







注:本文中所有公式和思路来自于邹博先生的《机器学习升级版》,我只是为了加深记忆和理解写的本文。
树是一种极其重要的数据结构,像二叉树、红黑树等等,本要介绍的这种树是机器学习中的一种树,用来做分类或者回归的决策树。
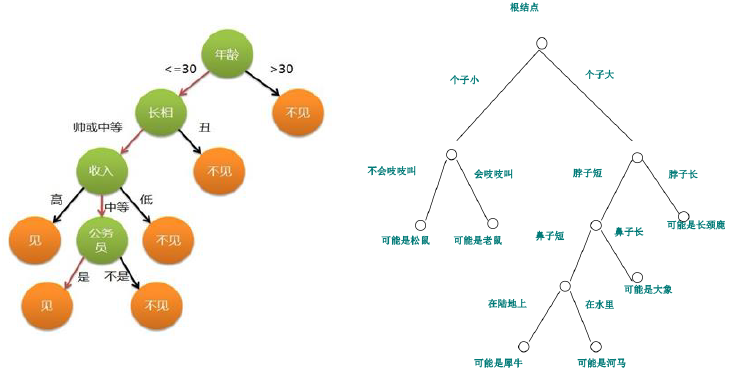
上图就是两颗决策树,其中的每个内部结点表示在一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表着一种类别。
决策树是以实例为基础的归纳学习,决策树学习是采用自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子结点处熵值为0,此时每个叶子结点上的实例都属于同一类。
决策树学习算法最大的优点是,他可以自学习,在学习过程中,不需要使用者了解过多的背景知识、领域知识,只需要对训练实例进行较好的标注就可以自学习了。
建立决策树的关键在于当前状态下选择哪一个属性作为分类依据,根据不同的目标函数,有三种主要的算法:
ID3(Iterative Dichotomiser)
C4.5
CART(Classification And Regression Tree)
后边我们将一一介绍三种算法,现在先来了解几个概念。
经验熵:当熵和条件熵中的概率由数据统计(特别是极大似然估计)得到时,所对应的熵和条件熵分别成为经验熵、经验条件熵。
信息增益:表示得知特征A的信息而是的类X的信息的不确定性减少程度。可以如下表示:
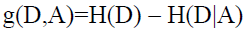
当然由公式也可以看出,其实就是D与A的互信息。
ID3
首先我们先约定记号:
设训练数据集为D,|D|为样本个数。
设有K个分类Ck, k=1,2...K,|Ck|表示属于Ck分类的样本个数,因此有:
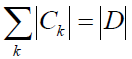
设特征A有n个不同的取值{a1,a2 ... an},根据特征A的取值将D划分为n个子集D1,D2 ... Dn,|Di|为Di子集中的样本个数,因此有:
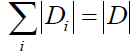
记子集Di中属于类Ck的样本的集合为Dik,|Dik|表示Dik的样本个数。
计算数据集D的经验熵:
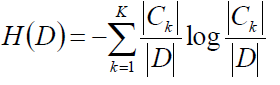
接下来就要求经验条件熵了,可以遍历A中的所有特征,计算所有特征A的信息增益,选择信息增益最大的特征作为当前的分裂特征:
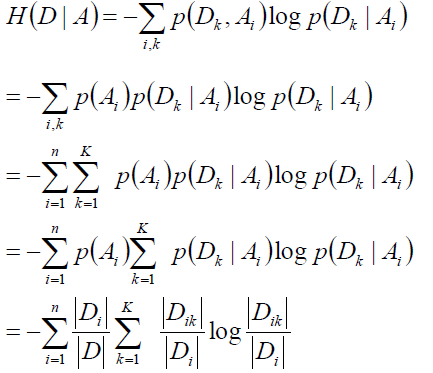
理解这块的关键我个人觉得有两点:第一时要理解决策树每一步是怎么得到的,可以手动做一棵来加深理解,第二点就是要记住记号的含义是干嘛的。这就时ID 3,简单吧。
C 4.5
我们在ID 3的算法中不是求了信息增益么,只要再除以一个特征的经验熵就得到信息增益率:
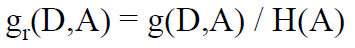
这就是C4.5,仅此而已,那到底为啥呢?除以这么个特征的经验熵有道理么?
