







- 在IO型服务中,假设服务A依赖服务B和服务C,而B服务和C服务有可能继续依赖其他的服务,
- 继续下去会使得调用链路过长,技术上称1->N扇出。
- 如下图
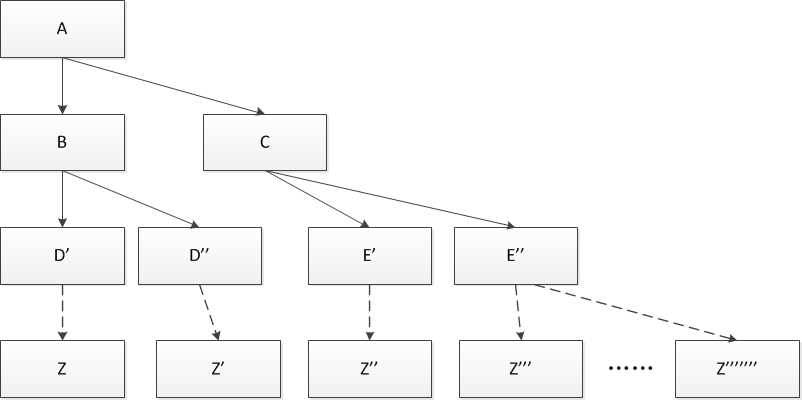
如果在A的链路上某个或几个被调用的子服务不可用或延迟较高,则会导致调用A服务的请求被堵住。
堵住的请求会消耗占用掉系统的线程、io等资源,当该类请求越来越多,占用的计算机资源越来越多的时候,会导致系统瓶颈出现,造成其他的请求同样不可用,最终导致业务系统崩溃,又称:雪崩效应。
正常情况下的访问
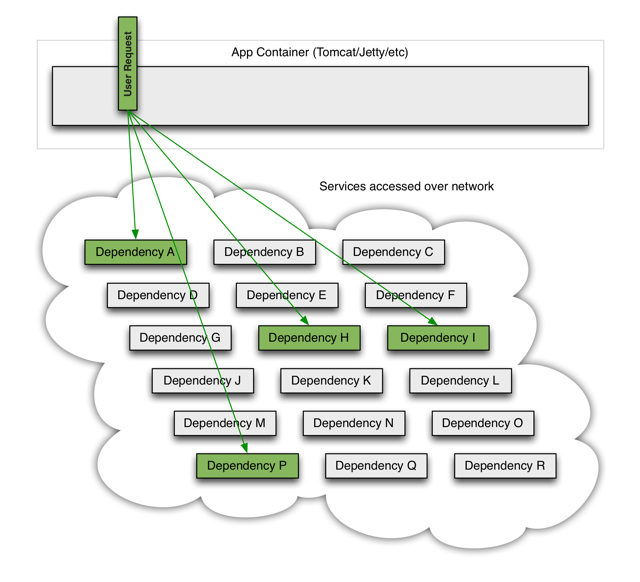
用户请求的多个服务(A,H,I,P)均能正常访问并返回。
发生阻塞时
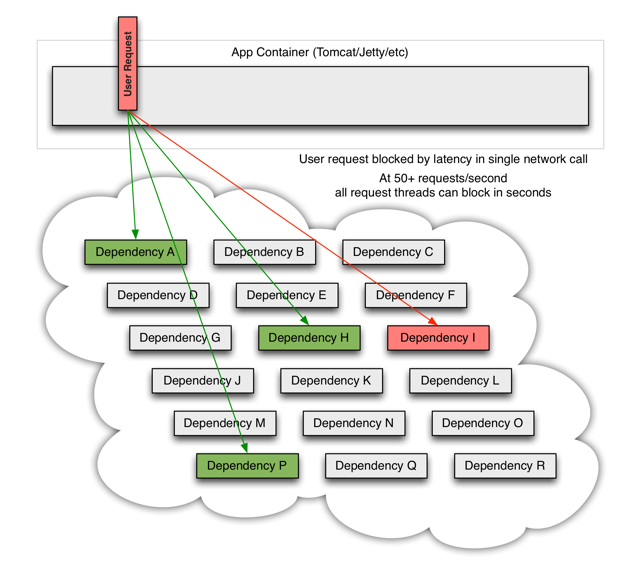
当请求的服务中出现无法访问、异常、超时等问题时(图中的I),那么用户的请求将会被阻塞。
雪崩发生时
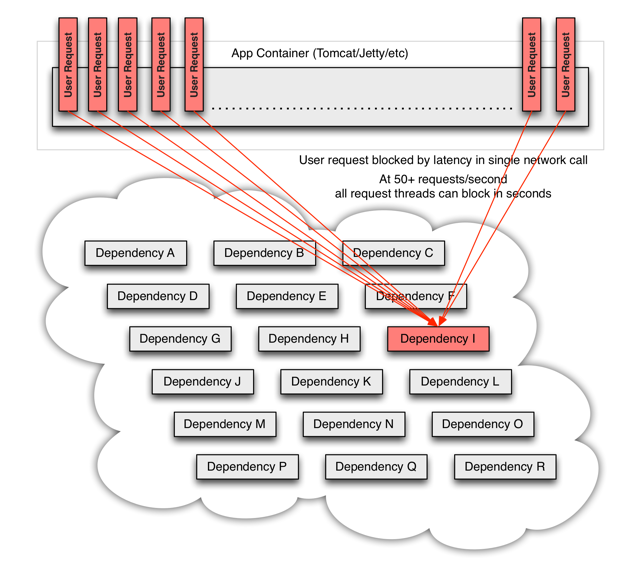
如果多个用户的请求中,都存在无法访问的服务,那么他们都将陷入阻塞的状态中。
举例来说,一个汽车生产线,生产不同的汽车,需要使用不同的零件,如果某个零件因为种种原因无法使用,那么就会造成整台车无法装配,陷入等待零件的状态,直到零件到位,才能继续组装。
此时如果有很多个车型都需要这个零件,那么整个工厂都将陷入等待的状态,导致所有生产都陷入瘫痪。一个零件的波及范围不断扩大。
造成雪崩效应的原因
1.硬件故障
2.负载过大(如:抢红包,双十一)
3.代码问题
Hystrix就是为了解决上述问题。
Hystrix提供了熔断模式和隔离模式来解决或者缓解雪崩效应。
这两种方案都属于阻塞发生之后的应对策略,而非预防性策略(例如限流模式)。
Hystrix是在服务访问失败时降低阻塞的影响范围,避免整个服务被拖垮。















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









