t|s_t)}{p^k_{\theta}(a_t|s_t)}
pθk(at∣st)pθ(at∣st)的值不能超过后面
1
+
ϵ
1+\epsilon
1+ϵ和
1
−
ϵ
1-\epsilon
1−ϵ,否则就去边界值作为输出。
下图表示了上述函数的取值范围:
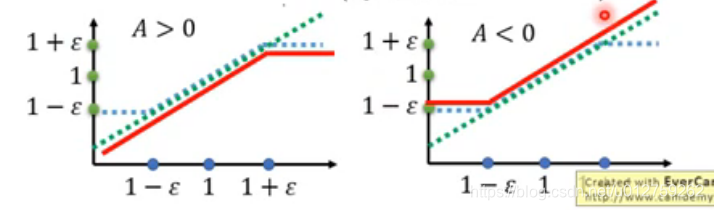
在上图中,横轴代表的意义是
p
θ
(
a
t
∣
s
t
)
p
θ
k
(
a
t
∣
s
t
)
\frac{p_{\theta}(a_t|s_t)}{p^k_{\theta}(a_t|s_t)}
pθk(at∣st)pθ(at∣st),如果reward是好的,也就是
A
>
0
A>0
A>0,就需要此时整个目标函数的取值就是红色的线,增加state和action的匹配概率
p
θ
(
a
t
∣
s
t
)
p_{\theta}(a_t|s_t)
pθ(at∣st),但是不能超过边界。














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