我们假设有1000个样本,有一个特征,这个特征有1000个判别级别,这一个特征正好就可以将所有的样本划分完成,直接分成了1000个子节点,那么其他的特征根本没有机会使用,因为这个特征直接完全划分完了,但是这棵树过于矮胖了,再来第1001个样本就不知道咋分了,所以我们除上这个特征的经验熵,就可以防止这种情况嘛,仅此而已。
Gini系数
由于学科的不同,基尼系数有两种定义方式,我们在做的时候如果选定了这一种定义方式,就一条路走到黑就可以了,机器学习中的定义是这样的:
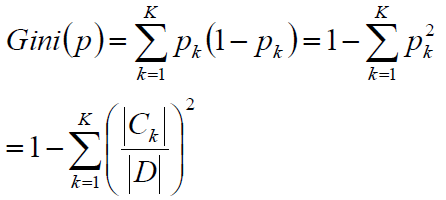
其实Gini系数可以理解为近似熵的一半:
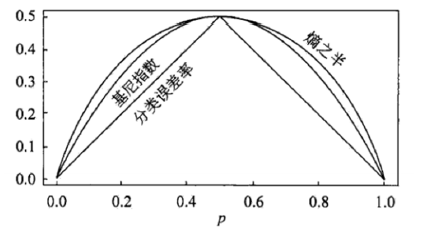
当然了,推导过程我也不太清楚,咱比较务实,不深究最最底层的数学,那些有数学家在做,另外基尼系数的第二定义这里就不解释了,我觉得会一种是比较好的,起码不容易混淆。
三种算法介绍完了,那么我们怎么去评价一棵决策树呢?
我们假定样本的总类别为K个,对于决策树的某一个叶节点,假定该叶节点含有样本数目为n,其中第k类的样本数目为nk:
(1): 若某类样本nj=n,而n1=n2=n3=...=nj-1=nj+1=...=nk=0,则称该结点为纯结点。
(2): 若各个分类样本数目一样多n1=n2=...=nk=n/K,则称样本为均结点。
纯结点的熵H = 0最小,均结点最大 H = lnK
那么我们就可以对所有的熵求和,该值越小说明分类越精确,由于各个结点的包含的样本数目不同,有的1000,有的1个,所以我们可以对叶结点加权。
评价函数:
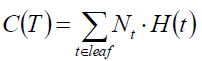
由于改值我们希望越小越好,所以又被称为loss function。
那么如果我们只要沿着特征做,基本上是一定可以将所有样本的都分的,只要树的深度够深,那么岂不是过拟合了?
防止过拟合有两种方式:剪枝、随机森林
剪枝
剪枝分为预剪枝和后剪枝,这里就只介绍后剪枝。
剪枝的总体思路:由完全树T0开始,剪枝部分结点得到T1,在此剪枝部分结点得到T2....直到仅剩下树根Tk,再验证数据集上对这个k棵树分别评价,选择损失函数最小的树Tα。
那么怎么剪呢?
我们知道原损失函数为:
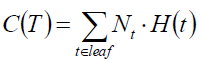
叶结点越多树也就越复杂,损失越大,那么我们就可以对原损失函数做修正:
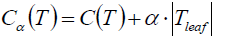
我们假定当前对以r为根的子树剪枝,剪枝后只保留r本身而删除所有的叶子。
那么我们可以看看剪枝前后的损失函数:
剪枝后:
剪枝前:
令二者相等求得:
α就称为r结点的剪枝系数。注意:仅仅是r结点的,其他结点还要另算。
我们只需将上边的算法在所有结点上迭代一次,选择一个损失函数最好的即可。
到此决策树就介绍完了,后边将会介绍Bagging和随机森林。














 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









